知识蒸馏相关技术【模型蒸馏、数据蒸馏】以ERNIE-Tiny为例
1.任务简介
基于ERNIE预训练模型效果上达到业界领先,但是由于模型比较大,预测性能可能无法满足上线需求。
直接使用ERNIE-Tiny系列轻量模型fine-tune,效果可能不够理想。如果采用数据蒸馏策略,又需要提供海量未标注数据,可能并不具备客观条件。
因此,本专题采用主流的知识蒸馏的方案来压缩模型,在满足用户预测性能、预测效果的需求同时,不依赖海量未标注数据,提升开发效率。
文心提供多种不同大小的基于字粒度的ERNIE-Tiny学生模型,满足不同用户的需求。
注:知识蒸馏(KD)是将复杂模型(teacher)中的dark
knowledge迁移到简单模型(student)中去,teacher具有强大的能力和表现,而student则更为紧凑。通过知识蒸馏,希望student能尽可能逼近亦或是超过teacher,从而用更少的复杂度来获得类似的预测效果。
1.1 模型蒸馏原理
知识蒸馏是一种模型压缩常见方法,指的是在teacher-student框架中,将复杂、学习能力强的网络(teacher)学到的特征表示"知识"蒸馏出来,传递给参数量小、学习能力弱的网络(student)。
在训练过程中,往往以最优化训练集的准确率作为训练目标,但真实目标其实应该是最优化模型的泛化能力。显然如果能直接以提升模型的泛化能力为目标进行训练是最好的,但这需要正确的关于泛化能力的信息,而这些信息通常不可用。如果我们使用由大型模型产生的所有类概率作为训练小模型的目标,就可以让小模型得到不输大模型的性能。这种把大模型的知识迁移到小模型的方式就是蒸馏。
基本原理可参考Hinton经典论文:https://arxiv.org/abs/1503.02531
1.2 ERNIE-Tiny 模型蒸馏
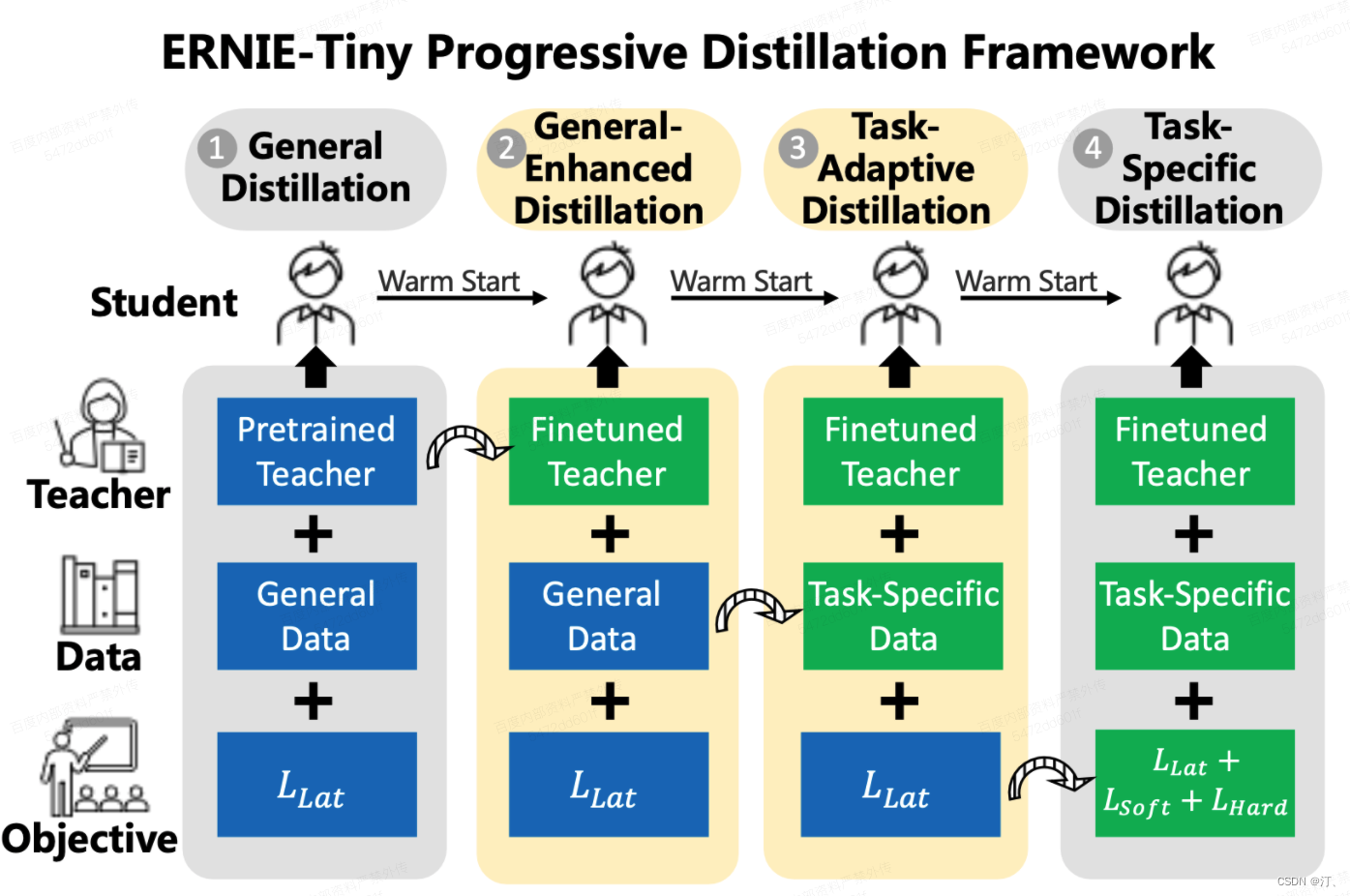
- 模型蒸馏原理可参考论文 ERNIE-Tiny : A Progressive Distillation Framework for Pretrained Transformer Compression 2021。不同于原论文的实现,为了和开发套件中的通用蒸馏学生模型保持一致,我们将蒸馏loss替换为Attention矩阵的KQ loss和 VV loss,原理可参考论文 MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers 2020 和 MiniLMv2: Multi-Head Self-Attention Relation Distillation for Compressing Pretrained Transformers 2021。实验表明通用蒸馏阶段和任务蒸馏阶段的蒸馏loss不匹配时,学生模型的效果会受到影响。
