手写raft(三) 实现日志压缩
手写raft(三) 实现日志压缩
在上一篇博客中MyRaft实现了日志复制功能,按照计划接下来需要实现日志压缩。
1. 什么是raft日志压缩?
我们知道raft协议是基于日志复制的协议,日志数据是raft的核心。但随着raft集群的持续工作,raft的日志文件将会维护越来越多的日志,而这会带来以下几个问题。
- 日志文件过大会占用所在机器过多的本地磁盘空间。
- 对于新加入集群的follower,leader与该follower之间完成日志同步会非常缓慢。
- 对于自身不进行持久化的状态机,raft节点重启后回放日志也会非常缓慢。
考虑到绝大多数的状态机中存储的数据并不都是新增,而更多的是对已有数据的更新,则状态机中所存储的数据量通常会远小于raft日志的总大小。例如K/V数据库,对相同key的N次操作(整体更新操作),只有最后一次操作是实际有效的,而在此之前的针对该key的raft日志其实已经没有保存的必要了。
因此raft的作者在论文的日志压缩一节中提到了几种日志压缩的算法(基于快照的、基于LSM树的),raft选择了更容易理解和实现的、基于状态机快照的算法作为日志压缩的基础。
2. MyRaft日志压缩实现源码解析
raft日志压缩实现中有以下几个关键点:
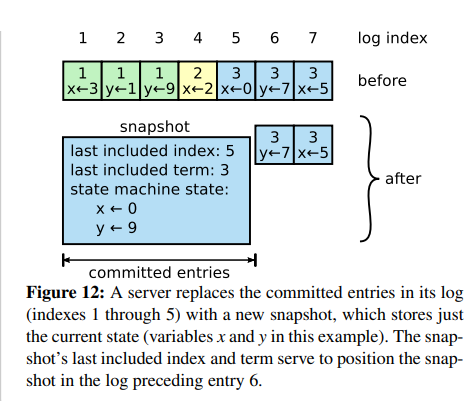
- raft的各个节点可以按照某种策略独立的生成快照(比如定期检测日志文件大小是否超过阈值),快照的主要内容是状态机当前瞬间所维护的所有数据的快照。
MyRaft的状态机是一个纯内存的K/V数据库,所以快照就是内存中对应Map数据序列化后的内容。 - 当前状态机中的快照实际上等同于所有已提交日志的顺序执行的最终结果,快照文件生成后会将所有已提交的日志全部删除以达成压缩的目的。
而在处理appendEntries时,leader需要在参数中设置当前传输日志的前一条日志的index和term值,如果此时leader前一条日志恰好是已提交的并且被压缩到快照里而被删除了,则获取不到这个值了。
相对应的,follower也可能出现类似的情况,即当前所有日志都是已提交的并且由于日志压缩被删除了,进行prevIndex/prevTerm校验时,也需要这个数据。
因此,最终的快照中包含了最后一条已提交日志的index和term值这一关键的元数据。 - 在leader和日志进度较慢的follower进行通信时,如果follower所需要的日志是很早的,而leader这边对应index的日志又被快照压缩而删除了,没法通过appendEntries进行同步。
raft对此新增加了一个rpc接口installSnapshot专门用于解决这个问题。在leader发现follower所需的日志已经被自己压缩到快照里时,则会通过installSnapshot将自己完整的快照直接复制给follower。
由于快照可能很大,所以installSnapshot一次只会传输少量的日志,通过多次的交互后完成整个快照的安装。当follower侧完成了快照同步后,后续所需要同步的日志就都是leader日志文件中还保留的,后续的日志接着使用appendEntries同步即可。
下面开始结合源码分析MyRaft的日志压缩功能
2.1 日志快照模块
- raft快照数据由RaftSnapshot对象承载,除了二进制的状态机状态数据外,还包括了快照最后一条日志的index和term的值。
- MyRaft关于快照数据读写的逻辑集中维护在SnapshotModule中,简单起见使用一把全局的读写锁来防止并发而不过多的考虑性能。
在SnapshotModule中通过引入临时文件的方式来解决新快照文件在生成过程中可能突然宕机的问题。
/**
* raft快照对象
* */
public class RaftSnapshot {
/**
* 快照所包含的最后一条log的索引编号
* */
private long lastIncludedIndex;
/**
* 快照所包含的最后一条log的任期编号
* */
private int lastIncludedTerm;
/**
* 快照数据
* (注意:暂不考虑快照过大导致byte数组放不下的情况)
* */
private byte[] snapshotData = new byte[0];
}
public class SnapshotModule {
private static final Logger logger = LoggerFactory.getLogger(SnapshotModule.class);
private final RaftServer currentServer;
private final File snapshotFile;
private final ReentrantReadWriteLock reentrantLock = new ReentrantReadWriteLock();
private final ReentrantReadWriteLock.WriteLock writeLock = reentrantLock.writeLock();
private final ReentrantReadWriteLock.ReadLock readLock = reentrantLock.readLock();
private static final String snapshotFileName = "snapshot.txt";
private static final String snapshotTempFileName = "snapshot-temp.txt";
/**
* 存放快照实际数据的偏移量(lastIncludedIndex + lastIncludedTerm 共两个字段后存放快照)
* */
private static final int actualDataOffset = 4 + 8;
public SnapshotModule(RaftServer currentServer) {
this.currentServer = currentServer;
// 保证目录是存在的
String snapshotFileDir = getSnapshotFileDir();
new File(snapshotFileDir).mkdirs();
snapshotFile = new File(snapshotFileDir + File.separator + snapshotFileName);
File snapshotTempFile = new File(snapshotFileDir + File.separator + snapshotTempFileName);
if(!snapshotFile.exists() && snapshotTempFile.exists()){
// 快照文件不存在,但是快照的临时文件存在。说明在写完临时文件并重命名之前宕机了(临时文件是最新的完整快照)
// 将tempFile重命名为快照文件
snapshotTempFile.renameTo(snapshotFile);
logger.info("snapshot-temp file rename to snapshot file success!");
}
}
/**
* 持久化一个新的快照文件
* (暂不考虑快照太大的问题)
* */
public void persistentNewSnapshotFile(RaftSnapshot raftSnapshot){
logger.info("do persistentNewSnapshotFile raftSnapshot={}",raftSnapshot);
writeLock.lock();
try {
String userPath = getSnapshotFileDir();
// 新的文件名是tempFile
String newSnapshotFilePath = userPath + File.separator + snapshotTempFileName;
logger.info("do persistentNewSnapshotFile newSnapshotFilePath={}", newSnapshotFilePath);
File snapshotTempFile = new File(newSnapshotFilePath);
