算法金 | 一文彻底理解机器学习 ROC-AUC 指标

大侠幸会,在下全网同名「算法金」 0 基础转 AI 上岸,多个算法赛 Top 「日更万日,让更多人享受智能乐趣」
在机器学习和数据科学的江湖中,评估模型的好坏是非常关键的一环。而 ROC(Receiver Operating Characteristic)曲线和 AUC(Area Under Curve)正是评估分类模型性能的重要工具。
这个知识点在面试中也很频繁的出现。尽管理解这些概念本身不难,但许多人在复习时容易混淆,或在面试紧张时忘记,影响回答效果。
本篇文章将会从基础概念入手,逐步深入到实际操作。我们会详细解释 ROC 曲线和 AUC 的定义和意义,通过实例和代码示范帮助大侠掌握这些工具的使用方法,最后通过一些实际应用案例和相关概念的对比,力求全面理解并灵活运用 ROC 和 AUC。

1. 基础概念介绍
1.1 什么是 ROC 曲线
ROC 曲线,即接收者操作特征曲线,ROC曲线产生于第二次世界大战期间,最早用在信号检测领域,侦测战场上的敌军载具(飞机、船舰)。现在是是用来评价二分类模型性能的常用图形工具。它通过显示真阳性率(True Positive Rate,简称 TPR)与假阳性率(False Positive Rate,简称 FPR)之间的权衡来帮助我们理解模型的分类能力。
1.2 什么是 AUC
AUC,即曲线下面积(Area Under Curve),是 ROC 曲线下面积的一个数值表示。它提供了一个定量的指标,用来衡量分类模型的整体表现。AUC 值范围从 0 到 1,值越大表示模型性能越好。
1.3 为何需要 ROC/AUC
在分类任务中,特别是当数据集类别不平衡时,单纯依赖准确率(Accuracy)可能会造成误导。为了更好地理解这一点,让我们通过一个例子来说明。
例子说明
假设我们有一个武侠元素的数据集,其中 95% 的样本是普通弟子,5% 的样本是高手。
让我们通过代码示例来演示这一点(代码供复现使用,可直接跳过下滑到解释部分):
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_curve, roc_auc_score, accuracy_score, confusion_matrix
# 生成一个极度不平衡的武侠数据集
# 假设特征表示武功修炼时间、战斗胜率等,标签表示是否为高手
X, y = make_classification(n_samples=1000, n_features=20, n_classes=2, weights=[0.95, 0.05], random_state=42)
# 将数据集分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建一个总是预测普通弟子的模型
class AlwaysNegativeModel:
def predict(self, X):
return np.zeros(X.shape[0])