BERT 等预训练语言模型 (PLM) 采用了一种训练范式,首先在一般数据中预训练模型,然后在特定任务数据上微调模型,最近取得了巨大成功。然而,PLM 因其庞大的参数而臭名昭著,并且难以部署在现实生活中的应用程序中。知识蒸馏通过在一组数据上将知识从大老师转移到小得多的学生来解决这个问题。我们认为选择三个关键组成部分,即教师、训练数据和学习目标,对于蒸馏的有效性至关重要。因此,我们提出了一个四阶段渐进式蒸馏框架 ERNIE-Tiny 来压缩 PLM,它将三个组件从一般级别逐渐变化到特定任务级别。具体来说,第一阶段,General Distillation,在预训练的老师、一般数据和潜在蒸馏损失的指导下进行蒸馏。然后,General-Enhanced Distillation 将教师模型从预训练教师转变为微调教师。之后,Task-Adaptive Distillation 将训练数据从一般数据转移到特定于任务的数据。最后,Task-Specific Distillation 在最后阶段增加了两个额外的损失,即 Soft-Label 和 Hard-Label 损失。实证结果证明了我们的框架的有效性和所带来的泛化增益 。实验表明 4 层 ERNIE-Tiny 在 GLUE 基准测试的基础上保持其 12 层教师 BERT 的 98.0% 以上的性能,超过最先进的 (SOTA) 1.0% 的 GLUE 分数相同数量的参数。此外,ERNIE-Tiny 在五个中文 NLP 任务上实现了新的压缩 SOTA,比 BERT 基础的精度高 0.4%,参数减少 7.5 倍,推理速度加快 9.4 倍。
预训练的语言模型(例如,BERT (Devlin et al., 2018) 及其变体)在各种 NLP 任务中取得了显着的成功。然而,这些模型通常包含数亿个参数,由于延迟和容量限制,这给现实应用中的微调和在线服务带来了挑战。在这项工作中,我们提出了一种简单有效的方法来压缩基于大型 Transformer (Vaswani et al., 2017) 的预训练模型,称为深度自注意力蒸馏。小模型(学生)通过深度模仿大模型(老师)的自注意力模块进行训练,该模块在 Transformer 网络中起着至关重要的作用。具体来说,我们建议提炼出教师最后一个 Transformer 层的自注意力模块,这对学生来说既有效又灵活。此外,除了现有作品中使用的注意力分布(即查询和键的缩放点积)之外,我们还引入了自我注意模块中值之间的缩放点积作为新的深度自我注意知识. 此外,我们表明,引入教师助理(Mirzadeh 等人,2019 年)也有助于提炼大型预训练 Transformer 模型。实验结果表明,我们的单语模型在不同参数大小的学生模型中优于最先进的基线。特别是,它使用 50% 的 Transformer 参数和教师模型的计算在 SQuAD 2.0 和几个 GLUE 基准测试任务上保持了 99% 以上的准确率。我们还在将深度自注意力蒸馏应用于多语言预训练模型方面获得了竞争性结果。
我们仅使用自注意力关系蒸馏来对预训练的 Transformer 进行任务不可知的压缩,从而在 MiniLM (Wang et al., 2020) 中推广深度自注意力蒸馏。特别是,我们将多头自注意力关系定义为每个自注意力模块内的查询、键和值向量对之间的缩放点积。然后我们利用上述关系知识来训练学生模型。除了简单统一的原则外,更有利的是,学生的注意力头数没有限制,而之前的大多数工作都必须保证教师和学生之间的头数相同。此外,细粒度的自注意力关系倾向于充分利用 Transformer 学习到的交互知识。此外,我们彻底检查了教师模型的层选择策略,而不是像 MiniLM 中那样仅仅依赖最后一层。我们对压缩单语和多语预训练模型进行了广泛的实验。实验结果表明,我们从基础规模和大型教师(BERT、RoBERTa 和 XLM-R)中提取的模型优于最先进的模型。