try (RandomAccessFile newSnapshotFile = new RandomAccessFile(snapshotTempFile, "rw")) {
MyRaftFileUtil.createFile(snapshotTempFile);
newSnapshotFile.writeInt(raftSnapshot.getLastIncludedTerm());
newSnapshotFile.writeLong(raftSnapshot.getLastIncludedIndex());
newSnapshotFile.write(raftSnapshot.getSnapshotData());
logger.info("do persistentNewSnapshotFile success! raftSnapshot={}", raftSnapshot);
} catch (IOException e) {
throw new MyRaftException("persistentNewSnapshotFile error", e);
}
// 先删掉原来的快照文件,然后把临时文件重名名为快照文件(delete后、重命名前可能宕机,但是没关系,重启后构造方法里做了对应处理)
snapshotFile.delete();
snapshotTempFile.renameTo(snapshotFile);
}finally {
writeLock.unlock();
}
}
/**
* 安装快照
* */
public void appendInstallSnapshot(InstallSnapshotRpcParam installSnapshotRpcParam){
logger.info("do appendInstallSnapshot installSnapshotRpcParam={}",installSnapshotRpcParam);
writeLock.lock();
String userPath = getSnapshotFileDir();
// 新的文件名是tempFile
String newSnapshotFilePath = userPath + File.separator + snapshotTempFileName;
logger.info("do appendInstallSnapshot newSnapshotFilePath={}", newSnapshotFilePath);
File snapshotTempFile = new File(newSnapshotFilePath);
try (RandomAccessFile newSnapshotFile = new RandomAccessFile(snapshotTempFile, "rw")) {
MyRaftFileUtil.createFile(snapshotTempFile);
if(installSnapshotRpcParam.getOffset() == 0){
newSnapshotFile.setLength(0);
}
newSnapshotFile.seek(0);
newSnapshotFile.writeInt(installSnapshotRpcParam.getLastIncludedTerm());
newSnapshotFile.writeLong(installSnapshotRpcParam.getLastIncludedIndex());
// 文件指针偏移,找到实际应该写入快照数据的地方
newSnapshotFile.seek(actualDataOffset + installSnapshotRpcParam.getOffset());
// 写入快照数据
newSnapshotFile.write(installSnapshotRpcParam.getData());
logger.info("do appendInstallSnapshot success! installSnapshotRpcParam={}", installSnapshotRpcParam);
} catch (IOException e) {
throw new MyRaftException("appendInstallSnapshot error", e);
} finally {
writeLock.unlock();
}
if(installSnapshotRpcParam.isDone()) {
writeLock.lock();
try {
// 先删掉原来的快照文件,然后把临时文件重名名为快照文件(delete后、重命名前可能宕机,但是没关系,重启后构造方法里做了对应处理)
snapshotFile.delete();
snapshotTempFile.renameTo(snapshotFile);
} finally {
writeLock.unlock();
}
}
}
/**
* 没有实际快照数据,只有元数据
* */
public RaftSnapshot readSnapshotMetaData(){
if(this.snapshotFile.length() == 0){
return null;
}
readLock.lock();
try(RandomAccessFile latestSnapshotRaFile = new RandomAccessFile(this.snapshotFile, "r")) {
RaftSnapshot raftSnapshot = new RaftSnapshot();
raftSnapshot.setLastIncludedTerm(latestSnapshotRaFile.readInt());
raftSnapshot.setLastIncludedIndex(latestSnapshotRaFile.readLong());
return raftSnapshot;
} catch (IOException e) {
throw new MyRaftException("readSnapshotNoData error",e);
} finally {
readLock.unlock();
}
}
public RaftSnapshot readSnapshot(){
logger.info("do readSnapshot");
if(this.snapshotFile.length() == 0){
logger.info("snapshotFile is empty!");
return null;
}
readLock.lock();
try(RandomAccessFile latestSnapshotRaFile = new RandomAccessFile(this.snapshotFile, "r")) {
logger.info("do readSnapshot");
RaftSnapshot latestSnapshot = new RaftSnapshot();
latestSnapshot.setLastIncludedTerm(latestSnapshotRaFile.readInt());
latestSnapshot.setLastIncludedIndex(latestSnapshotRaFile.readLong());
// 读取snapshot的实际数据(简单起见,暂不考虑快照太大内存溢出的问题,可以优化为按照偏移量多次读取)
byte[] snapshotData = new byte[(int) (this.snapshotFile.length() - actualDataOffset)];
latestSnapshotRaFile.read(snapshotData);
latestSnapshot.setSnapshotData(snapshotData);
logger.info("readSnapshot success! readSnapshot={}",latestSnapshot);
return latestSnapshot;
} catch (IOException e) {
throw new MyRaftException("readSnapshot error",e);
} finally {
readLock.unlock();
}
}
private String getSnapshotFileDir(){
