TaskScheduler内幕天机解密:Spark shell案例运行日志详解、TaskScheduler和SchedulerBackend、FIFO与FAIR、Task运行时本地性算法详解等
本课主题
- 通过 Spark-shell 窥探程序运行时的状况
- TaskScheduler 与 SchedulerBackend 之间的关系
- FIFO 与 FAIR 两种调度模式彻底解密
- Task 数据本地性资源分配源码实现
引言
TaskScheduler 是 Spark 整个调度的底层调度器,底层调度器是负责具体 Task 本身的运行的,所以豪无疑问的是一个至关重要的内容。希望这篇文章能为读者带出以下的启发:
- 了解 程序运行时具体创建的实例对象
- 了解 TaskScheduler 与 SchedulerBackend 之间的关系
- 了解 FIFO 与 FAIR 两种调度模式彻底解密
- 了解 Task 数据本地性资源分配源码实现
通过 Spark-shell 窥探程序运行时的状况
首先通过启动一个 Spark-shell 来观察具体 TaskScheduler 实例的情况,在这个过程中我们可以看见上一节所讲的 SparkDeploySchedulerBackend 和 AppClient 的身影,这是因为 Spark-shell 本身也是一个应用程序。当我们启动 Spark-shell 本身的时候命令终端反馈回来的主要是 ClientEndpoint 和 SparkDeploySchedulerBackend,这是因为此时还没有任何 Job 的触发,这是启动 Application 本身而已,所以主要就是实例化 SparkContext 并注册当前的应用程序给 Master 且从集群中获得 ExecutorBackend 的计算资源。(详情可以参考Spark天堂之门解密的博客)。
[下图是 SparkShell 启动后打印的日志信息]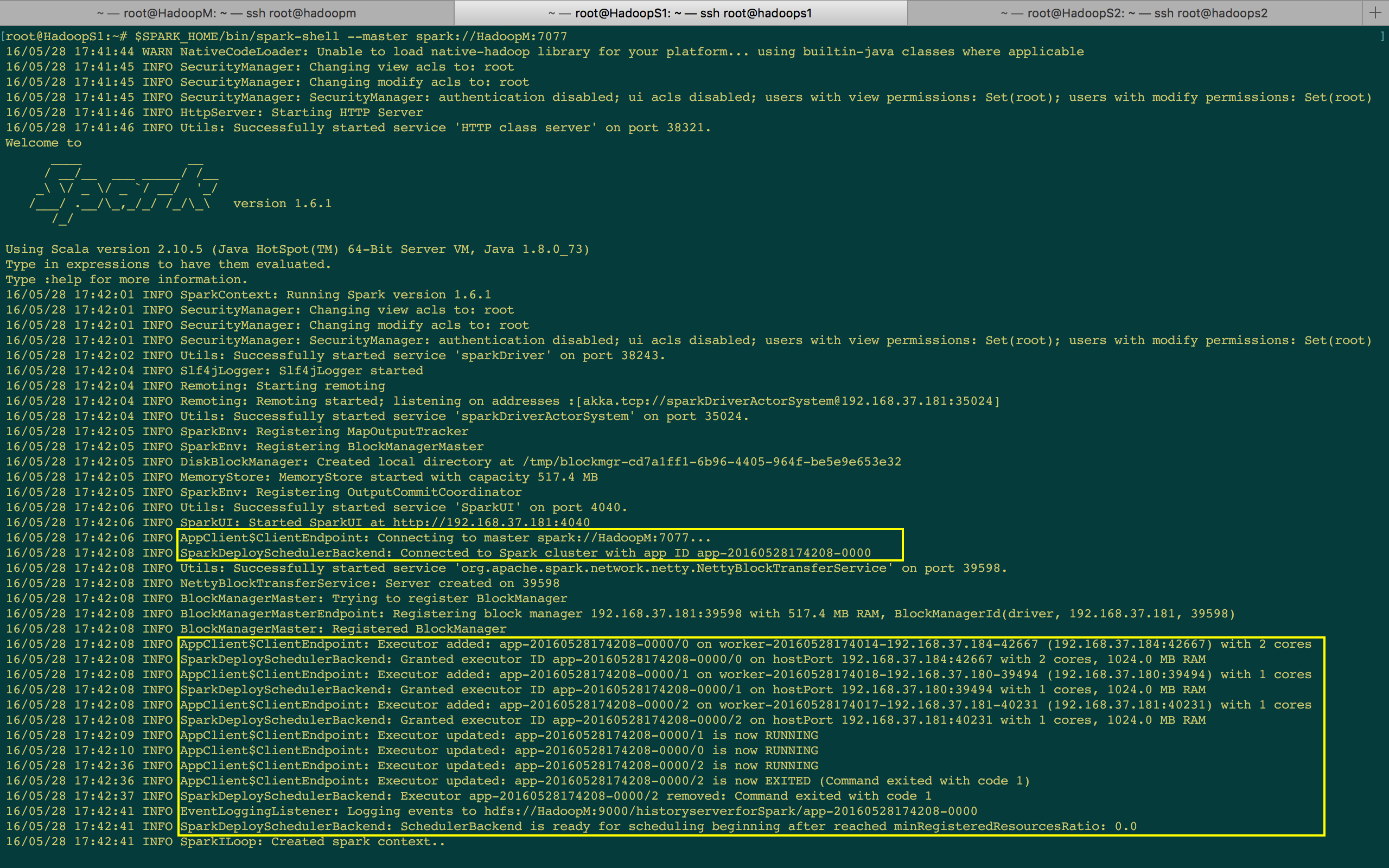
上图出现了 AppClient 和 ClientEndPoint,你可以很清晰的看见 ClientEndPoint 注册给 Master (e.g. ClientEndPoint connecting to master spark://HadoopM:7077)。下一行有 SparkDeploySchedulerBackend,接著几行日志是 AppClient Executor Added;这几行日志证明了程序在启动并注册时,是交给 SparkDeploySchedulerBackend 来管理 Executor,中间过程也会创建BlockManagerMaster。
SchedulerBackend 在最后表示自己已经准备好了 (e.g. SchedulaerBackend is ready for scheduling beginning after reached minRegisteredResourcesRatio),这说明一件事情,在创建 SparkContext 之前会先创建很多其他功能的实例对象,那些 AppClient、SparkDeploySchedulerBackend、BlockManagerMaster 都是随著 SparkContext 创建而创建的!!!
