10亿数据、查询<10s,论基于OLAP搭建广告系统的正确姿势
更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
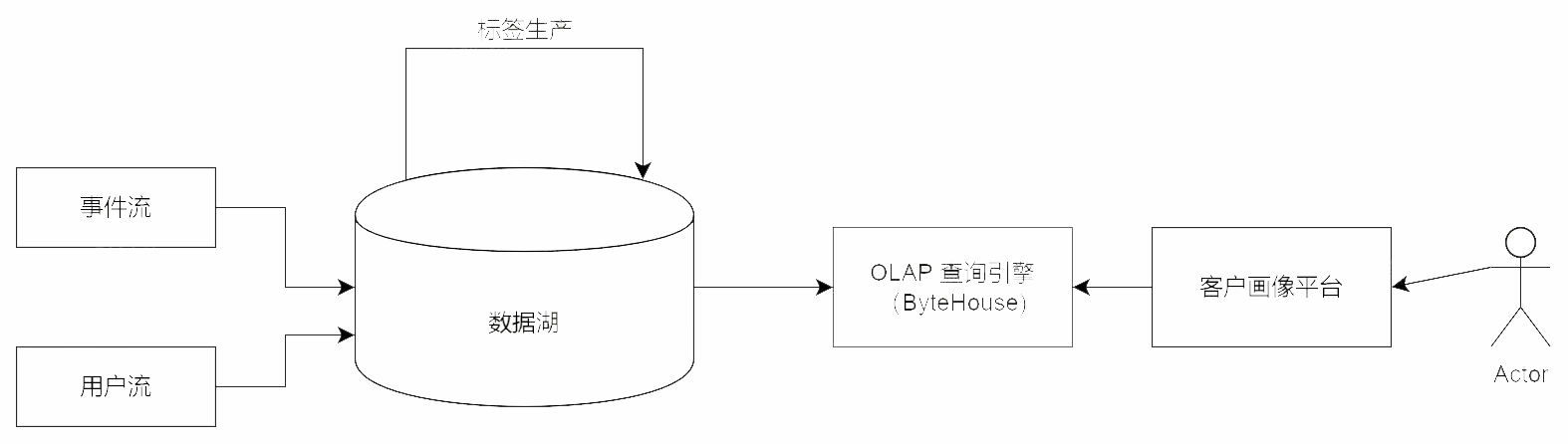
背景
- 第一,由于此类查询分析是临时性的,各种标签组合数巨大,离线预计算无法满足此类灵活性。
- 第二,由于此类查询是实时场景,查询性能变得非常关键, 通常一次查询在分钟级,耗时较长,无法满足分析师需求。
场景模型
|
user_id
|
sex
|
age
|
tags
|
|
10001
|
F
|
20
|
[]
|
|
10002
|
M
|
22
|
[tag_1,tag_2]
|
|
10003
|
F
|
23
|
[tag_1]
|
|
10004
|
M
|
24
|
[tag_2]
|
|
10005
|
F
|
25
|
[tag_1,tag_2]
|
|
tags
|
active_users
|
|
tag_1
|
[10002,10003,10005]
|
|
tag_2
|
[10002,10005]
|
- 其一,只有跟人群相关的维度会被保留,其他信息例如sex,age等会被移除。
- 其二,active_users以数组(array)的形式存放所有的用户id, 这种操作带来的一个重要的收益是减少了行数,同时减少了数据大小。
ByteHouse Bitmap类型
CREATE TABLE id_tags (
tags String,
active_users Array<UInt64>
) Engine = CnchMergeTree() order by tags
WITH (SELECT active_users as tag_1
FROM id_tags
WHERE tags = 'tag_1') as tag_1_user,
WITH(SELECT active_users as tag_2
FROM id_tags
WHERE tags = 'tag_2') as tag_2_user,
SELECT length(arrayIntersect(tag_1_user, tag_2_user))
CREATE TABLE id_tags (
tags String,
active_users BitMap64
) Engine = CnchMergeTree() order by tags
SELECT bitmapCount('tag_1&tag_2')
FROM tag_uids_map数据导入
INSERT INTO TABLE id_tags values ('tag_1', [2,4,6]),('tag_2', [1,3,5])
相关函数
bitmapColumnAnd用来接收一个bitmap列,对该列所有bitmap做and运算; 以及bitmapColumnCardinality用来返回一个列中所有bitmap的元素个数。 详情可以参考官方文档。BitEngine原理介绍
BitMap结构解析
- Array container: 数据量较少的时候(一般少于8K容量),更省空间
- Bitmap container 适合存储稠密数据、占用空间小
字典优化
CREATE TABLE id_tags (
tags String,
active_users BitMap64 BitEngineEncode
) Engine = CnchMergeTree() order by tags
本质上字典服务是个onto映射, 可以通过key 查找value, 也可以通过value反查key, 其中key原始值,value时编码值。开启编码之后,ByteHouse会依赖一个字典文件。在默认情况下,ByteHouse会在内部维护一个字典文件。 当底表更新时,内部字典文件也会随之异步更新。ByteHouse同时也支持用户维护外部字典,这里不做展开。总结
人群分析是画像平台的基础功能,本文介绍了如何利用ByteHouse内置的BitMap类型来支持实时的画像查询分析。目前ByteHouse云数仓以及企业版均已登陆火山引擎。未来,火山引擎将通过 ByteHouse 来为客户持续提供字节跳动和外部最佳实践,构建交互式大数据分析平台,以应对复杂多变的业务需求和高速增长的数据场景。10亿数据、查询<10s,论基于OLAP搭建广告系统的正确姿势的更多相关文章
- 这么设计,Redis 10亿数据量只需要100MB内存
本文主要和大家分享一下redis的高级特性:bit位操作. 本文redis试验代码基于如下环境: 操作系统:Mac OS 64位 版本:Redis 5.0.7 64 bit 运行模式:standalo ...