return System.getProperty("user.dir")
+ File.separator + currentServer.getServerId()
+ File.separator + "snapshot";
}
}
2.2 日志压缩定时任务
- 相比lab2,lab3中MyRaft的日志模块新增加了一个定时任务,用于检查当前日志文件的大小是否超过了指定的阈值,如果超过了阈值则会触发生成新日志快照的逻辑。
和快照模块类似,考虑到日志文件压缩时可能宕机的问题,同样采用引入临时文件的方法解决。 - 生成快照的逻辑里先将新的快照通过SnapshotModule持久化,然后将当前已提交的日志从日志文件中删除掉。
日志文件是从前写到后的,直接操作原日志文件会比较麻烦和危险。因此MyRaft将所有未提交的日志写入一个新的临时日志文件后,再通过一次文件名的切换实现对已提交日志的删除。
/**
* 构建快照的检查
* */
private void buildSnapshotCheck() {
try {
if(!readLock.tryLock(1,TimeUnit.SECONDS)){
logger.info("buildSnapshotCheck lock fail, quick return!");
return;
}
} catch (InterruptedException e) {
throw new MyRaftException("buildSnapshotCheck tryLock error!",e);
}
try {
long logFileLength = this.logFile.length();
long logFileThreshold = currentServer.getRaftConfig().getLogFileThreshold();
if (logFileLength < logFileThreshold) {
logger.info("logFileLength not reach threshold, do nothing. logFileLength={},threshold={}", logFileLength, logFileThreshold);
return;
}
logger.info("logFileLength already reach threshold, start buildSnapshot! logFileLength={},threshold={}", logFileLength, logFileThreshold);
byte[] snapshot = currentServer.getKvReplicationStateMachine().buildSnapshot();
LogEntry lastCommittedLogEntry = readLocalLog(this.lastCommittedIndex);
RaftSnapshot raftSnapshot = new RaftSnapshot();
raftSnapshot.setLastIncludedTerm(lastCommittedLogEntry.getLogTerm());
raftSnapshot.setLastIncludedIndex(lastCommittedLogEntry.getLogIndex());
raftSnapshot.setSnapshotData(snapshot);
// 持久化最新的一份快照
currentServer.getSnapshotModule().persistentNewSnapshotFile(raftSnapshot);
}finally {
readLock.unlock();
}
try {
buildNewLogFileRemoveCommittedLog();
} catch (IOException e) {
logger.error("buildNewLogFileRemoveCommittedLog error",e);
}
}
/**
* 构建一个删除了已提交日志的新日志文件(日志压缩到快照里了)
* */
private void buildNewLogFileRemoveCommittedLog() throws IOException {
long lastCommitted = getLastCommittedIndex();
long lastIndex = getLastIndex();
// 暂不考虑读取太多日志造成内存溢出的问题
List<LocalLogEntry> logEntryList;
if(lastCommitted == lastIndex){
// (lastCommitted == lastIndex) 所有日志都提交了,创建一个空的新日志文件
logEntryList = new ArrayList<>();
}else{
// 还有日志没提交,把没提交的记录到新的日志文件中
logEntryList = readLocalLog(lastCommitted+1,lastIndex);
}
File tempLogFile = new File(getLogFileDir() + File.separator + logTempFileName);
MyRaftFileUtil.createFile(tempLogFile);
try(RandomAccessFile randomAccessTempLogFile = new RandomAccessFile(tempLogFile,"rw")) {
long currentOffset = 0;
for (LogEntry logEntry : logEntryList) {
// 写入日志
writeLog(randomAccessTempLogFile, logEntry, currentOffset);
currentOffset = randomAccessTempLogFile.getFilePointer();
}
this.currentOffset = currentOffset;
}
File tempLogMeteDataFile = new File(getLogFileDir() + File.separator + logMetaDataTempFileName);
MyRaftFileUtil.createFile(tempLogMeteDataFile);
// 临时的日志元数据文件写入数据
refreshMetadata(tempLogMeteDataFile,currentOffset);
writeLock.lock();
try{
// 先删掉原来的日志文件,然后把临时文件重名名为日志文件(delete后、重命名前可能宕机,但是没关系,重启后构造方法里做了对应处理)
this.logFile.delete();
boolean renameLogFileResult = tempLogFile.renameTo(this.logFile);
if(!renameLogFileResult){
logger.error("renameLogFile error!");
}
// 先删掉原来的日志元数据文件,然后把临时文件重名名为日志元数据文件(delete后、重命名前可能宕机,但是没关系,重启后构造方法里做了对应处理)
this.logMetaDataFile.delete();
boolean renameTempLogMeteDataFileResult = tempLogMeteDataFile.renameTo(this.logMetaDataFile);
if(!renameTempLogMeteDataFileResult){
logger.error("renameTempLogMeteDataFile error!");
}
}finally {
writeLock.unlock();
}
}
2.3 installSnapshot与日志复制时交互的改造
appendEntries日志同步逻辑leader侧的拓展
相比lab2,在引入了快照压缩功能后,leader侧的日志复制逻辑需要进行一点小小的拓展。
即当要向follower同步某一条日志时,对应日志可能已经被压缩掉了,因此此时需要改为使用installSnapshotRpc来完成快照的安装。

/**
