OREPA:阿里提出训练也很快的重参数策略,内存减半,速度加倍 | CVPR 2022
论文提出了在线重参数方法OREPA,在训练阶段就能将复杂的结构重参数为单卷积层,从而降低大量训练的耗时。为了实现这一目标,论文用线性缩放层代替了训练时的BN层,保持了优化方向的多样性和特征表达能力。从实验结果来看,OREPA在各种任务上的准确率和效率都很不错
来源:晓飞的算法工程笔记 公众号
论文: Online Convolutional Re-parameterization

Introduction
除了准确率外,模型的推理速度也是很重要的。为了获得部署友好且精度高的模型,近期很多研究提出基于结构重参数化来提高模型性能。用于结构重参数化的模型在训练阶段和推理阶段具有不同的结构,训练时使用复杂的结构来获得高精度,而训练后通过等效变换将一个复杂的结构压缩成能够快速推理的线性层。压缩后的模型通常具有简洁的架构,例如类似VGG的或类似ResNet的结构。从这个角度来看,重参数化策略可以在不引入额外推理时间成本的情况下提高模型性能。公众号之前发了RepVGG的论文解读《RepVGG:VGG,永远的神! | 2021新文》,有兴趣可以去看看。
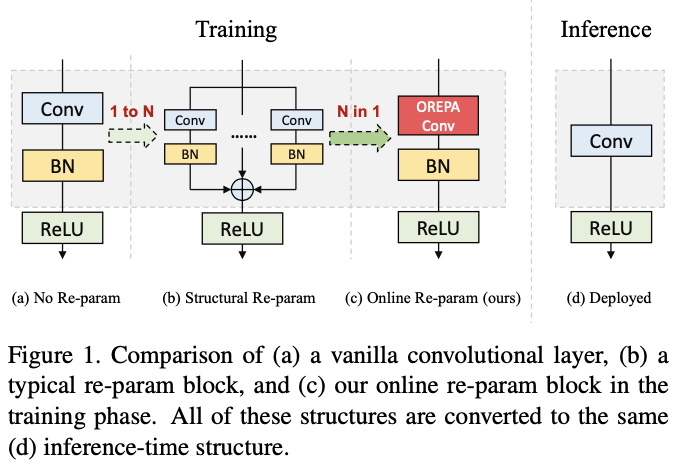
BN层是重参数模型中的关键组成部分,在每个卷积层之后添加一个BN层,如果图1b所示,移除BN层会导致严重的精度下降。在推理阶段,复杂的结构可以被压缩到单个卷积层中。而在训练阶段,由于BN层需要非线性地将特征图除以其标准差,只能单独计算每个分支。因此,存在大量中间计算操作(大FLOPS)和缓冲特征图(高内存使用),带来巨大的计算开销。更糟糕的是,高额的训练消耗阻碍了探索更复杂和可能更强大的重新参数结构。
为什么BN层对重参数化如此重要?根据实验和分析,论文发现BN层中的缩放因子能够使不同分支的优化方向多样化。基于这个发现,论文提出了在线重参数化方法OREPA,如图1c所示,包含两个步骤:
- block linearization:去掉所有非线性泛化层,转而引入线性缩放层。线性缩放层不仅能与BN层一样使不同分支的优化方向多样化,还可以在训练时合并计算。
- block squeezing:将复杂的线性结构简化为单个卷积层。
OREPA减少了由中间层引起的计算和存储开销,能够显著降低训练消耗(65%-75%显存节省、加速1.5-2.3倍)且对性能的影响很小,使得探索更复杂的重参数化结果成为可能。为了验证这一点,论文进一步提出了几个重新参数化的组件以获得更好的性能。
论文的贡献包含以下三点:
- 提出在线重参数化方法OREPA,能够大幅提高重参数化模型的训练效率,使得探索更强的重参数结构成为可能。
- 根据对重参数模型原理的分析,将BN层替换为线性缩放层,保持优化方向多样化特性和特征表达能力。
- 通过各种视觉任务实验表明,OREPA在准确率和训练效率方面都优于以前的重参数化模型。
Online Re-Parameterization
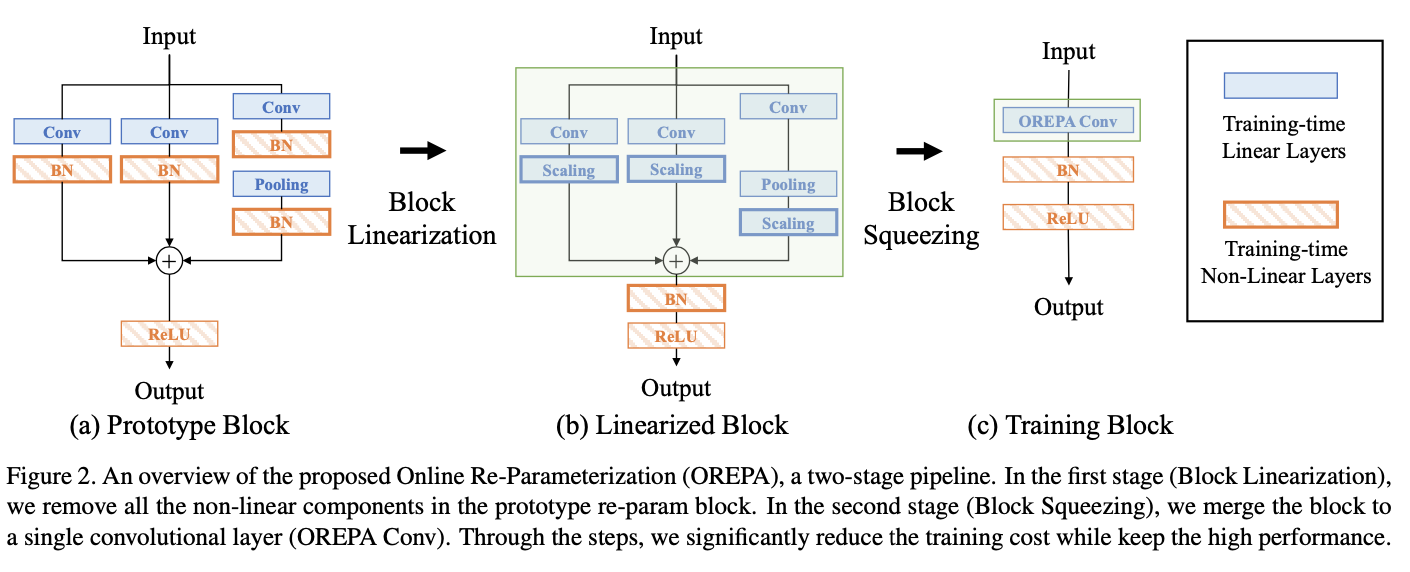
OREPA能够将训练期间的复杂结构简化为单一卷积层,维持准确率不变。OREPA的变换流程如图2所示,包含block linearization和block squeezing两个步骤。
Preliminaries: Normalization in Re-param
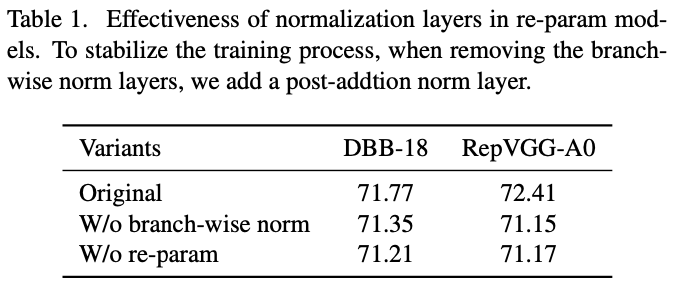
BN层是重参数中多层和多分支结构的关键结构,是重参数模型性能的基础。以DBB和RepVGG为例,去掉BN层后(改为多分支后统一进行BN操作)性能会有明显的下降,如表1所示。
比较意外的是,BN层的使用会带来过高的训练消耗。在推理阶段,重参数结构中的所有中间操作都是线性的,可以进行合并计算。而在训练阶段,由于BN层是非线性的(需要除以特征图的标准差),无法进行合并计算。无法合并就会导致中间操作需要单独计算,产生巨大的计算消耗和内存成本。而且,过高的成本也阻碍了更复杂的结构的探索。