# 训练和预测
model = AlwaysNegativeModel()
y_pred = model.predict(X_test)
# 计算混淆矩阵和准确率
cm = confusion_matrix(y_test, y_pred)
accuracy = accuracy_score(y_test, y_pred)
# 计算 ROC 曲线和 AUC
# 在这里我们需要一个概率预测来计算 ROC 曲线和 AUC,为了演示,我们假设模型输出的是一个常量概率
y_pred_prob = np.zeros(X_test.shape[0])
fpr, tpr, thresholds = roc_curve(y_test, y_pred_prob)
auc = roc_auc_score(y_test, y_pred_prob)
# 可视化结果
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.title("混淆矩阵")
plt.imshow(cm, interpolation='nearest', cmap=plt.cm.Blues)
plt.colorbar()
plt.xlabel("预测标签")
plt.ylabel("真实标签")
plt.xticks([0, 1], ["普通弟子", "高手"])
plt.yticks([0, 1], ["普通弟子", "高手"])
for i in range(2):
for j in range(2):
plt.text(j, i, cm[i, j], ha="center", va="center", color="red")
print(f"准确率: {accuracy:.2f}")
print(f"AUC: {auc:.2f}")
结果分析
如果我们使用一个简单的分类器,它总是预测所有样本为普通弟子。
这个模型的准确率为 95%,看起来表现很好,但实际上它根本无法识别高手,是一个毫无用处的分类器。
这个分类器没有任何实际的分类能力,因为它无法识别出真正的高手。
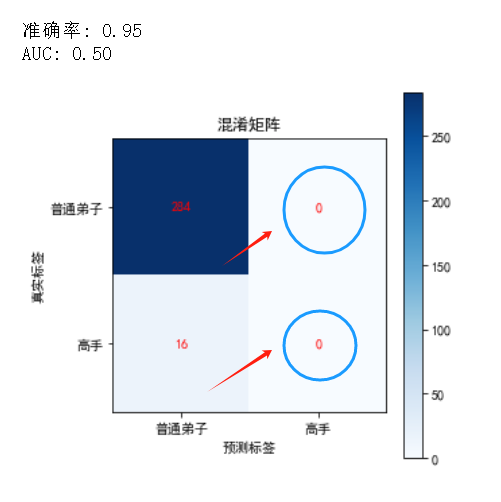
- ROC 曲线和 AUC:通过绘制 ROC 曲线并计算 AUC,我们可以看到 AUC 为 0.50,这表明模型没有任何区分能力。ROC 曲线是一条对角线,显示模型在随机猜测。
准确率只告诉我们模型整体预测正确的比例,但在类别不平衡的情况下,这个指标可能会误导我们。ROC 曲线和 AUC 提供了更全面的视角,展示了模型在不同阈值下的性能,帮助我们更准确地评估模型的分类能力。
更多内容,见免费知识星球
2. 详细解释
2.1 TPR(True Positive Rate)和 FPR(False Positive Rate)的定义
要理解 ROC 曲线,首先需要明白 TPR 和 FPR 的概念:
- TPR(True Positive Rate):也称为灵敏度(Sensitivity)或召回率(Recall),表示的是在所有真实为正的样本中,被正确预测为正的比例。其计算公式为:
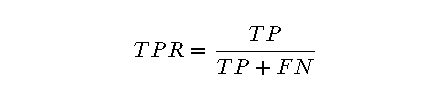
其中,TP(True Positives)是将正类正确分类为正类的样本数,FN(False Negatives)是将正类错误分类为负类的样本数。
- FPR(False Positive Rate):表示的是在所有真实为负的样本中,被错误预测为正的比例。其计算公式为:
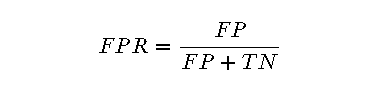
其中,FP(False Positives)是将负类错误分类为正类的样本数,TN(True Negatives)是将负类正确分类为负类的样本数。
2.2 AUC 的数学定义
AUC(Area Under Curve)是 ROC 曲线下的面积,用于评估分类模型的性能。AUC 值的范围从 0 到 1,值越大表示模型的性能越好。
数学上,AUC 可以通过积分计算:
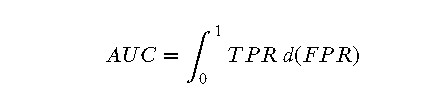
在离散情况下,AUC 可以通过梯形法则近似计算:
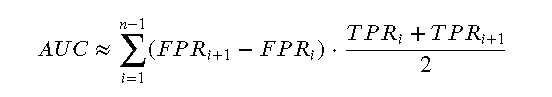
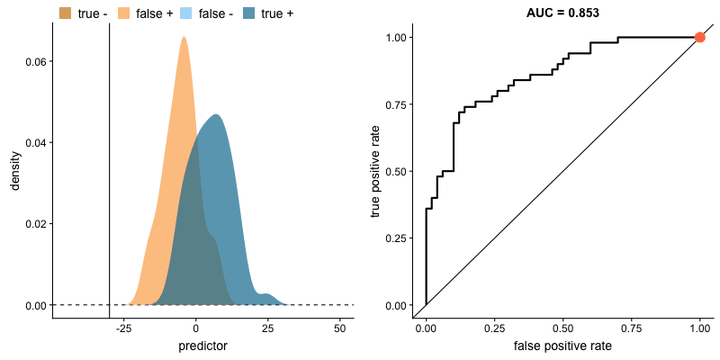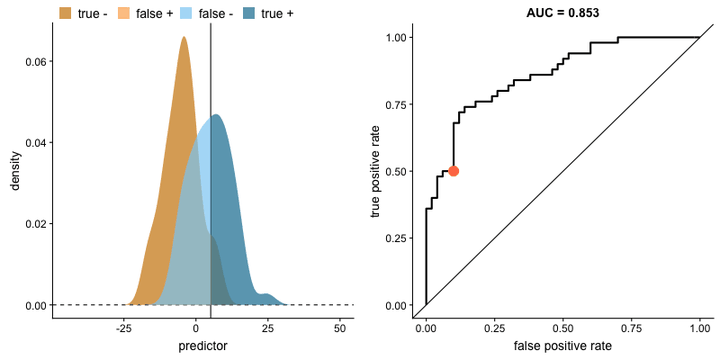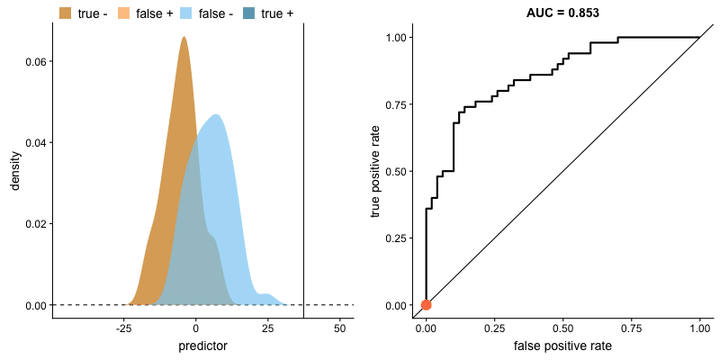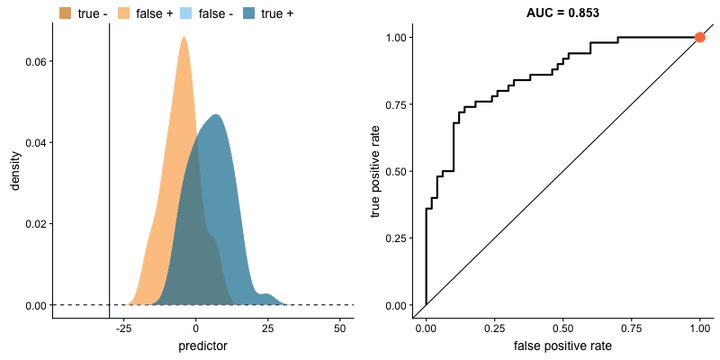

3 绘制 ROC 曲线的步骤
绘制 ROC 曲线的步骤如下:
- 选择阈值:从 0 到 1 的不同阈值。
- 计算 TPR 和 FPR:对于每个阈值,计算相应的 TPR 和 FPR。
- 绘制曲线:以 FPR 为横轴,TPR 为纵轴,绘制 ROC 曲线。
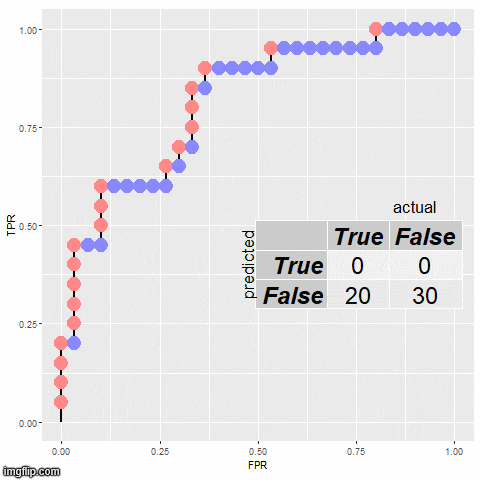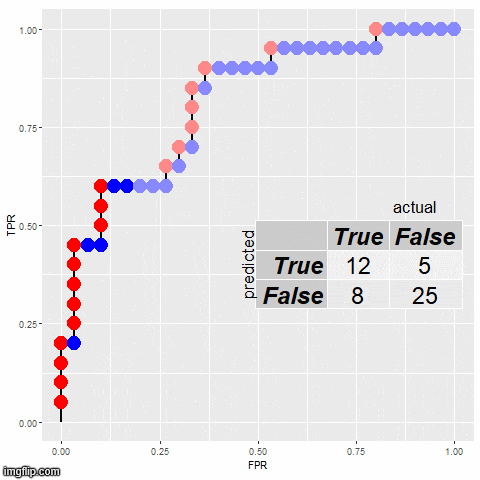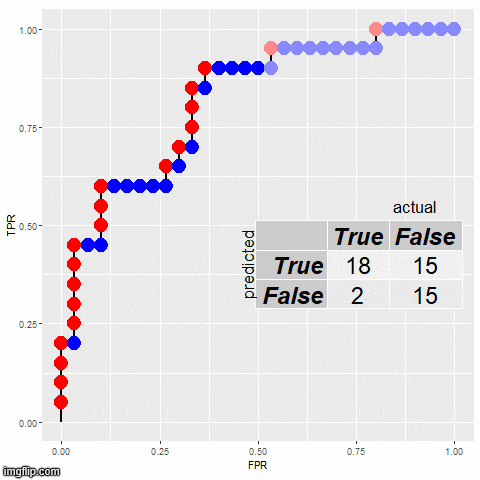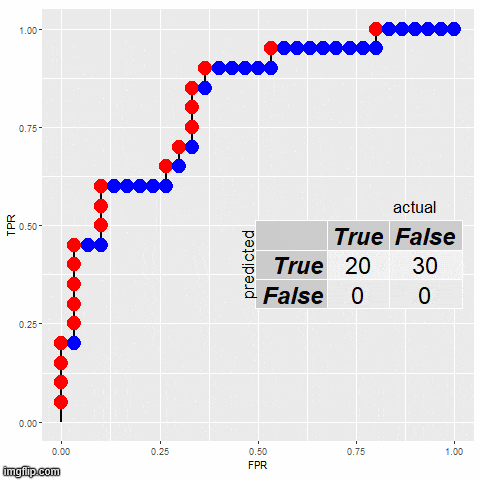
选择阈值:从 0 到 1 的不同阈值
from sklearn.metrics import roc_curve
# 预测测试集概率
y_pred_prob = model.predict_proba(X_test)[:, 1]
# 计算 ROC 曲线
fpr, tpr, thresholds = roc_curve(y_test, y_pred_prob)
# 输出部分阈值
print("阈值: ", thresholds[:10]) # 仅展示前10个阈值
计算 TPR 和 FPR:对于每个阈值,计算相应的 TPR 和 FPR
# 输出部分阈值对应的 TPR 和 FPR
for i in range(10): # 仅展示前10个阈值的对应值