[下图是 SparkShell 启动后打印的日志信息]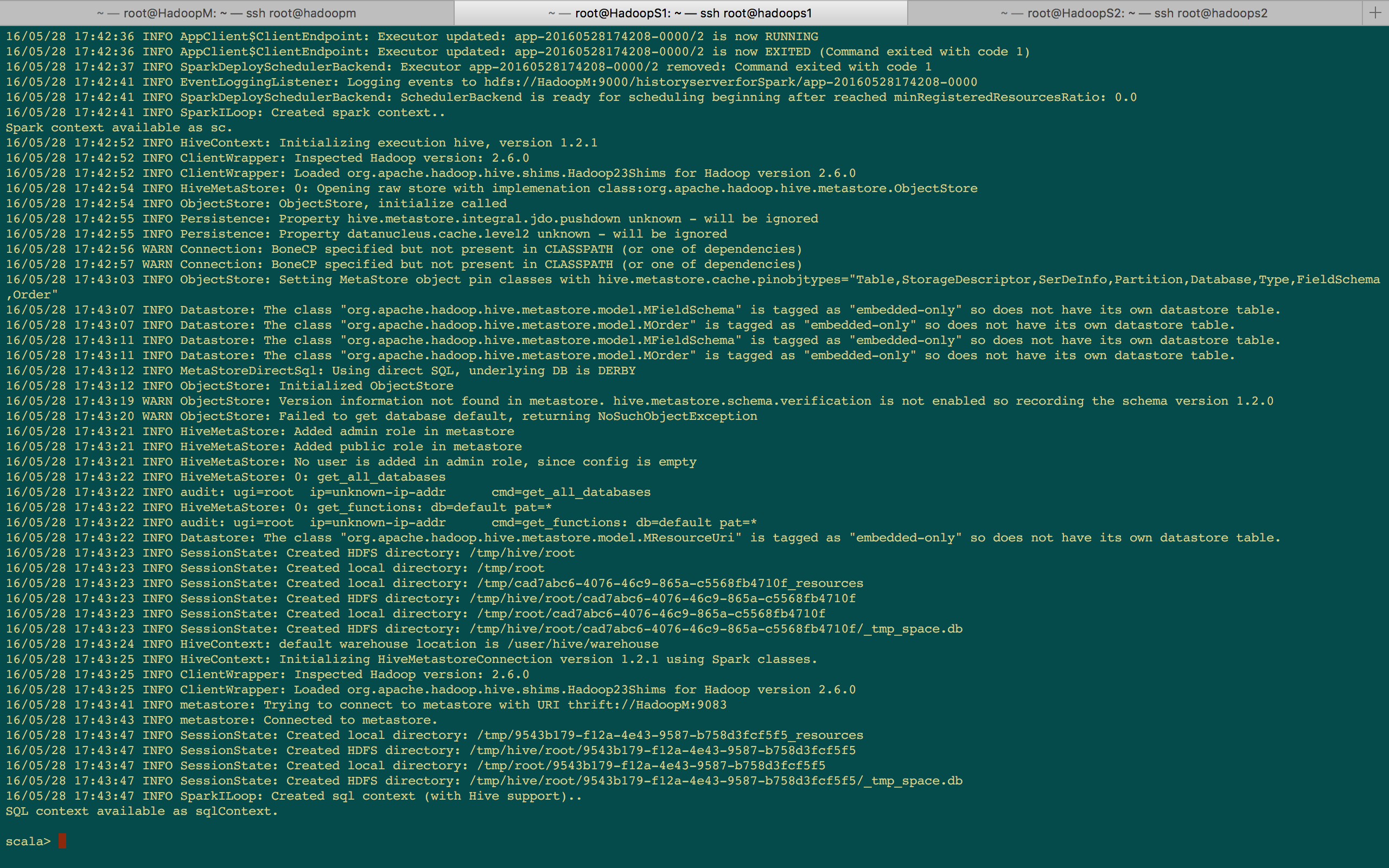
思考题:为什么启动 Spark-shell 的时候没有看见 DriverEndPoint?因为上述打印的日志是从一个应用程序的角度去考虑的,而不是从应用程序运行一个 Job 的层面去考虑的,一个应该程序启动时因为程序要向 Master 注册,所以当然有 AppClient 和 ClientEndPoint 的参与; 而 DriverEndPoint 是在XX时候创建的,因为此时没有运行任何的 Job,所以还没需要 DriverEndPoint 的参与。所以你可以通过观察 Spark-shell 以及应用程序运行的角度,你可以很清楚的看见 "应用程序" 和 "应用程序Job的运行" 是两种不同类型的事情。
作业提交的日志
接著提交了一个 Spark 应用程序 e.g. HelloSpark Wordcount。我们是调用了 foreach 来触发一个 Action,所以中间部份你可以看到它表示 Starting job。在 Starting Job 下一行日志看到当它触发一个 Job 时,首先把 Job 交给 DAGScheduler 来注册 RDD,然后获得一个 Job,然后划分成不同的 Stage (e.g. Final Stage),日志中看到它只有一个 ShuffleMapTask 和 一个 ResultStage;然后它提交的时候,首先提交 ShuffleMapStage 给 TaskSchedulerImpl,图中看见只有 1 个任务,此时已经提交给底层了。
任务是以 TaskSet 的方式提交给底层,同时创建了 TaskSetManager 去管理这个任务,TaskSetManager 知道这个任务的启动与结束,然后等待任务运行完毕后又会再次交给 DAGScheduler 说明任务已经完成。
[下图是 SparkShell 作业提交后打印的日志信息]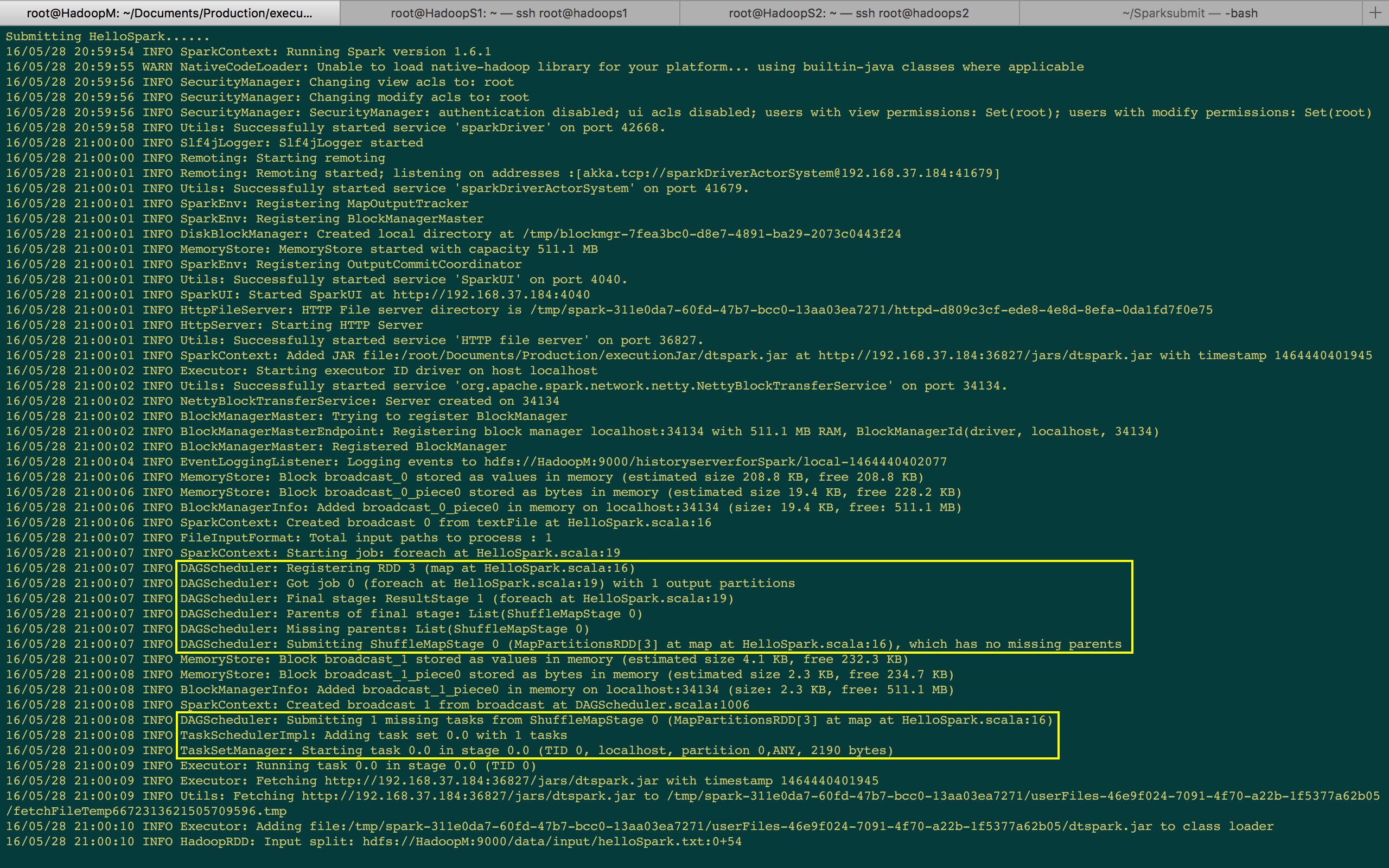
由于上一个 Stage 是 ShuffleMapTask,所以下一个 Stage 如果要运行的话,要先通过 MapOutputTrackerMasterEndpoint 来获取上一个阶段的输出。不过要注意一下,TaskSetManager 在启动的时候会具体说自己在哪个 Stage 、哪台机器上、哪个 Partition 和是否是数据本地性。数据本地性有几种实现的方式。(e.g. NODE_LOCAL 是数据就在当前机器的磁盘上)
[下图是 SparkShell 作业提交后打印的日志信息]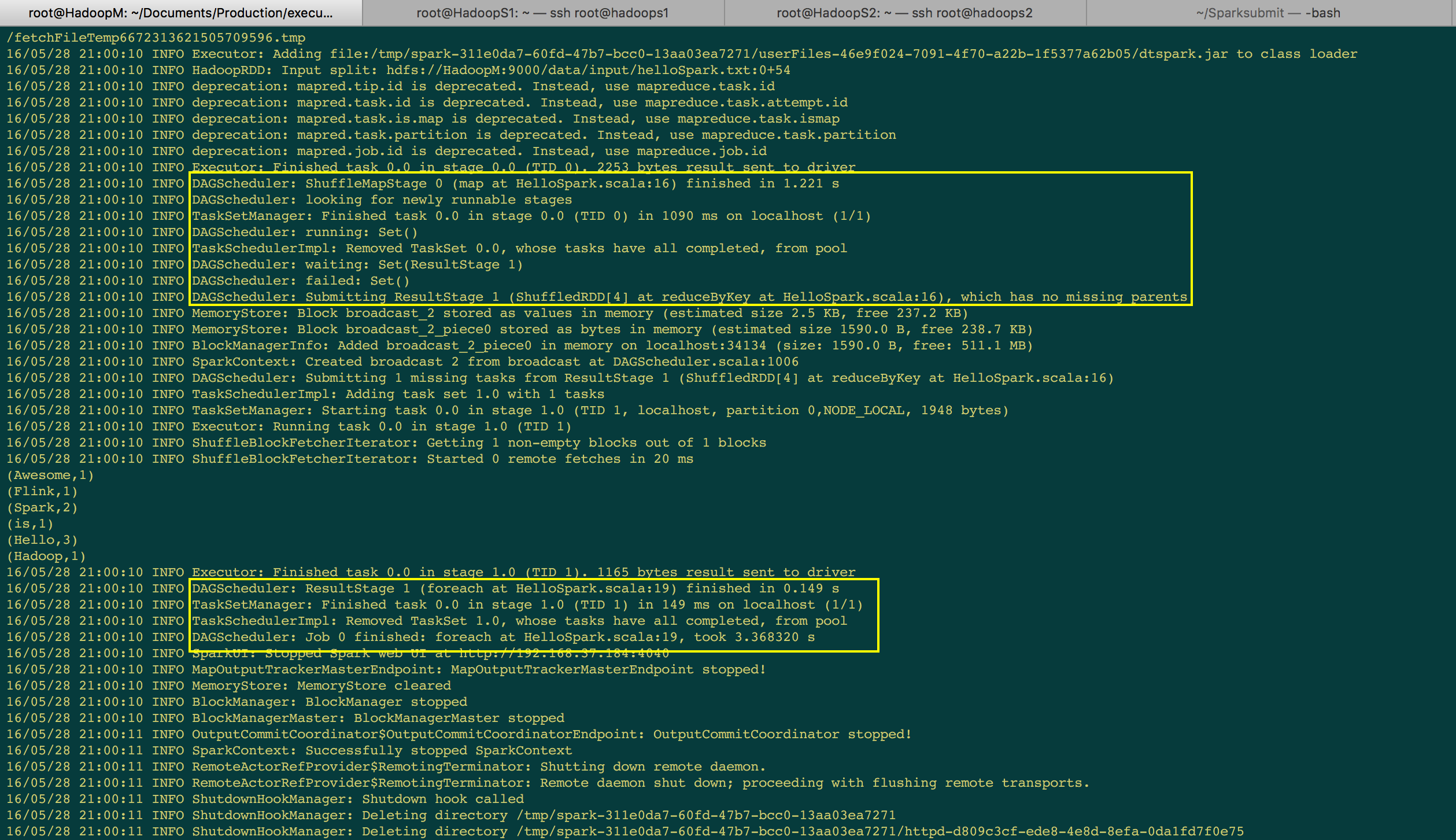