Block Linearization
虽然BN层阻止了训练期间的合并计算,但由于准确率问题,仍然不能直接将其删除。为了解决这个问题,论文引入了channel-wise的线性缩放作为BN层的线性替换,通过可学习的向量进行特征图的缩放。线性缩放层具有BN层的类似效果,引导多分支向不同方向进行优化,这是重参数化性能的核心。
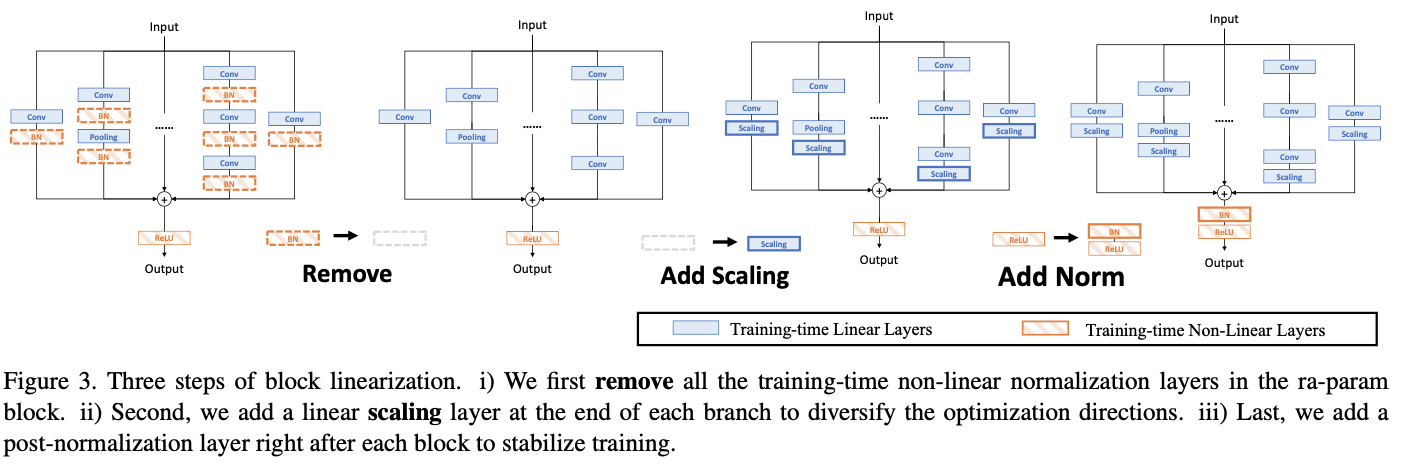
基于线性缩放层,对重参数化结构进行修改,如图3所示,以下三个步骤:
- 移除所有非线性层,即重参数化结构中的归一化层。
- 为了保持优化的多样性,在每个分支的末尾添加了一个缩放层,即BN层的线性替代。
- 为了稳定训练过程,在所有分支之后添加一个BN层。
经过block linearization操作后,重参数结构中就只存在线性层,这意味着可以在训练阶段合并结构中的所有组件。
Block Squeezing
Block squeezing将计算和内存过多的中间特征图上的操作转换为更快捷的单个卷积核核操作,这意味着在计算和内存方面将重参数的额外训练成本从\(O(H\times W)\)减少到\(O(KH\times KW )\),其中\((KH, KW)\)是卷积核的形状。
一般来说,无论线性重参数结构多复杂,以下两个属性都始终成立:
- 重参数结构中的所有线性层(例如深度卷积、平均池化和建议的线性缩放)都可以用具有相应参数的卷积层来表示,具体证明可以看原文的附录。
- 重参数结构可表示为一组并行分支,每个分支包含一串卷积层。

有了上述两个属性,就以将多层(即顺序结构)和多分支(即并行结构)压缩为单个卷积,如图4a和图4b所示。原文有部分转换的公式证明,有兴趣的可以去看看原文对应章节,这块不影响对Block Squeezing的思想的理解。