print(f"阈值: {thresholds[i]:.2f} -> 假阳性率 (FPR): {fpr[i]:.2f}, 真阳性率 (TPR): {tpr[i]:.2f}")
绘制曲线:以 FPR 为横轴,TPR 为纵轴,绘制 ROC 曲线
import matplotlib.pyplot as plt
# 可视化 ROC 曲线
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, color='blue', lw=2, label='ROC 曲线')
plt.plot([0, 1], [0, 1], color='gray', lw=1, linestyle='--', label='随机猜测')
plt.xlabel("假阳性率 (FPR)")
plt.ylabel("真阳性率 (TPR)")
plt.title("ROC 曲线")
plt.legend(loc="lower right")
# 在曲线上标出几个阈值点
threshold_points = [0.2, 0.5, 0.8]
for threshold in threshold_points:
idx = np.where(thresholds >= threshold)[0][0]
plt.scatter(fpr[idx], tpr[idx], marker='o', color='red')
plt.text(fpr[idx], tpr[idx], f"阈值={threshold:.2f}", fontsize=12)
plt.show()

4 AUC 的意义
AUC 值越大,模型的性能越好。具体来说:
- AUC = 0.5 表示模型没有分类能力,相当于随机猜测。
- 0.5 < AUC < 0.7 表示模型有一定的分类能力,但效果一般。
- 0.7 ≤ AUC < 0.9 表示模型有较好的分类能力。
- AUC ≥ 0.9 表示模型有非常好的分类能力。
AUC 的优缺点
优点:
- 阈值无关:AUC 衡量的是模型在所有可能的分类阈值下的表现,因此不受单一阈值的影响。
- 综合性能评估:AUC 综合了 TPR 和 FPR 的信息,能够全面评估模型的性能。
缺点:
- 可能不适用于极度不平衡的数据:在极度不平衡的数据集上,AUC 可能无法准确反映模型的性能,需要结合其他评估指标使用。
- 解释复杂:对于非专业人士来说,AUC 的解释和理解可能比较困难。
代码示例
下面我们通过代码示例来计算 AUC 并解释其意义:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_curve, roc_auc_score, accuracy_score, confusion_matrix
# 生成一个不平衡的武侠数据集
# 假设特征表示武功修炼时间、战斗胜率等,标签表示是否为高手
X, y = make_classification(n_samples=1000, n_features=20, n_classes=2, weights=[0.9, 0.1], random_state=42)