- 怎么对10亿数据量级的mongoDB作高效的全表扫描
转自:http://quentinxxz.iteye.com/blog/2149440 一.正常情况下,不应该有这种需求 首先,大家应该有个概念,标题中的这个问题,在大多情况下是一个伪命题,不应该被提 ...
- CNN实战篇-手把手教你利用开源数据进行图像识别(基于keras搭建)
我一直强调做深度学习,最好是结合实际的数据上手,参照理论,对知识的掌握才会更加全面.先了解原理,然后找一匹数据来验证,这样会不断加深对理论的理解. 欢迎留言与交流! 数据来源: cifar10 (其 ...
- 【Linux】基于VMware搭建Linux系统
本篇文章侧重于操作,主要内容大致包括: 两大类操作系统简要介绍 VMware Workstation Pro 15简要介绍及安装 CentOS简要介绍及基于Wi'n'dows 操作系统的安装 一 关于 ...
- .NET基于Eleasticsearch搭建日志系统实战演练
一.需求背景介绍 1.1.需求描述 大家都知道C/S架构模式的客户端应用程序(比如:WinForm桌面应用.WPF.移动App应用程序.控制台应用程序.Windows服务等等)的日志记录都存储在本地客 ...
- 海量数据处理 - 10亿个数中找出最大的10000个数(top K问题)
前两天面试3面学长问我的这个问题(想说TEG的3个面试学长都是好和蔼,希望能完成最后一面,各方面原因造成我无比想去鹅场的心已经按捺不住了),这个问题还是建立最小堆比较好一些. 先拿10000个数建堆, ...
- 比hive快10倍的大数据查询利器presto部署
目前最流行的大数据查询引擎非hive莫属,它是基于MR的类SQL查询工具,会把输入的查询SQL解释为MapReduce,能极大的降低使用大数据查询的门槛, 让一般的业务人员也可以直接对大数据进行查询. ...
- ORM执行原生SQL语句、双下划线数据查询、ORM外键字段的创建、外键字段的相关操作、ORM跨表查询、基于对象的跨表查询、基于双下划线的跨表查询、进阶查询操作
今日内容 ORM执行SQL语句 有时候ROM的操作效率可能偏低 我们是可以自己编写sql的 方式1: models.User.objects.raw('select * from app01_user ...
- 基于SQL和PYTHON的数据库数据查询select语句
#xiaodeng#python3#基于SQL和PYTHON的数据库数据查询语句import pymysql #1.基本用法cur.execute("select * from biao&q ...
- 2016/05/10 thinkphp 3.2.2 ①系统常量信息 ②跨控制器调用 ③连接数据库配置及Model数据模型层 ④数据查询
[系统常量信息] 获取系统常量信息: 如果加参数true,会分组显示: 显示如下: [跨控制器调用] 一个控制器在执行的时候,可以实例化另外一个控制,并通过对象访问其指定方法. 跨控制器调用可以节省我 ...
随机推荐
- SNN_文献阅读_Recent Advances and New Frontiers in Spiking Neural Networks
Recent Advances and New Frontiers in Spiking Neural Networks 基本要素:包括神经元模型.神经元中脉冲序列的编码方法.神经网络中每个基本层的拓 ...
- 题解 CF1264D2
前言 建议大家看一下我对于 D1 的题解(传送门)后再看本题解,本题解是基于那篇题解的基础上书写的. 数学符号约定 \(\dbinom{n}{m}\):表示 \(n\) 选 \(m\) . 如非特殊说 ...
- UNI-APP之微信小程序转H5
开始 最近有个需求,需要将微信小程序中一些页面和功能改成h5,这次功能开发的时间有点紧,而且重新写一套有点来不及.考虑到微信小程序与uni-app有着一些共通之处,所以打算直接转成uni-app.un ...
- 【Javaweb】servlet一
什么是servlet 1.servlet是JavaEE规范之一,规范就是接口. 2.servlet是Javaweb三大组件之一.三大组件分别是:servlet程序.filter过滤器.listener ...
- 【总结】IntelliJ IDEA 插件
1..iBATIS/MyBatis plugin轻松通过快捷键找到MyBatis中对应的Mapper和XML,CTRL+ALT+B 2.iBATIS/MyBatis plugin轻松通过快捷键找到My ...
- vertx的学习总结1
一. vertx是什么? 答:lib工具包 二. 为什么要使用vertx 答: 异步和非阻塞:Vert.x 采用了事件驱动和非阻塞的编程模型,可以处理大量并发请求而不会阻塞线程,提供更好的响应 ...
- LLM面面观之LLM复读机问题及解决方案
1. 背景 关于LLM复读机问题,本qiang~在网上搜刮了好几天,结果是大多数客观整理的都有些支离破碎,不够系统. 因此,本qiang~打算做一个相对系统的整理,包括LLM复读机产生的原因以及对应的 ...
- 使用jvm工具排查系统问题
java-jvm-tool Jstatd 远程连接(推荐) 不用重启项目 远程机配置 [demo@localhost jvmtest]$ vi jstatd.all.policy# 内容grant c ...
- ElasticSearch给索引起"别名"和其重要性
创建别名: https://www.elastic.co/guide/en/elasticsearch/reference/6.8/indices-aliases.html 我们有时候并不能确保索引库 ...
- 前端异步编程 —— Promise对象
在前端编程中,处理一些简短.快速的操作,在主线程中就可以完成. 但是,在处理一些耗时比较长以至于比较明显的事情,比如读取一个大文件或者发出一个网络请求,就需要异步编程来实现,以避免只用主线程时造成页面 ...