Gradient Analysis on Multi-branch Topology
论文从梯度回传的角度对多分支与block linearization的作用进行了分析,里面包含了部分公式推导,有兴趣的可以去看看原文对应章节。这里总结主要的两个结论:
- 如果使用分支共享的block linearization,多分支的优化方向和幅度与单分支一样。
- 如果使用分支独立的block linearization,多分支的优化方向和幅度与单分支不同。
上面的结论表明了block linearization步骤的重要性。当去掉BN层后,缩放层能够保持优化方向的多样化,避免多分支退化为单分支。
Block Design
由于OREPA节省了大量训练消耗,为探索更复杂的训练结构提供了可能性。论文基于DBB设计了全新的重参数模块OREPA-ResNet,加入了以下组件:
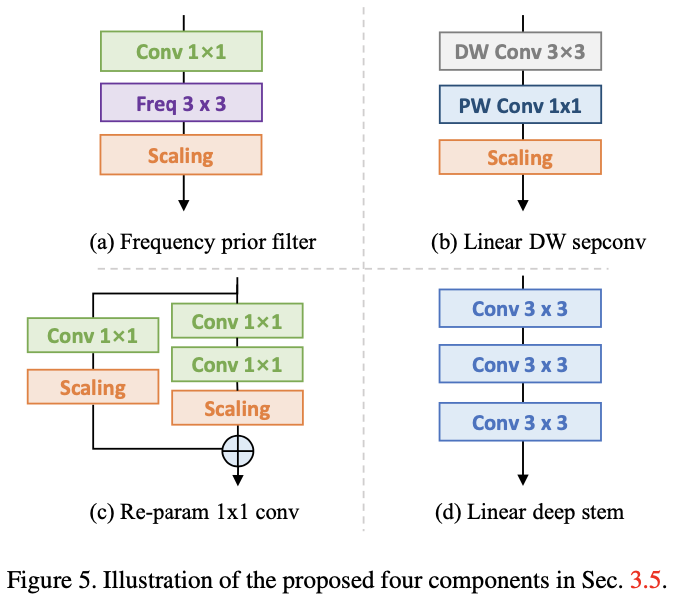
- Frequency prior filter:Fcanet指出池化层是频域滤波的一个特例,参考此工作加入1x1卷积+频域滤波分支。
- Linear depthwise separable convolution:对深度可分离卷积进行少量修改,去掉中间的非线性激活以便在训练期间合并。
- Re-parameterization for 1x1 convolution:之前的研究主要关注3×3卷积层的重参数而忽略了1×1卷积,但1x1卷积在bottleneck结构中十分重要。其次,论文添加了一个额外的1x1卷积+1x1卷积分支,对1x1卷积也进行重参数。
- Linear deep stem:一般网络采用7x7卷积+3x3卷积作为stem,有的网络将其替换为堆叠的3个3x3卷积取得了不错的准确率。但论文认为这样的堆叠设计在开头的高分辨率特征图上的计算消耗非常高,为此将3个3x3卷积与论文提出的线性层一起压缩为单个7x7卷积层,能够大幅降低计算消耗并保存准确率。