* leader向集群广播,令follower复制新的日志条目
* */
public List<AppendEntriesRpcResult> replicationLogEntry(LogEntry lastEntry) {
List<RaftService> otherNodeInCluster = currentServer.getOtherNodeInCluster();
List<Future<AppendEntriesRpcResult>> futureList = new ArrayList<>(otherNodeInCluster.size());
for(RaftService node : otherNodeInCluster){
// 并行发送rpc,要求follower复制日志
Future<AppendEntriesRpcResult> future = this.rpcThreadPool.submit(()->{
logger.info("replicationLogEntry start!");
long nextIndex = this.currentServer.getNextIndexMap().get(node);
AppendEntriesRpcResult finallyResult = null;
// If last log index ≥ nextIndex for a follower: send AppendEntries RPC with log entries starting at nextIndex
while(lastEntry.getLogIndex() >= nextIndex){
AppendEntriesRpcParam appendEntriesRpcParam = new AppendEntriesRpcParam();
appendEntriesRpcParam.setLeaderId(currentServer.getServerId());
appendEntriesRpcParam.setTerm(currentServer.getCurrentTerm());
appendEntriesRpcParam.setLeaderCommit(this.lastCommittedIndex);
int appendLogEntryBatchNum = this.currentServer.getRaftConfig().getAppendLogEntryBatchNum();
// 要发送的日志最大index值
// (追进度的时候,就是nextIndex开始批量发送appendLogEntryBatchNum-1条(左闭右闭区间);如果进度差不多那就是以lastEntry.index为界限全部发送出去)
long logIndexEnd = Math.min(nextIndex+(appendLogEntryBatchNum-1), lastEntry.getLogIndex());
// 读取出[nextIndex-1,logIndexEnd]的日志(左闭右闭区间),-1往前一位是为了读取出preLog的信息
List<LocalLogEntry> localLogEntryList = this.readLocalLog(nextIndex-1,logIndexEnd);
logger.info("replicationLogEntry doing! nextIndex={},logIndexEnd={},LocalLogEntryList={}",
nextIndex,logIndexEnd,JsonUtil.obj2Str(localLogEntryList));
List<LogEntry> logEntryList = localLogEntryList.stream()
.map(LogEntry::toLogEntry)
.collect(Collectors.toList());
// 索引区间大小
long indexRange = (logIndexEnd - nextIndex + 1);
// 假设索引区间大小为N,可能有三种情况
// 1. 查出N条日志,所需要的日志全都在本地日志文件里没有被压缩
// 2. 查出1至N-1条日志,部分日志被压缩到快照里 or 就是只有那么多日志(一次批量查5条,但当前总共只写入了3条)
// 3. 查出0条日志,需要的日志全部被压缩了(因为是先落盘再广播,如果既没有日志也没有快照那就是有bug)
if(logEntryList.size() == indexRange+1){
// 查出了区间内的所有日志(case 1)
logger.info("find log size match!");
// preLog
LogEntry preLogEntry = logEntryList.get(0);
// 实际需要传输的log
List<LogEntry> needAppendLogList = logEntryList.subList(1,logEntryList.size());
appendEntriesRpcParam.setEntries(needAppendLogList);
appendEntriesRpcParam.setPrevLogIndex(preLogEntry.getLogIndex());
appendEntriesRpcParam.setPrevLogTerm(preLogEntry.getLogTerm());
}else if(logEntryList.size() > 0 && logEntryList.size() <= indexRange){
// 查出了部分日志(case 2)
// 新增日志压缩功能后,查出来的数据个数小于指定的区间不一定就是查到第一条数据,还有可能是日志被压缩了
logger.info("find log size not match!");
RaftSnapshot readSnapshotNoData = currentServer.getSnapshotModule().readSnapshotMetaData();
if(readSnapshotNoData != null){
logger.info("has snapshot! readSnapshotNoData={}",readSnapshotNoData);
// 存在快照,使用快照里保存的上一条日志信息
appendEntriesRpcParam.setPrevLogIndex(readSnapshotNoData.getLastIncludedIndex());
appendEntriesRpcParam.setPrevLogTerm(readSnapshotNoData.getLastIncludedTerm());
}else{
logger.info("no snapshot! prevLogIndex=-1, prevLogTerm=-1");
// 没有快照,说明恰好发送第一条日志记录(比如appendLogEntryBatchNum=5,但一共只有3条日志全查出来了)
// 第一条记录的prev的index和term都是-1
appendEntriesRpcParam.setPrevLogIndex(-1);
appendEntriesRpcParam.setPrevLogTerm(-1);
}
appendEntriesRpcParam.setEntries(logEntryList);
} else if(logEntryList.isEmpty()){
// 日志压缩把要同步的日志删除掉了,只能使用installSnapshotRpc了(case 3)
logger.info("can not find and log entry,maybe delete for log compress");
// 快照压缩导致leader更早的index日志已经不存在了
// 应该改为使用installSnapshot来同步进度
RaftSnapshot raftSnapshot = currentServer.getSnapshotModule().readSnapshot();
doInstallSnapshotRpc(node,raftSnapshot,currentServer);
// 走到这里,一般是成功的完成了快照的安装。目标follower目前已经有了包括lastIncludedIndex以及之前的所有日志