二阶段蒸馏:
- 通用蒸馏(General Distillation,GD):在预训练阶段训练,使用大规模无监督的数据, 帮助学生网络学习到尚未微调的教师网络中的知识,有利于提高泛化能力。为方便用户使用,我们提供了多种尺寸的通用蒸馏学生模型,可用的通用蒸馏学生模型可参考文档:通用模型 - ERNIE3.0 Tiny。
- 任务蒸馏(Task-specific Distillation,TD):使用具体任务的数据,学习到更多任务相关的具体知识。
如果已提供的通用蒸馏学生模型尺寸符合需求,用户可以主要关注接下来的任务蒸馏过程。
1.3任务蒸馏步骤
- FT阶段:基于ERNIE 3.0 Large蒸馏模型fine-tune得到教师模型,注意这里用到的教师模型和ERNIE 3.0 Large是两个不同的模型;
- GED阶段(可选):使用fine-tuned教师模型和通用数据继续用通用蒸馏的方式蒸馏学生模型,进一步提升学生模型的效果;
a. 热启动fine-tuned的教师模型和通用学生模型。其中,通用的学生模型由文心平台提供,从bos上下载。
- TD1阶段:蒸馏中间层
a.只对学生模型的最后一层进行蒸馏,将学生模型transformer的attention层的k-q矩阵和v-v矩阵与教师模型的对应矩阵做KLloss,可参考 :MiniLMV2。
b.热启动fine-tuned的教师模型和GED阶段得到的学生模型。其中,通用的学生模型由文心平台提供,从bos上下载,下载链接所在文档:通用模型ERNIE3.0 Tiny,或参考预置的下载脚本:
c. 反向传播阶段只更新学生模型参数,教师模型参数不更新;
- TD2阶段:蒸馏预测层,产出最终的学生模型。
a. 热启动fine-tuned的教师模型和TD1阶段训练的学生模型;
b. loss包括两部分: 1) pred_loss:软标签,学生模型的预测层输出与教师模型的预测层输出的交叉熵; 2)
student_ce_loss:硬标签,学生模型的预测层输出与真实label的交叉熵;c. pred_loss与student_ce_loss之和作为最终loss,进行反向传播;
d. 反向传播阶段只更新学生模型参数,教师模型参数不更新;
注:关于GED阶段使用的通用数据:开发套件中的通用数据是由开源项目 https://github.com/brightmart/nlp_chinese_corpus 中的中文维基百科语料(wiki2019zh)经过预处理得到。该数据只用于demo展示,实际使用时替换为业务无标注数据效果提升更明显。
2. 常见问题
问题1:怎么修改学生模型的层数?上面提供了多种不同的学生模型,但每个学生模型的层数、hidden size等都是固定的,如果想更改,需要在哪些地方更改?