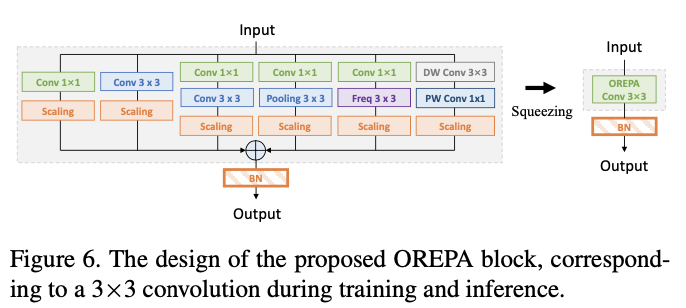
OREPA-ResNet中的block设计如图6所示,这应该是一个下采样的block,最终被合并成单个3x3卷积进行训练和推理。
Experiment
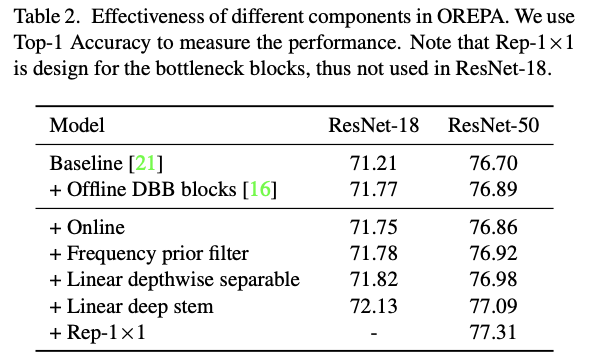
各组件对比实验。
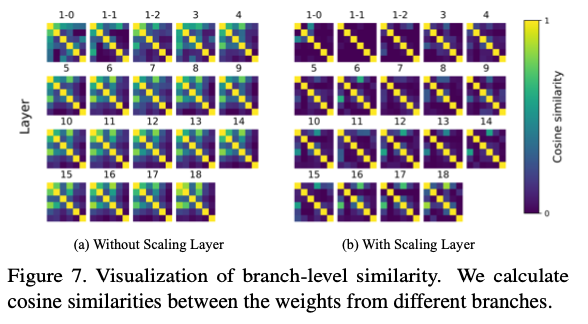
缩放层对各层各分支的相似性的影响。

线性缩放策略对比,channel-wise的缩放最好。
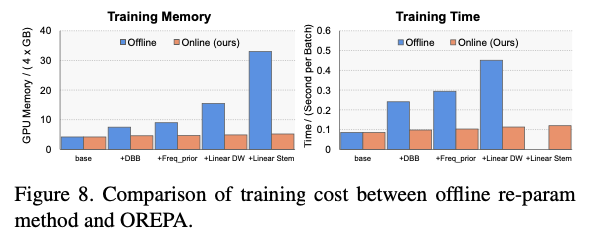
在线和离线重参数的训练耗时对比。
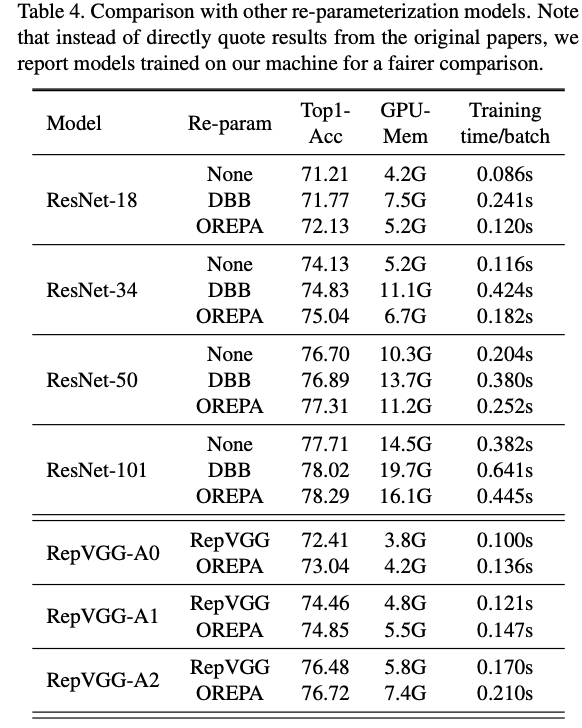
与其他重参数策略进行对比。
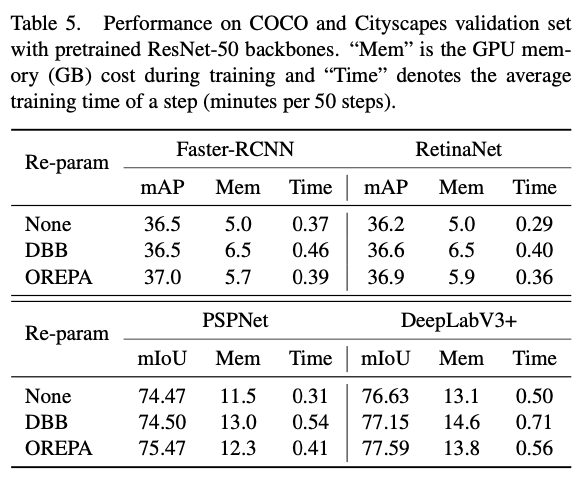
在检测和分割任务上进行对比。
Conclusion
论文提出了在线重参数方法OREPA,在训练阶段就能将复杂的结构重参数为单卷积层,从而降低大量训练的耗时。为了实现这一目标,论文用线性缩放层代替了训练时的BN层,保持了优化方向的多样性和特征表达能力。从实验结果来看,OREPA在各种任务上的准确率和效率都很不错。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

OREPA:阿里提出训练也很快的重参数策略,内存减半,速度加倍 | CVPR 2022的更多相关文章
- 变分贝叶斯学习(variational bayesian learning)及重参数技巧(reparameterization trick)
摘要:常规的神经网络权重是一个确定的值,贝叶斯神经网络(BNN)中,将权重视为一个概率分布.BNN的优化常常依赖于重参数技巧(reparameterization trick),本文对该优化方法进行概 ...