// 如果是因为成为follower快速返回,则再循环一次就结束了
nextIndex = raftSnapshot.getLastIncludedIndex() + 1;
continue;
} else{
// 走到这里不符合预期,日志模块有bug
throw new MyRaftException("replicationLogEntry logEntryList size error!" +
" nextIndex=" + nextIndex + " logEntryList.size=" + logEntryList.size());
}
logger.info("leader do appendEntries start, node={}, appendEntriesRpcParam={}",node,appendEntriesRpcParam);
AppendEntriesRpcResult appendEntriesRpcResult = node.appendEntries(appendEntriesRpcParam);
logger.info("leader do appendEntries end, node={}, appendEntriesRpcResult={}",node,appendEntriesRpcResult);
finallyResult = appendEntriesRpcResult;
// 收到更高任期的处理
boolean beFollower = currentServer.processCommunicationHigherTerm(appendEntriesRpcResult.getTerm());
if(beFollower){
return appendEntriesRpcResult;
}
if(appendEntriesRpcResult.isSuccess()){
logger.info("appendEntriesRpcResult is success, node={}",node);
// If successful: update nextIndex and matchIndex for follower (§5.3)
// 同步成功了,nextIndex递增一位
this.currentServer.getNextIndexMap().put(node,nextIndex+1);
this.currentServer.getMatchIndexMap().put(node,nextIndex);
nextIndex++;
}else{
// 因为日志对不上导致一致性检查没通过,同步没成功,nextIndex往后退一位
logger.info("appendEntriesRpcResult is false, node={}",node);
// If AppendEntries fails because of log inconsistency: decrement nextIndex and retry (§5.3)
nextIndex--;
this.currentServer.getNextIndexMap().put(node,nextIndex);
}
}
if(finallyResult == null){
// 说明有bug
throw new MyRaftException("replicationLogEntry finallyResult is null!");
}
logger.info("finallyResult={},node={}",node,finallyResult);
return finallyResult;
});
futureList.add(future);
}
// 获得结果
List<AppendEntriesRpcResult> appendEntriesRpcResultList = CommonUtil.concurrentGetRpcFutureResult(
"do appendEntries", futureList,
this.rpcThreadPool,2, TimeUnit.SECONDS);
logger.info("leader replicationLogEntry appendEntriesRpcResultList={}",appendEntriesRpcResultList);
return appendEntriesRpcResultList;
}
appendEntries日志同步逻辑follower侧的拓展
前面提到,follower侧在进行日志一致性校验时,也可能出现恰好前一条日志被压缩到快照里的情况。
因此需要在当前日志不存在时,尝试通过SnapshotModule读取快照数据中的前一条日志信息来进行比对。
public AppendEntriesRpcResult appendEntries(AppendEntriesRpcParam appendEntriesRpcParam) {
if(appendEntriesRpcParam.getTerm() < this.raftServerMetaDataPersistentModule.getCurrentTerm()){
// Reply false if term < currentTerm (§5.1)
// 拒绝处理任期低于自己的老leader的请求
logger.info("doAppendEntries term < currentTerm");
return new AppendEntriesRpcResult(this.raftServerMetaDataPersistentModule.getCurrentTerm(),false);
}
if(appendEntriesRpcParam.getTerm() >= this.raftServerMetaDataPersistentModule.getCurrentTerm()){
// appendEntries请求中任期值如果大于自己,说明已经有一个更新的leader了,自己转为follower,并且以对方更大的任期为准
this.serverStatusEnum = ServerStatusEnum.FOLLOWER;
this.currentLeader = appendEntriesRpcParam.getLeaderId();
this.raftServerMetaDataPersistentModule.setCurrentTerm(appendEntriesRpcParam.getTerm());
}
if(appendEntriesRpcParam.getEntries() == null || appendEntriesRpcParam.getEntries().isEmpty()){
// 来自leader的心跳处理,清理掉之前选举的votedFor
this.cleanVotedFor();
// entries为空,说明是心跳请求,刷新一下最近收到心跳的时间
raftLeaderElectionModule.refreshLastHeartbeatTime();
long currentLastCommittedIndex = logModule.getLastCommittedIndex();
logger.debug("doAppendEntries heartbeat leaderCommit={},currentLastCommittedIndex={}",
appendEntriesRpcParam.getLeaderCommit(),currentLastCommittedIndex);
if(appendEntriesRpcParam.getLeaderCommit() > currentLastCommittedIndex) {
// 心跳处理里,如果leader当前已提交的日志进度超过了当前节点的进度,令当前节点状态机也跟上
// 如果leaderCommit >= logModule.getLastIndex(),说明当前节点的日志进度不足,但可以把目前已有的日志都提交给状态机去执行
// 如果leaderCommit < logModule.getLastIndex(),说明当前节点进度比较快,有一些日志是leader已复制但还没提交的,把leader已提交的那一部分作用到状态机就行
