【学习笔记】Manacher算法
一、引入
Manacher算法是用来求最长回文子串的算法,时间复杂度O(n)。
回文子串指的是''aacaa'',''noon'',这种正着反着读都一样的。
二、构造字符串
朴素的求法是O(n^2),以某个字符为中心,向左右扩展,如下图所示。
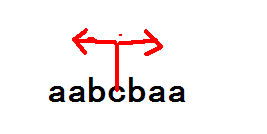
对于长度为奇数的字符串是可以枚举回文串的中心的,那么偶数的呢?
我们在字符的空里插入其他不在字符串中出现过的字符,如’#‘。
如字符串acca,变为$a#c#c#a#,为了避免出现错误,我们不让首字符等于尾字符。
所以在开头插入的字符为‘$’。
三、引进Len数组
假设输入的字符串为s。
Len[i]表示以i为中心的最长的回文半径的长度(包括i)。
如果以str[i]为中心的回文串的范围为[l,r],那么Len[i]=r-i+1。
Len数组的性质,Len[i]-1为该回文串在原串s中的长度。
证明:2*Len[i]-1表示带’#‘的回文串的长度,’#‘的个数一共有Len[i]个,那么回文串
的长度就是2*Len[i]-1-Len[i]=Len[i]-1。
如图所示:
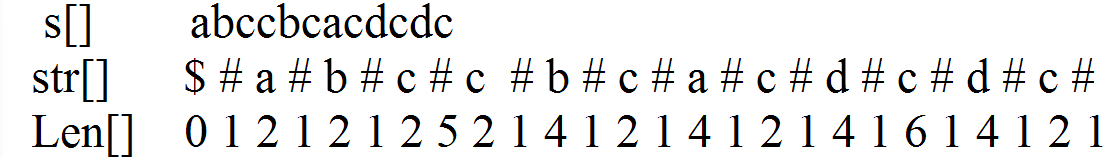
还要介绍几个变量的意义:现在从左到右扫字符串计算Len数组,mx表示目前为止的回文串能覆盖的最右端点,
id表示最后更新mx的i的位置。
四、计算Len数组
由于回文串有对称的特点,那么对于Len数组的求法,我们尽量的抄之前与该字符对称字符的Len[]。
另外,我们约定mx是开区间的,也就是说覆盖的最右端点为mx-1,这是对于下面的Manacher代码模板来约定的。
怎样通过‘抄’来计算Len数组呢?
假设现在正在计算Len[i]的值。
A:当i<mx。
(1):当Len[j]<=mx-i时,那么以i为中心的回文串至少和以j为中心的回文串相等。
也就是Len[i]>=Len[j],所以我们先直接抄过Len[j]赋值给Len[i],然后再暴力,看能否再扩展。
更新mx和id。
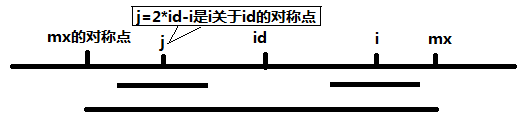
(2):当Len[j]>mx-i时,那么i+Len[j]已经大于mx,我们对于mx向右的地方是未知的,
所以不能直接把Len[j]抄过来,只能让Len[i]先等于mx-i,这是一定对的,然后在暴力扩展。
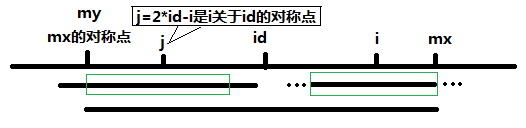
B:当i>=mx,也就是说Len[i]没有办法从j这里抄过来,需要暴力计算。
五、模板
#include<cstdio>
#include<cstring>
#include<iostream>
using namespace std;
const int maxn=1e6+;
char s[maxn*],str[maxn*];
int Len[maxn*],len; void getstr()
{
int k=;
str[k++]='$';
for(int i=;i<len;i++)
str[k++]='#',
str[k++]=s[i];
str[k++]='#';
len=k;
}
void Manacher()
{
getstr();
int mx=,id;
for(int i=;i<len;i++)
{
if(mx>i) Len[i]=min(Len[*id-i],mx-i);
else Len[i]=;
while(str[i+Len[i]]==str[i-Len[i]])
Len[i]++;
if(Len[i]+i>mx)
mx=Len[i]+i,id=i;
}
}
int main()
{
int n;
scanf("%d",&n);
for(int i=;i<=n;i++)
{
scanf("%s",&s);
len=strlen(s);
Manacher();
int ans=;
for(int i=;i<len;i++) ans=max(ans,Len[i]);
printf("%d\n",ans-);
}
return ;
}
模板需要注意的就是数组的大小了。
六、习题
BZOJ 2342: [Shoi2011]双倍回文
[BZOJ2565] 最长双回文串
[BZOJ3790] 神奇项链
[BZOJ2160]拉拉队排练
【学习笔记】Manacher算法的更多相关文章
- 学习笔记 - Manacher算法
Manacher算法 - 学习笔记 是从最近Codeforces的一场比赛了解到这个算法的~ 非常新奇,毕竟是第一次听说 \(O(n)\) 的回文串算法 我在 vjudge 上开了一个[练习],有兴趣 ...