我们得出的结论是 DAGScheduler 划分好 Stage 之后会通过 TaskSchedulerImpl 中的 TaskSetManager 来管理当前要运行 Stage 中所有的任务 TaskSet,它是一个包含了高层调度器与底层调度器的一个集合。TaskSet 的第一个成员是一个数组;第二个成员表示自己属于那一个 Stage,第三个成员是 StageAttemptId,第四个是优先值,调度时底层有一个调度池,这个调度池会规定每个 Stage 提交后具体运行的优先级。
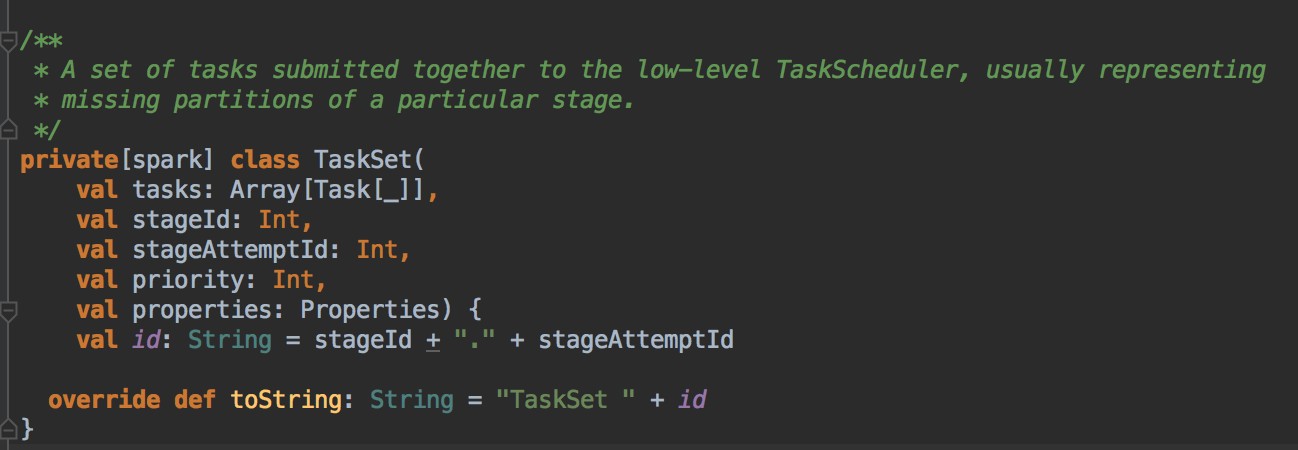
TaskSetManager 在实例化的时候要完成 TaskSchedulerImpl 的工作,因为它是 TaskSet 的管理者,所以它其中的一个成员肯定是 TaskSet,还有一个成员是每个任务最大的重试次数。TaskSetManager 会根据 locality aware 来为 Task 分配计算资源、监控 Task 的执行状态 (例如重试、慢任务进行推测式执行等,调度的时候底层有一个调度池)
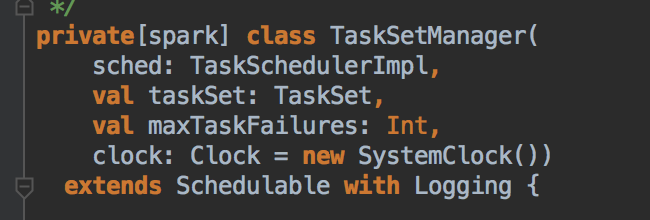
TaskScheduler 与 SchedulerBackend 之间的关系
他们两者之间的关系是一个是高层调度器、一个是底层调度器;一个负责 Stage 的划分、一个是负责把任务发送给 Executor 去执行并接收运行结果。
应用程序的资源分配在应用程序启动时已经完成,现在要考虑的是具体应用程序中每个任务到底要运行在那个 ExecutorBackend 上,现在是任务的分配。TaskScheduler 要负责为 Task 分配计算资源:此时程序已经分配好集群中的计算资源了,然后会根据计算本地性原则来确定 Task 具体要运行在那个 ExecutorBackend 中:
- 这里有两种不同的 Task,一种是 ShuffleMapTask,一种是 ResultMapTask
[下图是 DAGScheduler.scala 中 submitMissingTasks 方法中内部具体的实现]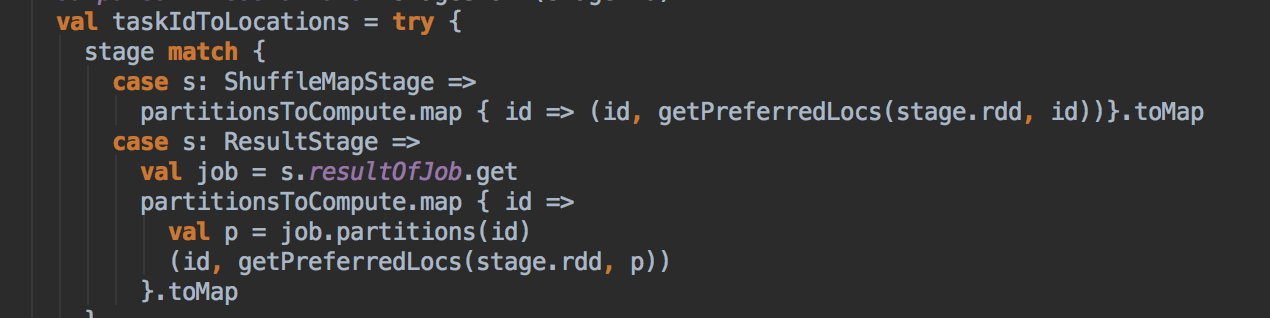
- DAGScheduler 完成面向 Stage 的划分之后,会按照顺序将每个 Stage 通过 TaskSchedulerImpl 的 Submit Task 提交给底层调度器 (提交作业啦!!!) TaskSchedulerImpl.submitTasks: 主要的作用是將 TaskSet 加入到 TaskSetManager 中進行管理;
[下图是 DAGScheduler.scala 中 submitMissingTasks 方法中内部具体的实现]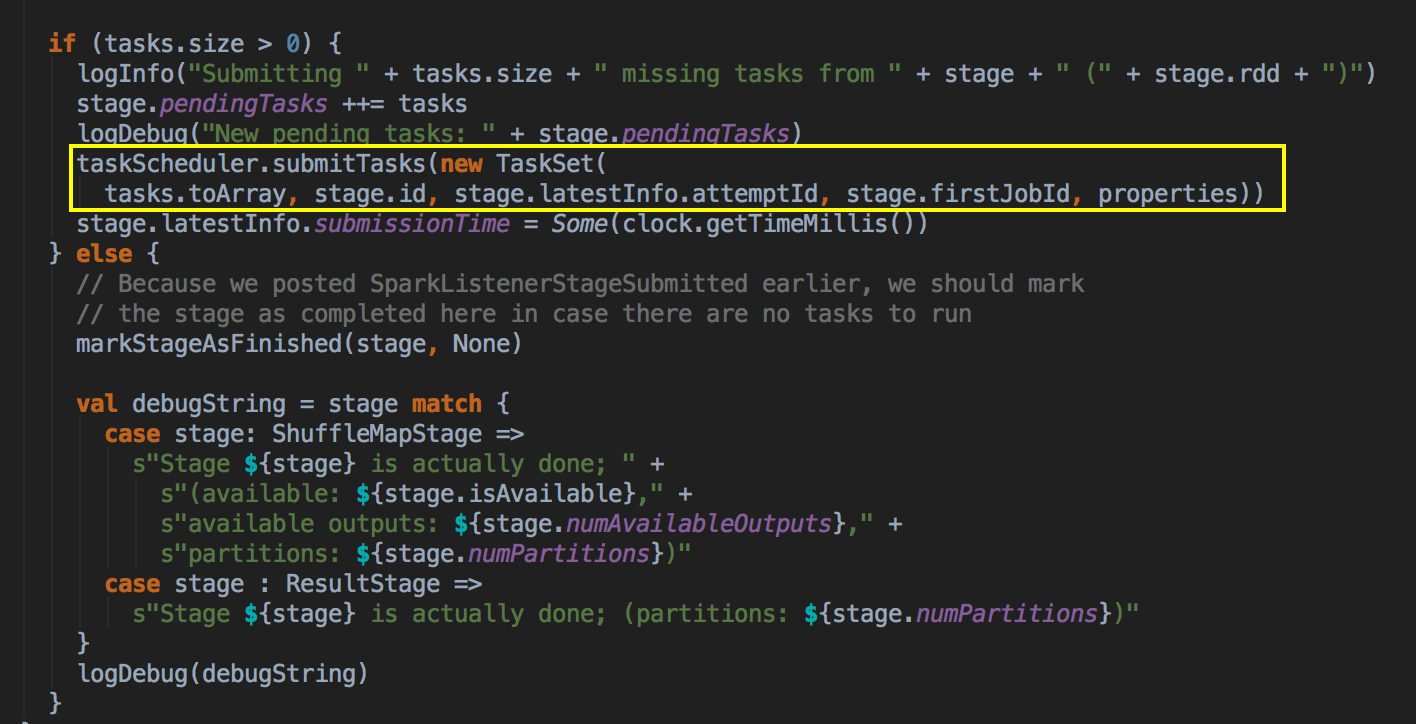
- 高层调度器 DAGScheduler 提交了任务是通过调用 submitTask 方法提交 TaskSet 给底层调度器,然后赋值给一个变量 Task,同时创建了一个 TaskSetManager 的实例,这个很关键,它传入了 taskSchedulerImpl 对象本身、TaskSet 和最大失败后自动重试的次数。
[下图是 TaskSchedulerImpl.scala 中 submitTasks 方法]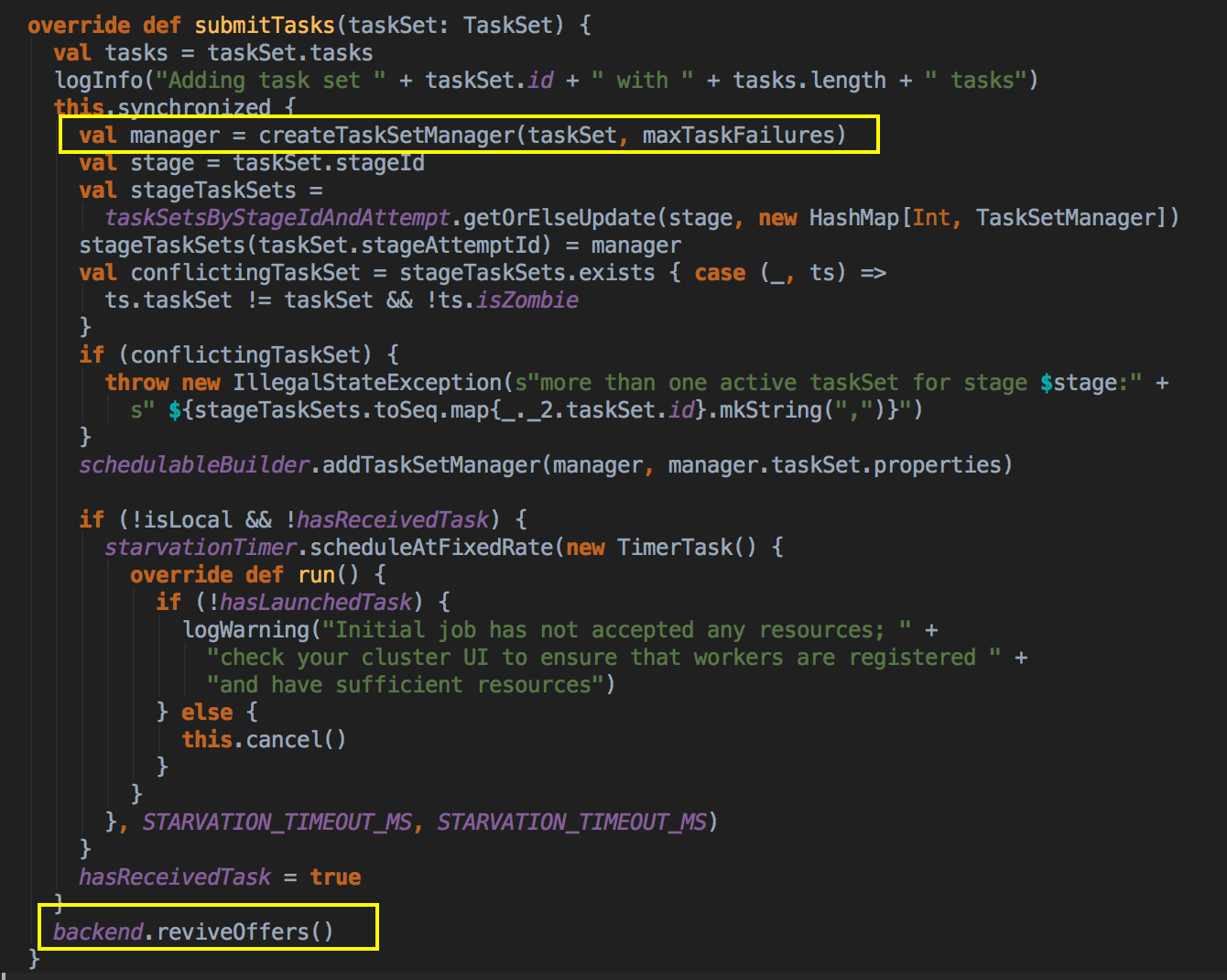