long minNeedCommittedIndex = Math.min(appendEntriesRpcParam.getLeaderCommit(), logModule.getLastIndex());
pushStatemachineApply(minNeedCommittedIndex);
}
// 心跳请求,直接返回
return new AppendEntriesRpcResult(this.raftServerMetaDataPersistentModule.getCurrentTerm(),true);
}
// logEntries不为空,是真实的日志复制rpc
logger.info("do real log append! appendEntriesRpcParam={}",appendEntriesRpcParam);
// AppendEntry可靠性校验,如果prevLogIndex和prevLogTerm不匹配,则需要返回false,让leader发更早的日志过来
{
LogEntry localPrevLogEntry = logModule.readLocalLog(appendEntriesRpcParam.getPrevLogIndex());
if(localPrevLogEntry == null){
// 没有查到prevLogIndex对应的日志,分两种情况
RaftSnapshot raftSnapshot = snapshotModule.readSnapshotMetaData();
localPrevLogEntry = new LogEntry();
if(raftSnapshot == null){
// 当前节点日志条目为空,又没有快照,说明完全没有日志(默认任期为-1,这个是约定)
localPrevLogEntry.setLogIndex(-1);
localPrevLogEntry.setLogTerm(-1);
}else{
// 日志里没有,但是有快照(把快照里记录的最后一条日志信息与leader的参数比对)
localPrevLogEntry.setLogIndex(raftSnapshot.getLastIncludedIndex());
localPrevLogEntry.setLogTerm(raftSnapshot.getLastIncludedTerm());
}
}
if (localPrevLogEntry.getLogTerm() != appendEntriesRpcParam.getPrevLogTerm()) {
// Reply false if log doesn’t contain an entry at prevLogIndex
// whose term matches prevLogTerm (§5.3)
// 本地日志和参数中的PrevLogIndex和PrevLogTerm对不上(对应日志不存在,或者任期对不上)
logger.info("doAppendEntries localPrevLogEntry not match, localLogEntry={}",localPrevLogEntry);
return new AppendEntriesRpcResult(this.raftServerMetaDataPersistentModule.getCurrentTerm(),false);
}
}
// 走到这里说明找到了最新的一条匹配的记录
logger.info("doAppendEntries localEntry is match");
List<LogEntry> newLogEntryList = appendEntriesRpcParam.getEntries();
// 1. Append any new entries not already in the log
// 2. If an existing entry conflicts with a new one (same index but different terms),
// delete the existing entry and all that follow it (§5.3)
// 新日志的复制操作(直接整个覆盖掉prevLogIndex之后的所有日志,以leader发过来的日志为准)
logModule.writeLocalLog(newLogEntryList, appendEntriesRpcParam.getPrevLogIndex());
// If leaderCommit > commitIndex, set commitIndex = min(leaderCommit, index of last new entry)
if(appendEntriesRpcParam.getLeaderCommit() > logModule.getLastCommittedIndex()){
// 如果leaderCommit更大,说明当前节点的同步进度慢于leader,以新的entry里的index为准(更高的index还没有在本地保存(因为上面的appendEntry有效性检查))
// 如果index of last new entry更大,说明当前节点的同步进度是和leader相匹配的,commitIndex以leader最新提交的为准
LogEntry lastNewEntry = newLogEntryList.get(newLogEntryList.size()-1);
long lastCommittedIndex = Math.min(appendEntriesRpcParam.getLeaderCommit(), lastNewEntry.getLogIndex());
pushStatemachineApply(lastCommittedIndex);
}
// 返回成功
return new AppendEntriesRpcResult(this.raftServerMetaDataPersistentModule.getCurrentTerm(), true);
}
leader侧快照安装installSnapshot逻辑
- MyRaft中,leader侧安装快照的方法实现的比较简单,未考虑快照可能很大的情况,所以直接一股脑将整个快照文件全部读取到内存中来了(在向多个follower并发安装快照时会占用很多的内存,待优化)。
- 在将快照读取到内存中后,通过一个循环将快照数据按照配置的block大小逐步的发送给follower。在发送完最后一个block数据后,rpc请求参数的done属性会被设置为true标识为同步完成。
public static void doInstallSnapshotRpc(RaftService targetNode, RaftSnapshot raftSnapshot, RaftServer currentServer){
int installSnapshotBlockSize = currentServer.getRaftConfig().getInstallSnapshotBlockSize();
byte[] completeSnapshotData = raftSnapshot.getSnapshotData();
int currentOffset = 0;
while(true){
InstallSnapshotRpcParam installSnapshotRpcParam = new InstallSnapshotRpcParam();
installSnapshotRpcParam.setLastIncludedIndex(raftSnapshot.getLastIncludedIndex());
installSnapshotRpcParam.setTerm(currentServer.getCurrentTerm());
installSnapshotRpcParam.setLeaderId(currentServer.getServerId());
installSnapshotRpcParam.setLastIncludedTerm(raftSnapshot.getLastIncludedTerm());
installSnapshotRpcParam.setOffset(currentOffset);
// 填充每次传输的数据块