- [ML学习笔记] XGBoost算法
[ML学习笔记] XGBoost算法 回归树 决策树可用于分类和回归,分类的结果是离散值(类别),回归的结果是连续值(数值),但本质都是特征(feature)到结果/标签(label)之间的映射. 这 ...
- 学习笔记——EM算法
EM算法是一种迭代算法,用于含有隐变量(hidden variable)的概率模型参数的极大似然估计,或极大后验概率估计.EM算法的每次迭代由两步组成:E步,求期望(expectation):M步,求 ...
- 数据挖掘学习笔记--AdaBoost算法(一)
声明: 这篇笔记是自己对AdaBoost原理的一些理解,如果有错,还望指正,俯谢- 背景: AdaBoost算法,这个算法思路简单,但是论文真是各种晦涩啊-,以下是自己看了A Short Introd ...
- 学习笔记-KMP算法
按照学习计划和TimeMachine学长的推荐,学习了一下KMP算法. 昨晚晚自习下课前粗略的看了看,发现根本理解不了高端的next数组啊有木有,不过好在在今天系统的学习了之后感觉是有很大提升的了,起 ...
- Java学习笔记——排序算法之快速排序
会当凌绝顶,一览众山小. --望岳 如果说有哪个排序算法不能不会,那就是快速排序(Quick Sort)了 快速排序简单而高效,是最适合学习的进阶排序算法. 直接上代码: public class Q ...
- Java学习笔记——排序算法之进阶排序(堆排序与分治并归排序)
春蚕到死丝方尽,蜡炬成灰泪始干 --无题 这里介绍两个比较难的算法: 1.堆排序 2.分治并归排序 先说堆. 这里请大家先自行了解完全二叉树的数据结构. 堆是完全二叉树.大顶堆是在堆中,任意双亲值都大 ...
- Java学习笔记——排序算法之希尔排序(Shell Sort)
落日楼头,断鸿声里,江南游子.把吴钩看了,栏杆拍遍,无人会,登临意. --水龙吟·登建康赏心亭 希尔算法是希尔(D.L.Shell)于1959年提出的一种排序算法.是第一个时间复杂度突破O(n²)的算 ...
- 算法笔记--manacher算法
参考:https://www.cnblogs.com/grandyang/p/4475985.html#undefined 模板: ; int p[N]; string manacher(string ...
- 学习笔记——SM2算法原理及实现
RSA算法的危机在于其存在亚指数算法,对ECC算法而言一般没有亚指数攻击算法 SM2椭圆曲线公钥密码算法:我国自主知识产权的商用密码算法,是ECC(Elliptic Curve Cryptosyste ...
随机推荐
- jQuery垂直缩略图相册插件 支持鼠标滑动翻页
在线演示 本地下载
- 差看windows上进程及线程
转自:http://blog.csdn.net/swgsunhj/article/details/29552027 下载process exlporer: http://technet.microso ...
- NSwag Tutorial: Integrate the NSwag toolchain into your ASP.NET Web API project
https://blog.rsuter.com/nswag-tutorial-integrate-the-nswag-toolchain-into-your-asp-net-web-api-proje ...
- linux 终端分屏命令
比如:某文件夹下有文件:vector.cc, substr.cc 1.使用vim命令打开任意一个文件:vim vector.cc打开第一个文件.如下图所示: 2.按:"Esc"键 ...
- XML 存储文档
package com.kpsh.myself; import java.io.File;import java.io.FileWriter; import org.dom4j.Document;im ...
- JDK__下载地址
1. http://www.oracle.com/technetwork/java/archive-139210.html ZC: 貌似 从JDK7开始,有for ARM的版本,类似 : “Linux ...
- Apache顶级项目 Calcite使用介绍
什么是Calcite Apache Calcite是一个动态数据管理框架,它具备很多典型数据库管理系统的功能,比如SQL解析.SQL校验.SQL查询优化.SQL生成以及数据连接查询等,但是又省略了一些 ...
- 一些官方的github地址
阿里巴巴开源github地址:https://github.com/alibaba 腾讯开源github地址:https://github.com/Tencent 奇虎360github地址:http ...
- 带你彻底明白 Android Studio 打包混淆
前言 在使用Android Studio混淆打包时,该IDE自身集成了Java语言的ProGuard作为压缩,优化和混淆工具,配合Gradle构建工具使用很简单.只需要在工程应用目录的gradle文件 ...
- cassandra 之 集群部署
其实关于部署没啥好说的,修改config/cassandra.yaml以下几个地方就可以了 cluster_name: 'cluster_cassandra' data_file_directorie ...