- PDO之MySql持久化自动重连导致内存溢出
前言 最近项目需要一个常驻内存的脚本来执行队列程序,脚本完成后发现Mysql自动重连部分存在内存溢出,导致运行一段时间后,会超出PHP内存限制退出 排查 发现脚本存在内存溢出后排查了一遍代码,基本确认 ...
- JMM中的重排序及内存屏障
目录 1. 概述 2. 重排序 2-1. as-if-serial语义 2-2. 重排序的种类 2-3. 从Java源代码到最终实际执行的指令序列, 会分别经历下面3中重排序. 3. 内存屏障类型 3 ...
- ACNet: 特别的想法,腾讯提出结合注意力卷积的二叉神经树进行细粒度分类 | CVPR 2020
论文提出了结合注意力卷积的二叉神经树进行弱监督的细粒度分类,在树结构的边上结合了注意力卷积操作,在每个节点使用路由函数来定义从根节点到叶子节点的计算路径,结合所有叶子节点的预测值进行最终的预测,论文的 ...
- 深度学习训练过程中的学习率衰减策略及pytorch实现
学习率是深度学习中的一个重要超参数,选择合适的学习率能够帮助模型更好地收敛. 本文主要介绍深度学习训练过程中的6种学习率衰减策略以及相应的Pytorch实现. 1. StepLR 按固定的训练epoc ...
- Tensorflow使用训练好的模型进行测试,发现计算速度越来越慢
实验时要对多个NN模型进行对比,依次加载直到第8个模型时,发现运行速度明显变慢而且电脑开始卡顿,查看内存占用90+%. 原因:使用过的NN模型还会保存在内存,继续加载一方面使新模型加载特别特别慢,另一 ...
- 牛客网编程练习(华为机试在线训练)-----求int型正整数在内存中存储时1的个数
题目描述 输入一个int型的正整数,计算出该int型数据在内存中存储时1的个数. 输入描述: 输入一个整数(int类型) 输出描述: 这个数转换成2进制后,输出1的个数 示例1 输入 5 输出 2 P ...