int blockSize = Math.min(installSnapshotBlockSize,completeSnapshotData.length-currentOffset);
byte[] block = new byte[blockSize];
System.arraycopy(completeSnapshotData,currentOffset,block,0,blockSize);
installSnapshotRpcParam.setData(block);
currentOffset += installSnapshotBlockSize;
if(currentOffset >= completeSnapshotData.length){
installSnapshotRpcParam.setDone(true);
}else{
installSnapshotRpcParam.setDone(false);
}
InstallSnapshotRpcResult installSnapshotRpcResult = targetNode.installSnapshot(installSnapshotRpcParam);
boolean beFollower = currentServer.processCommunicationHigherTerm(installSnapshotRpcResult.getTerm());
if(beFollower){
// 传输过程中发现自己已经不再是leader了,快速结束
logger.info("doInstallSnapshotRpc beFollower quick return!");
return;
}
if(installSnapshotRpcParam.isDone()){
// 快照整体安装完毕
logger.info("doInstallSnapshotRpc isDone!");
return;
}
}
}
follower侧处理installSnapshot逻辑
- follower侧处理快照安装rpc的逻辑中,除了必要的对参数term大小的检查,就是简单的通过SnapshotModule完成快照的安装工作。
- 在快照整体成功安装完成后,通过LogModule.compressLogBySnapshot方法将所有已提交的日志全都删除掉,并将之前安装好的快照整体作用到follower自己本地的状态机中。
public InstallSnapshotRpcResult installSnapshot(InstallSnapshotRpcParam installSnapshotRpcParam) {
logger.info("installSnapshot start! serverId={},installSnapshotRpcParam={}",this.serverId,installSnapshotRpcParam);
if(installSnapshotRpcParam.getTerm() < this.raftServerMetaDataPersistentModule.getCurrentTerm()){
// Reply immediately if term < currentTerm
// 拒绝处理任期低于自己的老leader的请求
logger.info("installSnapshot term < currentTerm");
return new InstallSnapshotRpcResult(this.raftServerMetaDataPersistentModule.getCurrentTerm());
}
// 安装快照
this.snapshotModule.appendInstallSnapshot(installSnapshotRpcParam);
// 快照已经完全安装好了
if(installSnapshotRpcParam.isDone()){
// discard any existing or partial snapshot with a smaller index
// 快照整体安装完毕,清理掉index小于等于快照中lastIncludedIndex的所有日志(日志压缩)
logModule.compressLogBySnapshot(installSnapshotRpcParam);
// Reset state machine using snapshot contents (and load snapshot’s cluster configuration)
// follower的状态机重新安装快照
RaftSnapshot raftSnapshot = this.snapshotModule.readSnapshot();
kvReplicationStateMachine.installSnapshot(raftSnapshot.getSnapshotData());
}
logger.info("installSnapshot end! serverId={}",this.serverId);
return new InstallSnapshotRpcResult(this.raftServerMetaDataPersistentModule.getCurrentTerm());
}
/**
* discard any existing or partial snapshot with a smaller index
* 快照整体安装完毕,清理掉index小于等于快照中lastIncludedIndex的所有日志
* */
public void compressLogBySnapshot(InstallSnapshotRpcParam installSnapshotRpcParam){
this.lastCommittedIndex = installSnapshotRpcParam.getLastIncludedIndex();
if(this.lastIndex < this.lastCommittedIndex){
this.lastIndex = this.lastCommittedIndex;
}
try {
buildNewLogFileRemoveCommittedLog();
} catch (IOException e) {
throw new MyRaftException("compressLogBySnapshot error",e);
}
}
3. MyRaft日志压缩测试case
和lab2中一样,通过启动一个raft集群并触发几个case可以验证MyRaft日志压缩功能的正确性。
- 启动5个节点,关闭快照压缩功能,正常的进行写入操作。
=> 状态机/日志文件的数据是否符合预期 - 启动5个节点,开启快照压缩功能,正常的进行写入操作,当日志文件超过阈值触发日志压缩后。
=> 状态机/日志文件/快照文件的数据是否符合预期 - 启动5个节点,开启快照压缩功能,正常的进行写入操作,主动关闭一个节点。再进行一些写入,令leader生成最新的快照,然后让宕机的节点回到集群,看leader是否通过快照安装来完成快照/日志的同步。
=> 状态机/日志文件/快照文件的数据是否符合预期
总结
- 作为手写raft系列博客的第三篇,也是目前计划中的最后一篇博客(集群动态变更功能暂不实现)。博客中介绍了Raft的日志压缩功能以及从源码层面上分析MyRaft实现日志压缩功能的细节。
- raft是一个相对复杂的算法,因此MyRaft在功能实现上为了追求实现的简单性,舍弃了很多性能方面的优化(比如一把全局大锁防并发,快照数据完整放到内存中处理等等)。
同时分布式系统中处处有并发、机器也时刻可能宕机,需要考虑的细节繁多。所以MyRaft即使通过了我自己设计的一些单测和集成测试的case,但肯定还存在许多尚未被发现bug,还请多多指教。 - 博客中展示的完整代码在我的github上:https://github.com/1399852153/MyRaft (release/lab3_log_compaction分支),希望能帮助到对raft算法感兴趣的小伙伴。
手写raft(三) 实现日志压缩的更多相关文章
- TensorFlow 入门之手写识别CNN 三
TensorFlow 入门之手写识别CNN 三 MNIST 卷积神经网络 Fly 多层卷积网络 多层卷积网络的基本理论 构建一个多层卷积网络 权值初始化 卷积和池化 第一层卷积 第二层卷积 密集层连接 ...