[下图是 TaskSchedulerImpl.scala 中 createTaskSetManager 方法]
- 创建 SparkContext 中调用了 createTaskScheduler 来创建 TaskSchedulerImpl 的实例,默认作业失败后自动重试的次数是 4 次。
[下图是 SparkContext.scala 中创建三大核心对象的代码实现]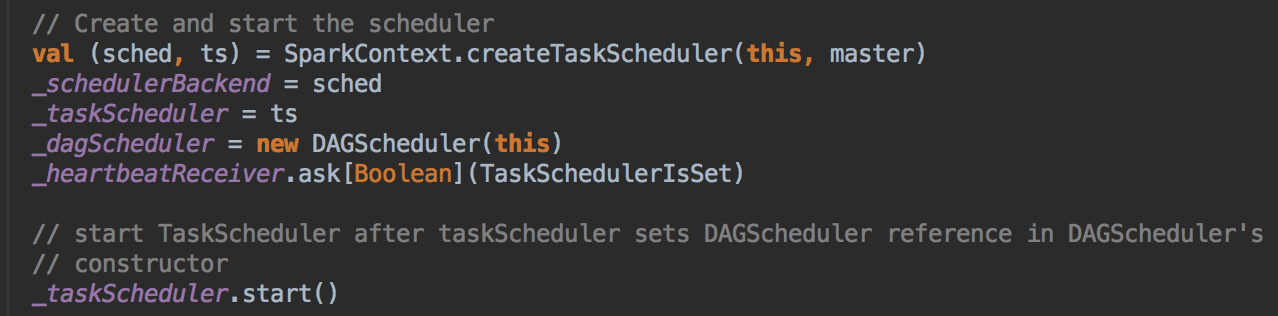
[下图是 TaskSchedulerImpl.scala 中类和主构造器]
- 比较关键的地方是调用了 schedulableBuilder 中的 addTaskSetManager,SchedulableBuilder 本身是应用程序级别的调度器,它自己支持两种调度模式。SchedulableBuilder 会确定 TaskSetManager 的调度顺序,然后按照 TaskSetManager 的 locality aware 来确定每个 Task 具体运行在那个 ExecutorBackend 中;补充说明:schedulableBuilder 是在创建 TaskSchedulerImpl 时实例化的。
[下图是 SchedulableBuilder.scala 中的方法]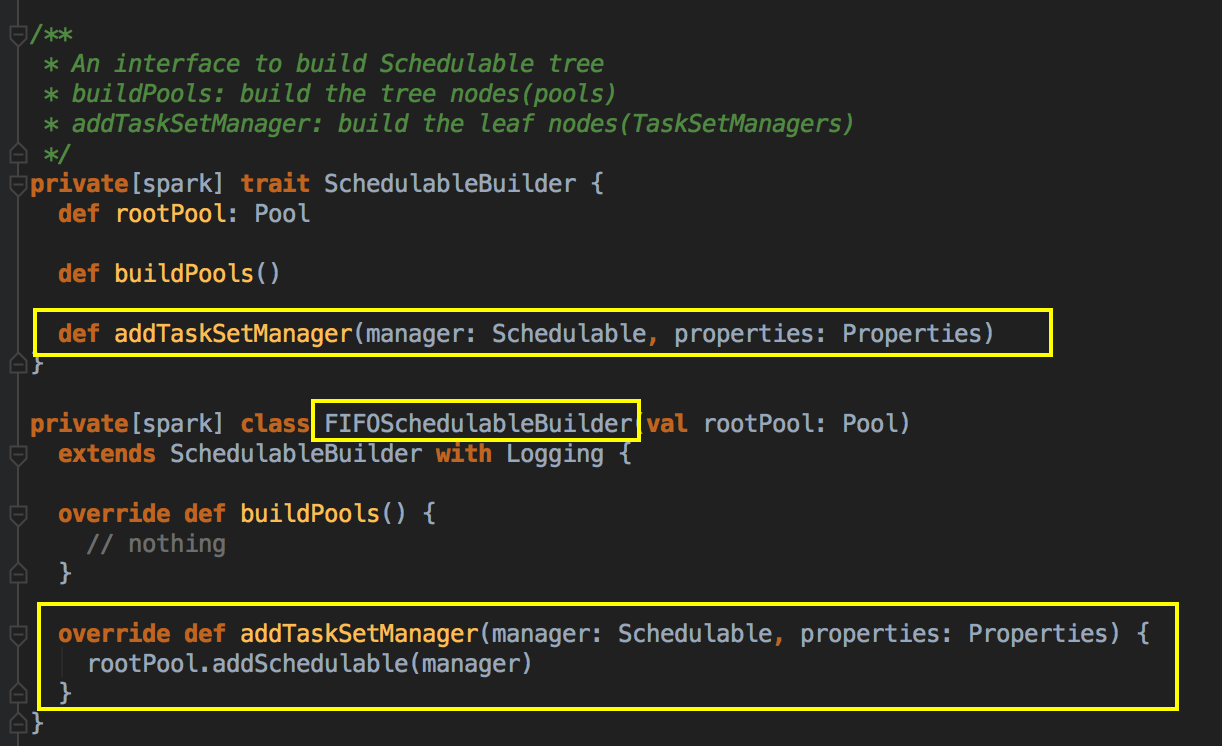
一种是FIFO; 另一种是FAIR,调度策略可以通过 spark-env.sh 中的 spark.scheduler.mode 进行具体的设置,默认情况下是 FIFO
[下图是 SparkContext.scala 中 createTaskScheduler 方法内部具体的实现]
[下图是 TaskScheduler.Impl 中 initialize 方法]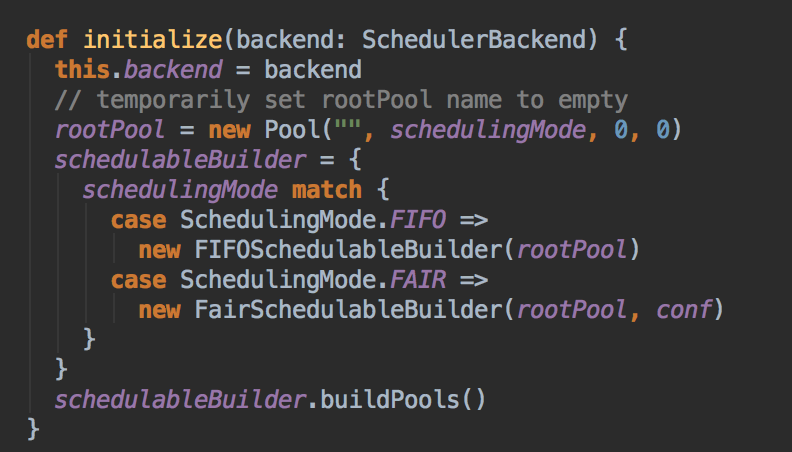
[下图是 TaskScheduler.Impl.scala 中 schedulingMode 变量的具体实现]
- 从第3步 submitTask 方法中最后调用了 backend.revivOffers 方法。这是 CoarseGrainedSchedulerBackend.reviveOffers: 给 DrivereEndpoint 发送 ReviveOffers,DriverEndPoint 是驱动程序的调度器;
[下图是 CoarseGrainedSchedulerBackend.scala 中 reviveOffers 方法]
[下图是 CoarseGrainedSchedulerBackend.scala 中 DriverEndPoint 类里的 start 方法]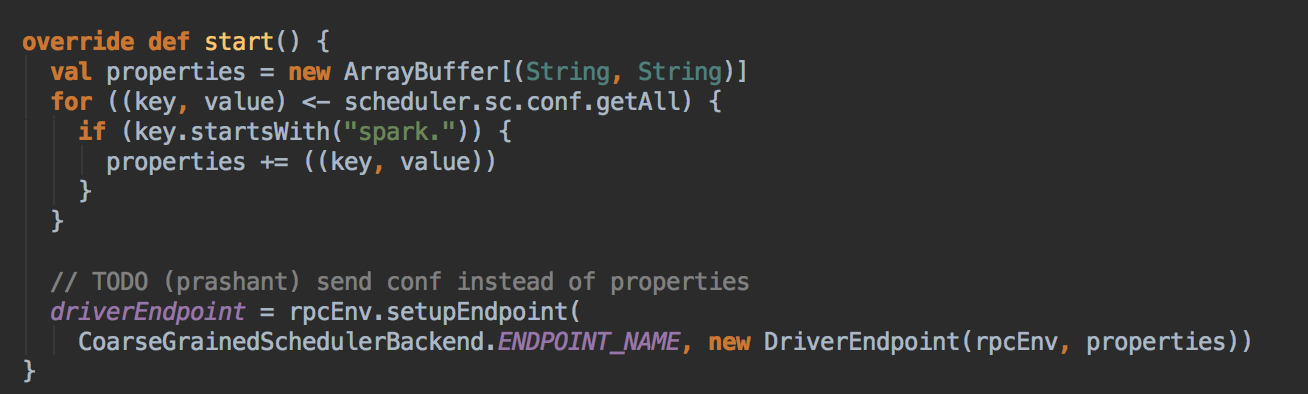
[下图是 CoarseGrainedSchedulerBackend.scala 中 DriverEndPoint 类]