文心提供了三种不同结构的预训练学生模型,如果修改层数、hidden size等,会导致预训练学生模型参数无法加载,在此情况下,蒸馏出来的学生模型效果无法保证,建议用户还是使用文心提供的预训练模型,不更改模型结构;如果用户认为更改学生模型的结构非常有必要,需要对文心做以下改动:
- 修改TD1阶段json配置文件的pre_train_model配置项,删除预训练学生模型的加载,只保留微调后的教师模型
"pre_train_model": [
# 热启动fine-tune的teacher模型
{
"name": "finetuned_teacher_model",
"params_path": "./output/cls_ernie_3.0_large_ft/save_checkpoints/checkpoints_step_6000"
}
]
- 将json文件中的"student_embedding"替换为自定义的学生模型
"student_embedding": {
"config_path": "../../models_hub/ernie_3.0_tiny_ch_dir/ernie_config.json"
},
- 再次强调,上述修改后,由于无法加载预训练学生模型,蒸馏出来的学生模型效果无法保证。(用户训练数据量到百万样本以上可以考虑尝试一下)
3.数据蒸馏任务
3.1 简介
在ERNIE强大的语义理解能力背后,是需要同样强大的算力才能支撑起如此大规模模型的训练和预测。很多工业应用场景对性能要求较高,若不能有效压缩则无法实际应用。
因此,我们基于数据蒸馏技术构建了数据蒸馏系统。其原理是通过数据作为桥梁,将ERNIE模型的知识迁移至小模型,以达到损失很小的效果却能达到上千倍的预测速度提升的效果。
目录结构
数据蒸馏任务位于 wenxin_appzoo/tasks/data_distillation
├── data
│ ├── dev_data
│ ├── dict
│ ├── download_data.sh
│ ├── predict_data
│ ├── test_data
│ └── train_data
├── distill
│ └── chnsenticorp
│ ├── student
│ └── teacher
├── examples
│ ├── cls_bow_ch.json
│ ├── cls_cnn_ch.json
│ ├── cls_ernie_fc_ch_infer.json
│ └── cls_ernie_fc_ch.json
├── inference
│ ├── custom_inference.py
│ ├── __init__.py
├── model
│ ├── base_cls.py
│ ├── bow_classification.py
│ ├── cnn_classification.py
│ ├── ernie_classification.py
│ ├── __init__.py
├── run_distill.sh
├── run_infer.py
├── run_trainer.py
└── trainer
├── custom_dynamic_trainer.py
├── __init__.py
3.2 数据准备
目前采用三种数据增强策略策略,对于不用的任务可以特定的比例混合。三种数据增强策略包括:
(1)添加噪声:对原始样本中的词,以一定的概率(如0.1)替换为”UNK”标签
(2)同词性词替换:对原始样本中的所有词,以一定的概率(如0.1)替换为本数据集中随机一个同词性的词
(3)N-sampling:从原始样本中,随机选取位置截取长度为m的片段作为新的样本,其中片段的长度m为0到原始样本长度之间的随机值
数据增强策略可参考数据增强,我们已准备好了采用上述3种增强策略制作的chnsenticorp的增强数据。
3.3 离线蒸馏
- 使用预置的ERNIE 2.0 base模型
cd wenxin_appzoo/models_hub
bash download_ernie_2.0_base_ch.sh