- Gumbel-Softmax Trick和Gumbel分布
之前看MADDPG论文的时候,作者提到在离散的信息交流环境中,使用了Gumbel-Softmax estimator.于是去搜了一下,发现该技巧应用甚广,如深度学习中的各种GAN.强化学习中的A2 ...
- jetson nano开发使用的基础详细分享
前言: 最近拿到一块jetson nano 2GB版本的板子,折腾了一下,从烧录镜像.修改配件等,准备一篇开箱基础文章给大家介绍一下这块AI开发板. 作者:良知犹存 转载授权以及围观:欢迎关注微信公众 ...
- 阿里、百度等多家公司Java面试记录与总结
算算自己大概面试了近十家公司,也拿到了几个Offer,现在面试告一段落,简单总结下面试经验. 我现在主要的方向是Java服务端开发,把遇到的问题和大家分享一下,也谈谈关于技术人员如何有方向的提高自己, ...
随机推荐
- Vue实现简单图书管理例子
以下内容整理自网络. 说明 本例主要涵盖以下知识点: 数据绑定 条件与循环 计算属性 监听器 过滤器 常见数组和对象操作 vue生命周期 示例演示 代码 <!DOCTYPE html> & ...
- 在PL/SQL中使用日期类型
在PL/SQL中使用日期类型 之前的文章介绍了在PL/SQL中使用字符串和数字了下.毫无疑问,字符串和数字很重要,但是可以确定的是没有哪个应用不依赖于日期的. 你需要记录事件的发生事件,人们的出生日期 ...
- zTree如何实现模糊查找实战
1.说明 最近在研究zTree树控件.过程中涉及到了实现模糊查找结点的功能,特此分享一下. 有关zTree的有关介绍和使用,请访问其官网:zTree -- jQuery 树插件 本文假设你已经比较熟悉 ...
- DFS算法模板(2488:A Knight's Journey)
DFS算法(C++版本) 题目一: 链接:http://bailian.openjudge.cn/practice/2488/ 解析思路: 骑士找路就是基本的DFS,用递归不断找到合适的路,找不到就回 ...
- 本地启动RocketMQ未映射主机名产生的超时问题
问题描述 参考RocketMQ官方文档在本地启动一个验证环境的时候遇到超时报错问题. 本地环境OS:CentOS Linux release 8.5.2111 首先,进入到RocketMQ安装目录,如 ...
- 基于javaweb的服装租赁网站
演示 技术+环境+工具 jdk8+maven.3.2.1+mysql5.7+idea+navicat+spring+springmvc+mybatis+bootstrap+jquery+ajax
- 【Azure Redis 缓存】Azure Redis加入VNET后,在另一个区域(如中国东部二区)的VNET无法访问Redis服务(注:两个VNET已经结对,相互之间可以互ping)
问题描述 为了保护Redis资源,把它与VNET集成后,实现只能通过VNET内网访问.在东二的区域中部署两个Redis服务后,发现一个奇怪的现象:东1区中的VM资源通过全局对等互联(Peering)实 ...
- HashMap很美好,但线程不安全怎么办?ConcurrentHashMap告诉你答案!
写在开头 在<耗时2天,写完HashMap>这篇文章中,我们提到关于HashMap线程不安全的问题,主要存在如下3点风险: 风险1: put的时候导致元素丢失:如两个线程同时put,且ke ...
- 千卡利用率超98%,详解JuiceFS在权威AI测试中的实现策略
2023 年 9 月,AI 领域的权威基准评测 MLPerf 推出了 Storage Benchmark.该基准测试通过模拟机器学习 I/O 负载的方法,在不需要 GPU 的情况下就能进行大规模的性能 ...
- 使用OpenFeign远程调用时请求头处理报错问题
1. 错误信息 basic.result.exception.OtherException: feign error:系统异常:Content type 'multipart/form-data;bo ...