[下图是 CoarseGrainedSchedulerBackend.scala 中 DriverEndPoint 类里的 receive 方法内部具体的实现]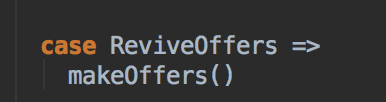
ReviveOffers 本身是一个空的 case object 对象,只是起到触发底层资源触发调度的作用,在有 Task 提交或者计算资源变动的时候会发送 ReviveOffers 这个消息作为触发器;
[下图是 CoarseGrainedClusterMessage.scala 中 ReviveOffers case object]
- 在 DriverEndpoint 接受 ReviveOffers 消息并路由到 makeOffers 具体的方法中;在 makeOffers 方法中首先准备好所有可以用于计算的 Executor,然后找出可以的 workOffers (代表了所有可用 ExecutorBackend 中可以使用的 CPU Cores 信息)WorkerOffer 会告我们具体 Executor 可用的资源,比如说 CPU Core,为什么此时不考虑内存只考虑 CPU Core,因为在这之前已经分配好了。
[下图是 CoarseGrainedSchedulerBackend.scala 中 makeOffers 方法]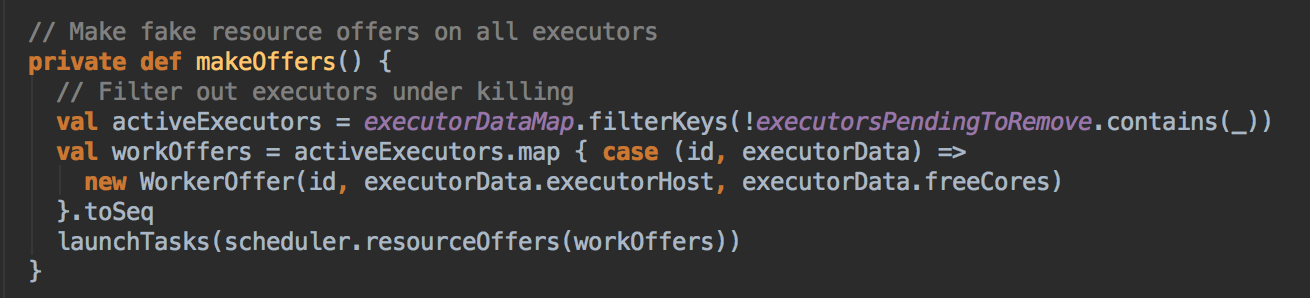
[下图是 WorkerOffer.scala 中 WorkerOffer case class]
- 而确定 Task 具体运行在哪个 ExecutorBackend 上的算法是由 TaskSetManager 的 resourceOffer 的方法決定。TaskScheduerImpl.resourceOffers: 为每一个Task 具体分配计算资源,输入是 ExcutorBackend 及其上可用的 Cores,输出 TaskDescription 的二位数组,在其中确定了每个 Task 具体运行在哪个 ExecutorBackend: resourceOffers 到底是如何确定 Task 具体运行在那个 ExecutorBackend 上的呢?算法的实现具体如下:
[下图是 TaskSchedulerImpl.scala 中 resourceOffers 方法]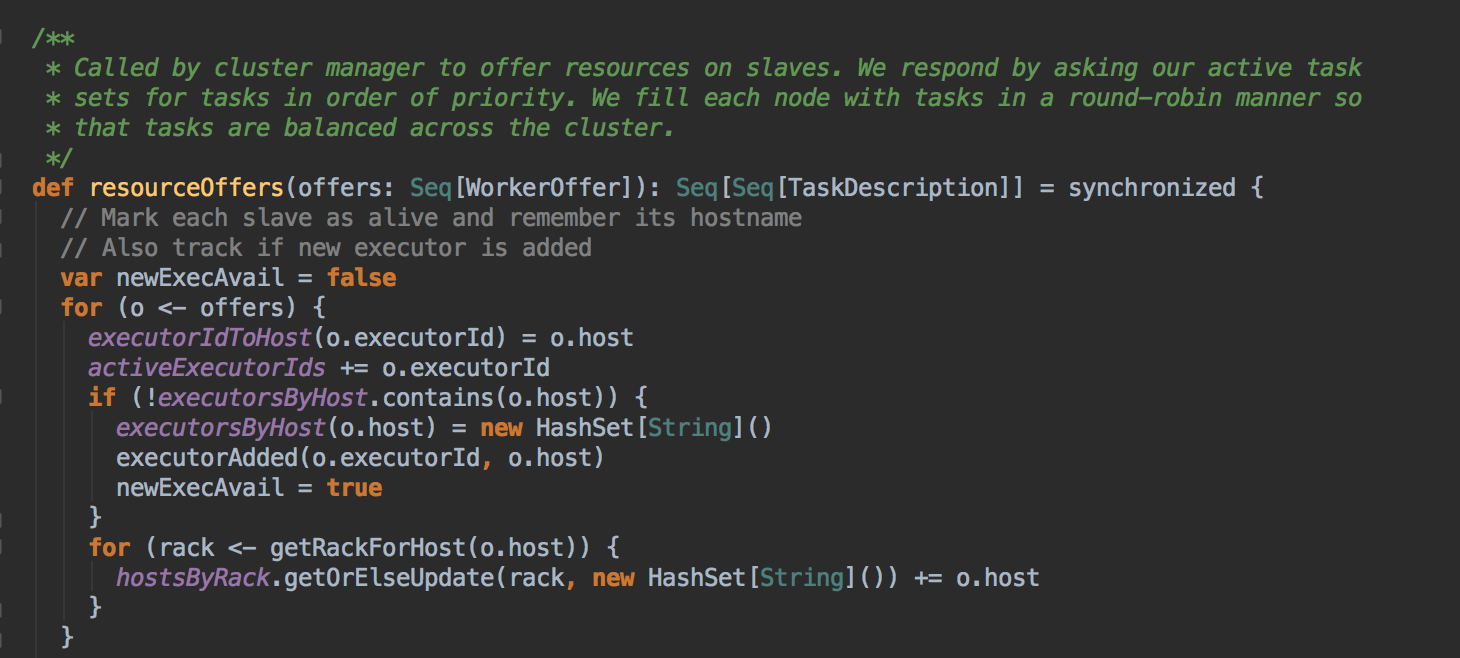
[下图是 TaskSchedulerImpl.scala 中 resourceOffers 方法内部具体的实现]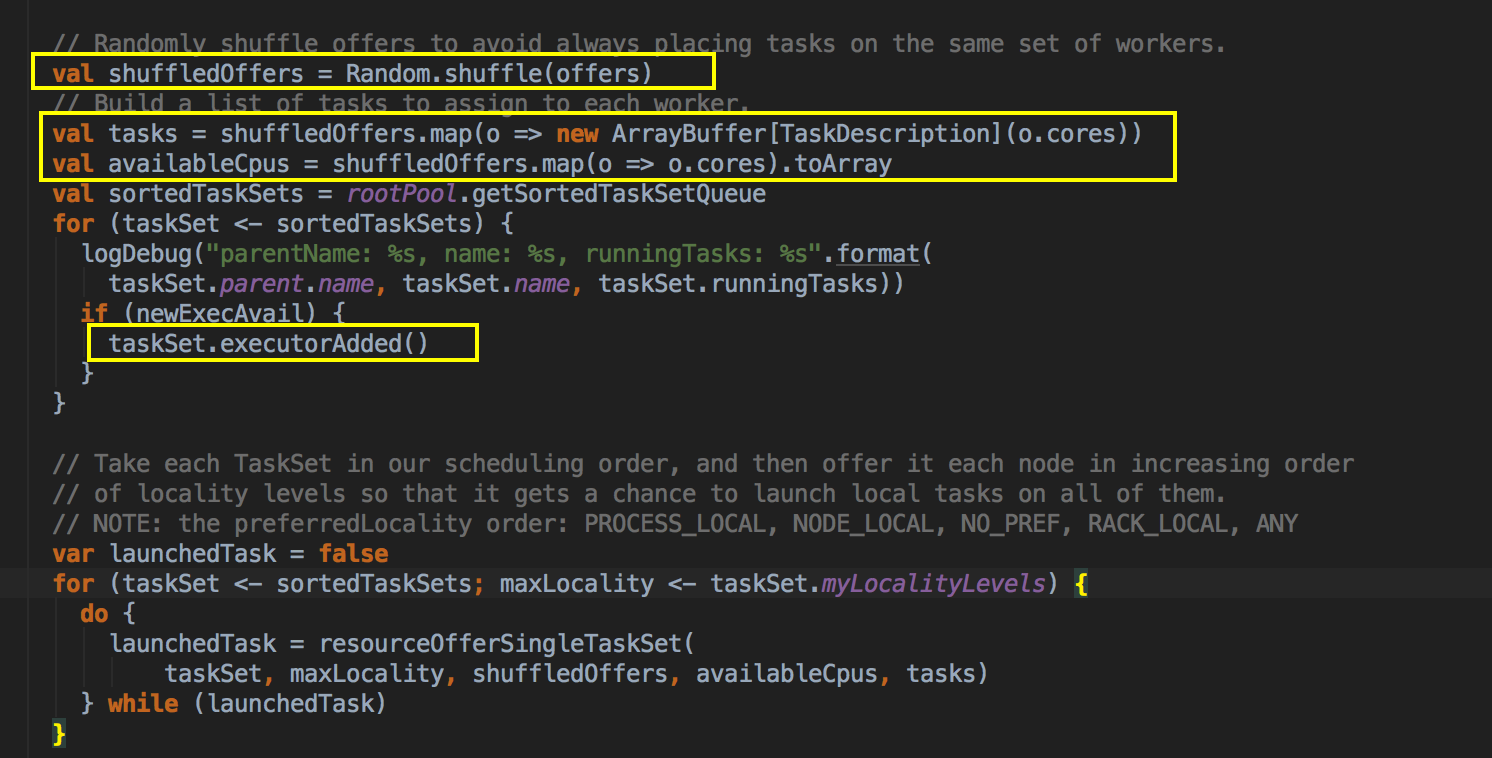
- 通过 Random.shuffle 方法重新洗牌所有的计算以寻找以计算的负载均衡;
- 根据每个 ExecutorBackend 的 cores 的个数声明类行为 TaskDescription 的 ArrayBuffer 数组
- 打散的是 Executor 的资源,这样有随机性,随机性有利于负载均衡;
- 如果有新的 ExecutorBackend 分配给我们的 Job 此时会调用 ExecutorAdded 来获得最新的完整的可用计算资源。