- 下载预置的原始数据以及增强数据。
cd wenxin_appzoo/tasks/data_distillation/distill
bash download_data.sh
- 运行以下命令,开始数据蒸馏
cd wenxin_appzoo/tasks/data_distillation
bash run_distill.sh
3.3.1蒸馏过程说明
- run_distill.sh脚本会进行前述的三步:
在任务数据上Fine-tune;
加载Fine-tune好的模型对增强数据进行打分;
使用Student模型进行训练。脚本采用hard-label蒸馏,在第二步中将会直接预测出ERNIE标注的label。
- run_distill.sh脚本涉及教师和学生模型的json文件,其中:
./examples/cls_ernie_fc_ch.json负责教师模型的finetune,
./examples/cls_ernie_fc_ch_infer.json 负责教师模型的预测。 ./examples/cls_cnn_ch.json,负责学生模型的训练。
- 事先构造好的增强数据放在./distill/chnsenticorp/student/unsup_train_aug
- 在脚本的第二步中,使用 ./examples/cls_ernie_fc_ch_infer.json 进行预测:脚本从标准输入获取明文输入,并将打分输出到标准输出。用这种方式对数据增强后的无监督训练预料进行标注。最终的标注结果放在 ./distill/chnsenticorp/student/train/part.1文件中。标注结果包含两列, 第一列为明文,第二列为标注label。
- 在第三步开始student模型的训练,其训练数据放在 distill/chnsenticorp/student/train/ 中,part.0 为原监督数据 part.1 为 ERNIE 标注数据。
- 注:如果用户已经拥有了无监督数据,则可以将无监督数据放入distill/chnsenticorp/student/unsup_train_aug 即可。
知识蒸馏相关技术【模型蒸馏、数据蒸馏】以ERNIE-Tiny为例的更多相关文章
- 关于Web开发里并发、同步、异步以及事件驱动编程的相关技术
一.开篇语 我的上篇文章<关于如何提供Web服务端并发效率的异步编程技术>又成为了博客园里“编辑推荐”的文章,这是对我写博客很大的鼓励,也许是被推荐的原因很多童鞋在这篇文章里发表了评论,有 ...
- SAAS相关技术要点
这篇文章本来是我们开发组内部用的一个小文档.因为我们公司以前没有做SAAS的经验,就成立了一个小组做一做这方面的技术前探,我是成员之一.这篇文档想从宏观的层面把开发一个SAAS应用所要用到的技术点稍微 ...
- ACL2016信息抽取与知识图谱相关论文掠影
实体关系推理与知识图谱补全 Unsupervised Person Slot Filling based on Graph Mining 作者:Dian Yu, Heng Ji 机构:Computer ...
- SLAM+语音机器人DIY系列:(七)语音交互与自然语言处理——1.语音交互相关技术
摘要 这一章将进入机器人语音交互的学习,让机器人能跟人进行语音对话交流.这是一件很酷的事情,本章将涉及到语音识别.语音合成.自然语言处理方面的知识.本章内容: 1.语音交互相关技术 2.机器人语音交互 ...
- [转帖]我最近研究了hive的相关技术,有点心得,这里和大家分享下。
我最近研究了hive的相关技术,有点心得,这里和大家分享下. https://www.cnblogs.com/sharpxiajun/archive/2013/06/02/3114180.html 首 ...
- SDN与NFV技术在云数据中心的规模应用探讨
Neo 2016-1-29 | 发表评论 编者按:以云数据中心为切入点,首先对SDN领域中的叠加网络.SDN控制器.VxLAN 3种重要技术特点进行了研究,接下来对NFV领域中的通用服务器性能.服务链 ...