- MIT 6.824 Lab2D Raft之日志压缩
书接上文Raft Part C | MIT 6.824 Lab2C Persistence. 实验准备 实验代码:git://g.csail.mit.edu/6.824-golabs-2021/src ...
- 使用神经网络来识别手写数字【译】(三)- 用Python代码实现
实现我们分类数字的网络 好,让我们使用随机梯度下降和 MNIST训练数据来写一个程序来学习怎样识别手写数字. 我们用Python (2.7) 来实现.只有 74 行代码!我们需要的第一个东西是 MNI ...
- opencv 手写选择题阅卷 (三)训练分类器
opencv 手写选择题阅卷 (三)训练分类器 1,分类器选择:SVM 本来一开始用的KNN分类器,但这个分类器目前没有实现保存训练数据的功能,所以选择了SVN分类器; 2,样本图像的预处理和特征提取 ...
- 手写JAVA虚拟机(三)——搜索class文件并读出内容
查看手写JAVA虚拟机系列可以进我的博客园主页查看. 前面我们介绍了准备工作以及命令行的编写.既然我们的任务实现命令行中的java命令,同时我们知道java命令是将class文件(字节码)转换成机器码 ...
- 【TensorFlow-windows】(三) 多层感知器进行手写数字识别(mnist)
主要内容: 1.基于多层感知器的mnist手写数字识别(代码注释) 2.该实现中的函数总结 平台: 1.windows 10 64位 2.Anaconda3-4.2.0-Windows-x86_64. ...
- 手写DAO框架(三)-数据库连接
-------前篇:手写DAO框架(二)-开发前的最后准备--------- 前言 上一篇主要是温习了一下基础知识,然后将整个项目按照模块进行了划分.因为是个人项目,一个人开发,本人采用了自底向上的开 ...
- 手写MQ框架(三)-客户端实现
一.背景 书接手写MQ框架(二)-服务端实现 ,前面介绍了服务端的实现.但是具体使用框架过程中,用户肯定是以客户端的形式跟服务端打交道的.客户端的好坏直接影响了框架使用的便利性. 虽然框架目前是通过 ...
- GAN实战笔记——第三章第一个GAN模型:生成手写数字
第一个GAN模型-生成手写数字 一.GAN的基础:对抗训练 形式上,生成器和判别器由可微函数表示如神经网络,他们都有自己的代价函数.这两个网络是利用判别器的损失记性反向传播训练.判别器努力使真实样本输 ...
- 用Keras搭建神经网络 简单模版(三)—— CNN 卷积神经网络(手写数字图片识别)
# -*- coding: utf-8 -*- import numpy as np np.random.seed(1337) #for reproducibility再现性 from keras.d ...
随机推荐
- Vulnhub Broken
Vulnhub Broken 一.操作文档 [Vulnhub - Broken-Gallery writeup (mzfr.me)](https://blog.mzfr.me/vulnhub-writ ...
- Jenkins(1)-安装教程
我用的服务器是阿里云服务器, 服务器系统: CentOS7.9, 不同的操作系统需要下载不同的软件包, 对应的链接如下https://www.jenkins.io/zh/download/ 1) 软件 ...
- Java的运算符和表达式(基础语法学习)
一.运算符 在Java中用于程序计算的操作符统称为运算符,运算符分为如下几类 1.算数运算符 运算符 说明 + 加号两边是数值,可以运算,如果一边存在字符串,则当作连接符 a+b - 两个数相加, ...
- 配置VsCode的QT工程
配置VsCode的QT工程 VsCode + qmake 环境(Environment): Windows11 Qt5.12.11+ MinGW64 编译套件 VsCode (version = 1. ...
- wait,notify,notifyAll,sleep,join等线程方法的全方位演练
一.概念解释 1. 进入阻塞: 有时我们想让一个线程或多个线程暂时去休息一下,可以使用 wait(),使线程进入到阻塞状态,等到后面用到它时,再使用notify().notifyAll() 唤醒它,线 ...
- 深入分析Go语言与C#的异同
摘要:本文由葡萄城技术团队于博客园原创并首发.转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具.解决方案和服务,赋能开发者. 前言 为了更加深入地介绍Go语言以及与C#语言的比较,本文将会 ...
- CMU15445 (Fall 2020) 数据库系统 Project#4 - Concurrency Control 详解
前言 一个合格的事务处理系统,应该具备四个性质:原子性(atomicity).一致性(consistency).隔离性(isolation)和持久性(durability).隔离性保证了一个活跃的事务 ...
- 前端检测手机系统是iOS还是android(可实现根据手机系统跳转App下载链接)
快速实现前端检测手机系统是iOS还是android(可实现根据手机系统跳转App下载链接); 下载完整代码请访问uni-app插件市场地址:https://ext.dcloud.net.cn/plug ...
- 楠少音乐盒(PC端)突破校园网限制
楠少音乐盒 突破校园网限制 最近在将音乐盒从web迁移到PC端,过程中的记录 在我们学校,工作时间内(周一至周五为工作日,下午上班时间)校园网都会拦截一些与工作无关的网站,例如购物.炒股.游戏.音乐等 ...
- Containerd组件 —— containerd-shim-runc-v2作用
1.概述 通过<浅析开源容器标准--OCI>.<浅析容器运行时>和<浅析Kubernetes CRI>这三篇博文我们了解了容器标准OCI.容器运行时以及Kubern ...