[下图是 TaskSetManager.scala 中 executorAdded 方法]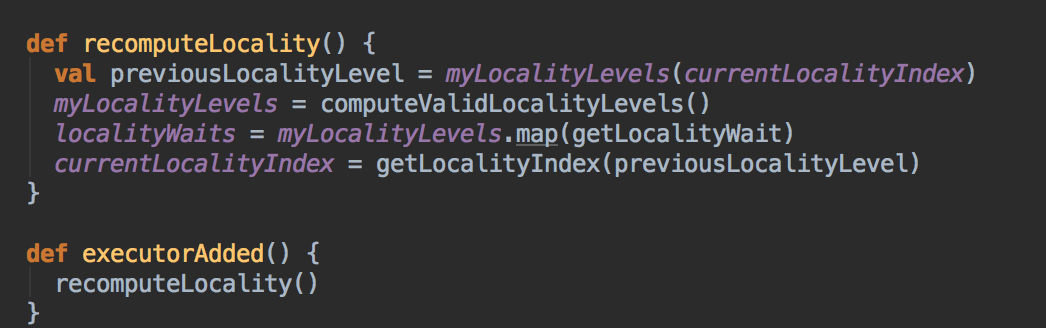
- 优先本地性从高到低依次为:PROCESS_LOCAL、NODE_LOCAL、NO_PREF、RACK_LOCAL、ANY. 其中 NO_PREF 是指机器本地性。一台机器通常就只有一个 Node。我们追求的是 Node 的本地性高于机器本地性。每个 Task 默认是采用一个线程进行计算的。
[下图是 TaskSetManager.scala 中 computeValidLocalityLevels 方法]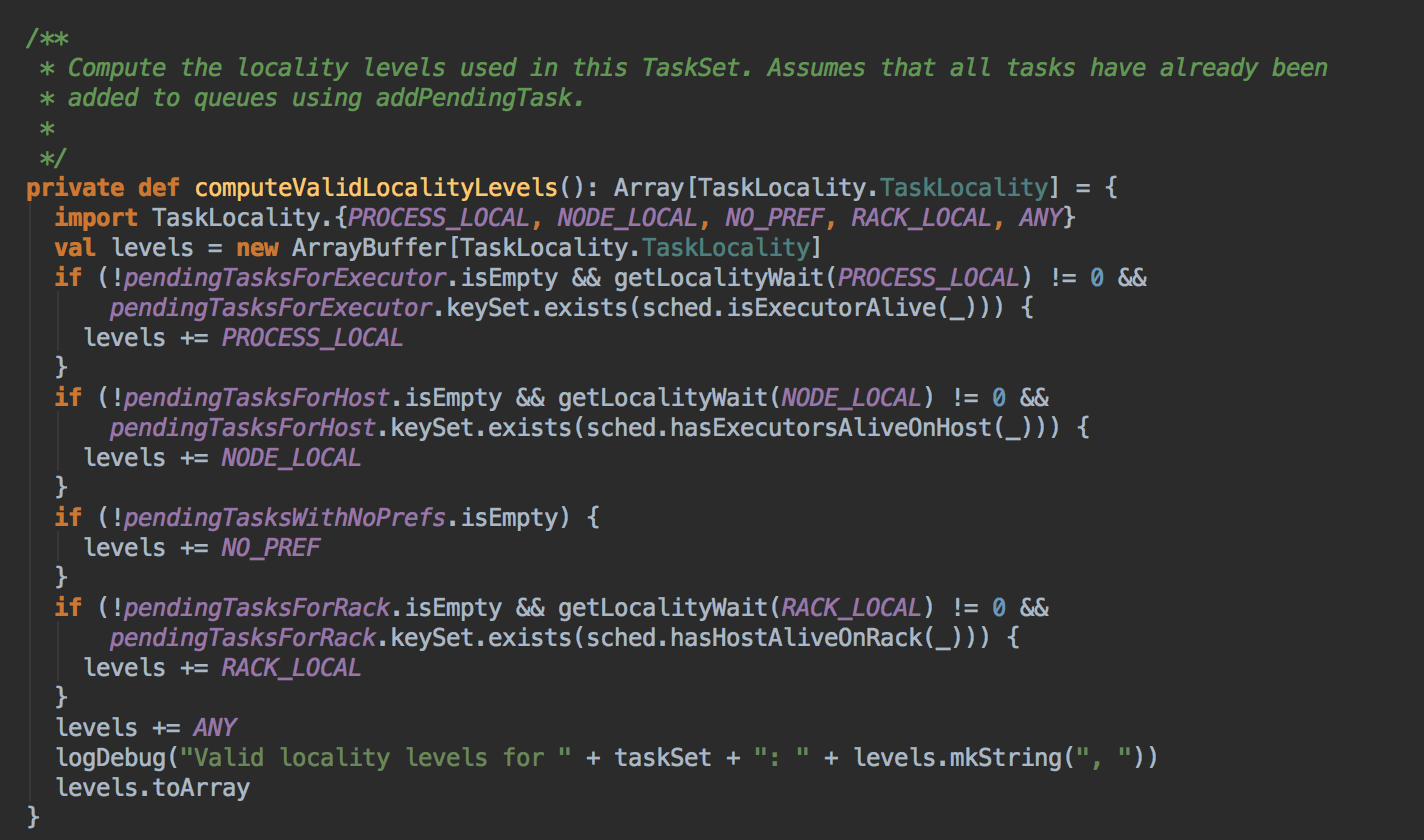
- 从 TaskSchedulerImpl.scala 中的 resourceOffers 后续调用了 resourceOfferSignleTask 来确定了具体任务运行在那台机制上
[下图是 TaskSchedulerImpl.scala 中 resourceOfferSingleTask 方法]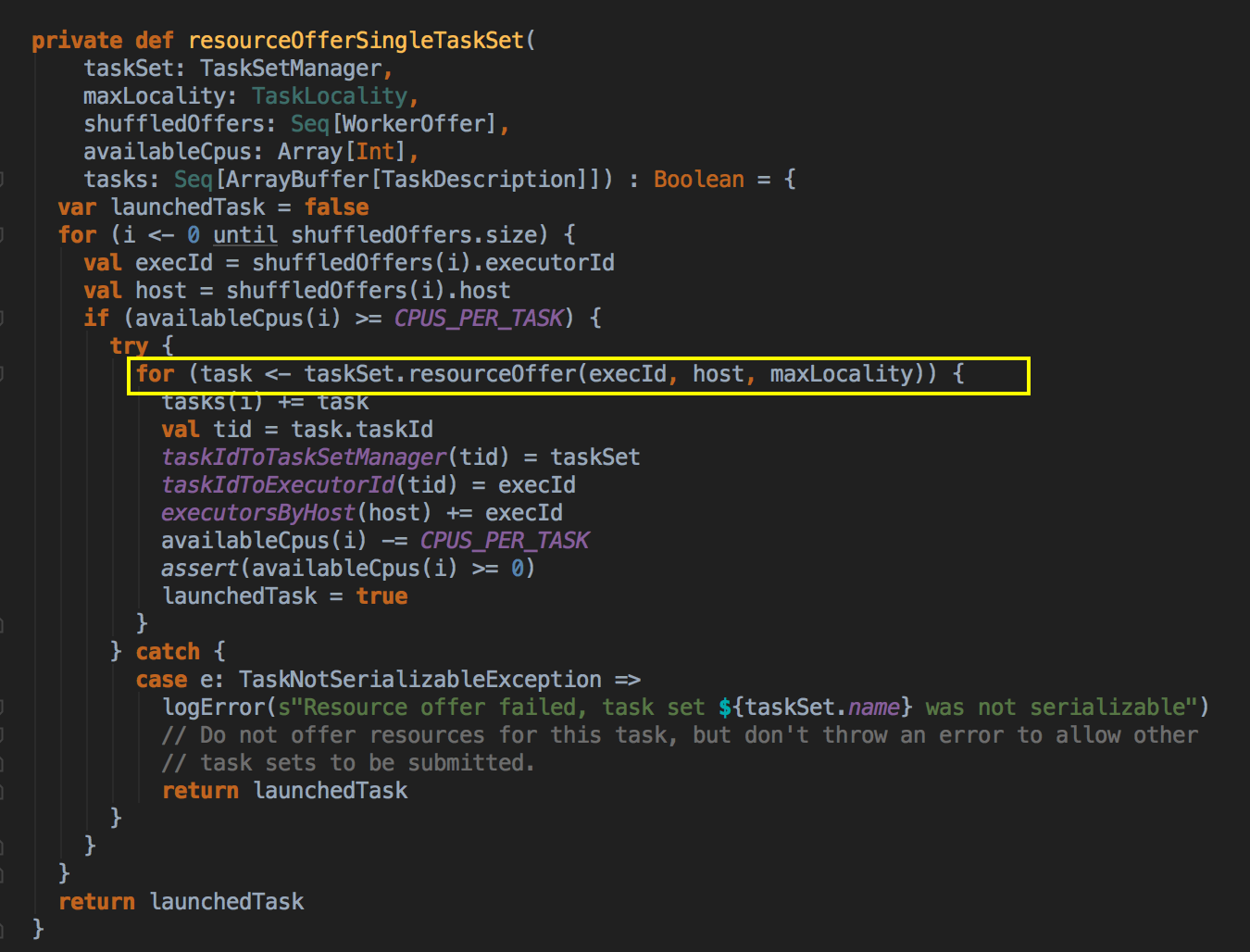
- 通过调用 TaskSetManager 的 resourceOffer 最终确定每个 Task 具体运行在哪个 ExecutorBackend 的具体 Locality Level;
- 在第7步调用makeOffers方法后,再通过 launchTasks 把任务发送给 ExecutorBackend 去执行
[下图是 CoarseGrainedSchedulerBackend.scala 中 launchTasks 方法]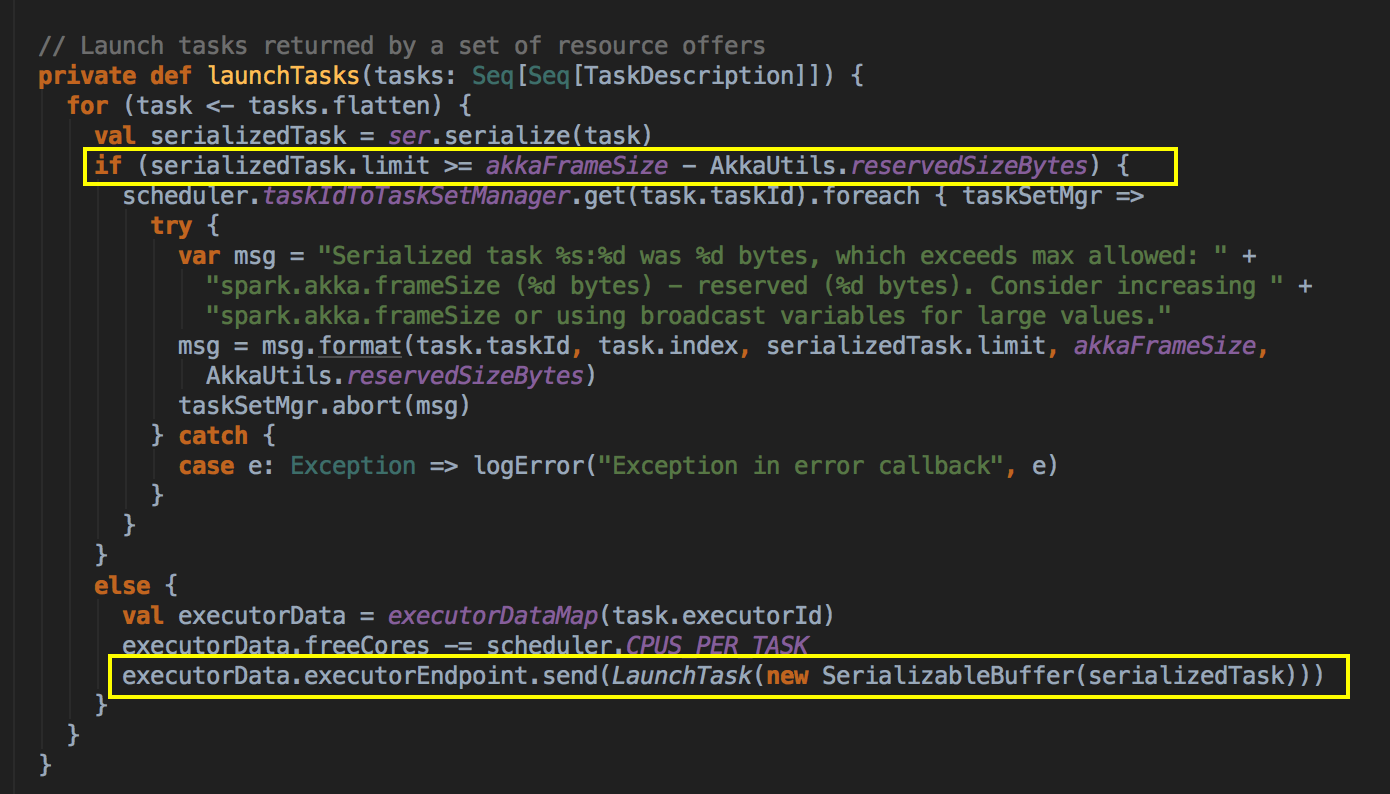
- DAGScheduler 是从数据层面考虑 preferredLocation 的,而 TaskScheduler 是从具体计算 Task 的角度考虑计算的本地性 Task 进行广播时候的 AkkFrameSize 大小是 128MB,这样改好处是可以广播大任务。如果任务大于等于 128 MB - 200K 的话则 Task 会直接被丢弃掉。如果小于 128 MB - 200K 会通过 CoarseGraninedExecutorBackend 去 launchTask 到具体的 ExecutorBackend 上。
[下图是 CoarseGrainedSchedulerBackend.scala 中 akkaFrameSize 变量]
[下图是 AkkaUtils.scala 中 maxFrameSizeBytes 方法]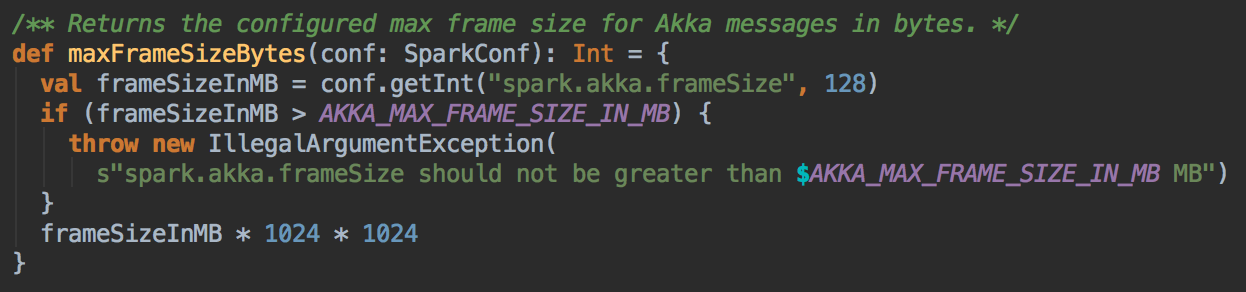
总结
TaskScheduler内幕天机解密:Spark shell案例运行日志详解、TaskScheduler和SchedulerBackend、FIFO与FAIR、Task运行时本地性算法详解等的更多相关文章
- [Spark内核] 第36课:TaskScheduler内幕天机解密:Spark shell案例运行日志详解、TaskScheduler和SchedulerBackend、FIFO与FAIR、Task运行时本地性算法详解等