- 【原】http缓存与cdn相关技术
摘要:最近要做这个主题的组内分享,所以准备了一个星期,查了比较多的资料.准备的过程虽然很烦很耗时间,不过因为需要查很多的资料,因此整个过程下来,对这方面的知识影响更加深刻.来来来,接下来总结总结 一 ...
- JavaScript对SVG进行操作的相关技术
原文地址:http://www.ibm.com/developerworks/cn/xml/x-svgscript/ 本文主要介绍在 SVG 中通过编程实现动态操作 SVG 图像的知识. SVG ...
- http缓存与cdn相关技术
阅读目录 一 http缓存 二.Http缓存概念解析 三.cdn相关技术 摘要:最近要做这个主题的组内分享,所以准备了一个星期,查了比较多的资料.准备的过程虽然很烦很耗时间,不过因为需要查很多的资料, ...
- MVC中Controller控制器相关技术
第6章Controller相关技术 Controller(控制器)在ASP.NET MVC中负责控制所有客户端与服务器端的交互,并 且负责协调Model与View之间的数椐传递,是ASP.NET MV ...
随机推荐
- 如何安装和使用 Hugging Face Unity API
Hugging Face Unity API 提供了一个简单易用的接口,允许开发者在自己的 Unity 项目中方便地访问和使用 Hugging Face AI 模型,已集成到 Hugging Face ...
- 协同导航定位技术:为GPS定位盲区而生
导航技术和我们的生活息息相关.行人导航系统是一种为行人提供导航服务的便携式设备,可以适应地下.矿洞等卫星信号拒止的地区,以及大商场等拓扑结构复杂的地区,通常基于MIMU实现,本质上是惯性导航系统的一种 ...
- 叫板GPT-4的Gemini,我做了一个聊天网页,可图片输入,附教程
先看效果: 简介 Gemini 是谷歌研发的最新一代大语言模型,目前有三个版本,被称为中杯.大杯.超大杯,Gemini Ultra 号称可与GPT-4一较高低: Gemini Nano(预览访问) 为 ...
- 神经网络优化篇:详解动量梯度下降法(Gradient descent with Momentum)
动量梯度下降法 还有一种算法叫做Momentum,或者叫做动量梯度下降法,运行速度几乎总是快于标准的梯度下降算法,简而言之,基本的想法就是计算梯度的指数加权平均数,并利用该梯度更新的权重. 例如,如果 ...
- 可用性库存(CO09)排除库存地点增强
1.业务需求 1.1.业务背景 1.2.对应方案: 2.测试BAPI 首先运行事务代码CO09,查看结果 运行BAPI_MATERIAL_AVAILABILITY 3.增强实现 3.1.增强思路 3. ...
- 一篇文章教你从入门到精通 Google 指纹验证功能
本文首发于 vivo互联网技术 微信公众号 链接:https://mp.weixin.qq.com/s/EHomjBy4Tvm8u962J6ZgsA作者:Sun Daxiang Google 从 An ...
- STM32CubeMX教程18 DAC - DMA输出自定义波形
1.准备材料 开发板(正点原子stm32f407探索者开发板V2.4) STM32CubeMX软件(Version 6.10.0) 野火DAP仿真器 keil µVision5 IDE(MDK-Arm ...
- 响应式开发bootstrap
响应式开发原理 就是使用媒体查询针对不同宽度的设备进行布局和样式的设置,从而适配不同设备的目的. 平时我们响应式尺寸划分 超小屏幕(手机,小于768px):设置宽度为100% 小屏幕(平板,大于等于7 ...
- Liunx运维(一)-命令行
一.命令行的开启与推出 1.exit 2.logout 3.ctrl+d 二.命令行提示符 1.#root用户 2.$普通用户 3.~当前用户所在的路径 4.全局配置文件: /etc/profil ...
- java - 对象装载数据返回
1. 创建 Phone 类 package class_object; public class Phone { String brand; String color; double price; v ...