本課主題 通过 Spark-shell 窥探程序运行时的状况 TaskScheduler 与 SchedulerBackend 之间的关系 FIFO 与 FAIR 两种调度模式彻底解密 Task 数据 ...
- [Spark内核] 第31课:Spark资源调度分配内幕天机彻底解密:Driver在Cluster模式下的启动、两种不同的资源调度方式源码彻底解析、资源调度内幕总结
本課主題 Master 资源调度的源码鉴赏 [引言部份:你希望读者看完这篇博客后有那些启发.学到什么样的知识点] 更新中...... 资源调度管理 任务调度与资源是通过 DAGScheduler.Ta ...
- Spark资源调度分配内幕天机彻底解密:Driver在Cluster模式下的启动、两种不同的资源调度方式源码彻底解析、资源调度内幕总结
本课主题 Master 资源调度的源码鉴赏 资源调度管理 任务调度与资源是通过 DAGScheduler.TaskScheduler.SchedulerBackend 等进行的作业调度 资源调度是指应 ...
- Spark Streaming揭秘 Day28 在集成开发环境中详解Spark Streaming的运行日志内幕
Spark Streaming揭秘 Day28 在集成开发环境中详解Spark Streaming的运行日志内幕 今天会逐行解析一下SparkStreaming运行的日志,运行的是WordCountO ...
- [Spark内核] 第33课:Spark Executor内幕彻底解密:Executor工作原理图、ExecutorBackend注册源码解密、Executor实例化内幕、Executor具体工作内幕
本課主題 Spark Executor 工作原理图 ExecutorBackend 注册源码鉴赏和 Executor 实例化内幕 Executor 具体是如何工作的 [引言部份:你希望读者看完这篇博客 ...
- Spark RDD概念学习系列之Spark Hash Shuffle内幕彻底解密(二十)
本博文的主要内容: 1.Hash Shuffle彻底解密 2.Shuffle Pluggable解密 3.Sorted Shuffle解密 4.Shuffle性能优化 一:到底什么是Shuffle? ...
- Spark Streaming数据清理内幕彻底解密
本讲从二个方面阐述: 数据清理原因和现象 数据清理代码解析 Spark Core从技术研究的角度讲 对Spark Streaming研究的彻底,没有你搞不定的Spark应用程序. Spark Stre ...
- 25,Spark Sort-Based Shuffle内幕彻底解密
一:为什么需要Sort-Based Shuffle? 1, Shuffle一般包含两个阶段任务: 第一部分:产生Shuffle数据的阶段(Map阶段,额外补充,需要实现ShuffleManager中 ...
- [Spark性能调优] 第二章:彻底解密Spark的HashShuffle
本課主題 Shuffle 是分布式系统的天敌 Spark HashShuffle介绍 Spark Consolidated HashShuffle介绍 Shuffle 是如何成为 Spark 性能杀手 ...
随机推荐
- 为什么要实现Serializable
工作中我们经常在进行持久化操作和返回数据时都会使用到javabean来统一封装参数,方便操作,一般我们也都会实现Serializable接口,那么问题来了,首先:为什么要进行序列化:其次:每个实体be ...
- django notes 一:开篇
公司 web 框架用的是 django, 以前没用过,打算这两周好好看看. 边学习边整理一下笔记,加深理解. 好像谁说过初学者更适合写入门级的教程,我觉得有一定道理. 高手写的教程有一定深度,不会写入 ...
- Python基础(1) - 初识Python
Python 特点: 1)面向对象 2)解释执行 3)跨平台.可移植 4)垃圾回收机制 5)动态数据类型.强类型 6)可扩展.可嵌入 Python可以方便调用C/C++等语言,同时也可以方便的被C/C ...
- [转]Oracle中没有 if exists(...)
本文转自:http://blog.csdn.net/hollboy/article/details/7550171 对于Oracle中没有 if exists(...) 的语法,目前有许多种解决方法, ...
- PHP之数组和函数的基本教程
[PHP数组的分类] 按照下标的不同,PHP数组分为关联数组与索引数组 索引数组:下标从0开始,依次增长: 关联数组:下标为字符串格式,每个下标字符串与数字的值一一关联对应(有点像对象的键值对) [关 ...
- ASP.NET MVC4 新手入门教程之一 ---1.介绍ASP.NET MVC4
你会建造 您将实现一个简单的电影清单应用程序支持创建. 编辑. 搜索和清单数据库中的电影.下面是您将构建的应用程序的两个屏幕截图.它包括显示来自数据库的电影列表的网页: 应用程序还允许您添加. 编辑和 ...
- Charles破解(转)
NB的Charles是一款付费软件.但…本文将讲解如何破解Charles.注:虽然与文章内容相悖,但还是希望大家能购买正版软件,毕竟都是做软件开发的,何必自断生路,要有版权意识. 环境信息: Mac ...
- 05.部分类 partial
namespace _06.部分类 { class Program { static void Main(string[] args) { } } /// <summary> /// 这个 ...
- 二、NAT(地址转换模式)
刚刚我们说到,如果你的网络ip资源紧缺,但是你又希望你的虚拟机能够联网,这时候NAT模式是最好的选择.NAT模式借助虚拟NAT设备和虚拟DHCP服务器,使得虚拟机可以联网.其网络结构如下图所示: NA ...
- 无限滚动条的css布局理解
一.需求描述 做一个waymo的滚动条,在页面中显示两张图,一共4张图,无限滚动播放. .car{ width: 600px; height: 157px; margin: 100px auto; b ...