# 将数据集分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 训练一个逻辑回归模型
model = LogisticRegression()
model.fit(X_train, y_train)
# 预测测试集
y_pred_prob = model.predict_proba(X_test)[:, 1]
# 计算 ROC 曲线和 AUC
fpr, tpr, thresholds = roc_curve(y_test, y_pred_prob)
auc = roc_auc_score(y_test, y_pred_prob)
# 可视化结果
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.title("ROC 曲线")
plt.plot(fpr, tpr, color='blue', lw=2, label=f"AUC = {auc:.2f}")
plt.plot([0, 1], [0, 1], color='gray', lw=1, linestyle='--')
plt.xlabel("假阳性率")
plt.ylabel("真阳性率")
plt.legend(loc="lower right")
plt.subplot(1, 2, 2)
plt.title("AUC 值示意")
plt.fill_between(fpr, tpr, color='blue', alpha=0.3)
plt.plot(fpr, tpr, color='blue', lw=2, label=f"AUC = {auc:.2f}")
plt.xlabel("假阳性率")
plt.ylabel("真阳性率")
plt.legend(loc="lower right")
plt.tight_layout()
plt.show()
print(f"AUC: {auc:.2f}")
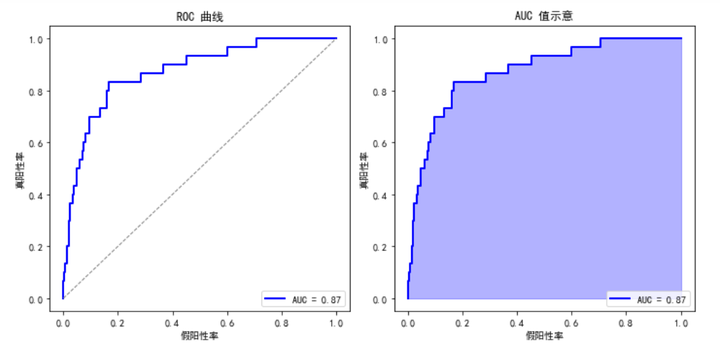
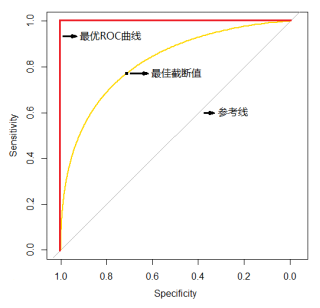
ROC 曲线图
- 横轴(假阳性率,FPR):表示负类样本中被错误分类为正类的比例。
- 纵轴(真阳性率,TPR):表示正类样本中被正确分类为正类的比例。
- 蓝色曲线:展示了模型在不同阈值下的 FPR 和 TPR 之间的关系。
- 灰色虚线:表示一个随机猜测模型的表现,其 AUC 值为 0.5。
- AUC 值:图中显示的 AUC 值(在图例中标注),越接近 1 说明模型的分类性能越好。
AUC 值示意图
- 蓝色区域:ROC 曲线下的面积,即 AUC 值。这个面积越大,说明模型的分类性能越好。
- AUC 值标注:同样在图例中标注了 AUC 值。
通过这两个图,可以直观地看到模型在不同阈值下的分类性能,以及通过 AUC 值来量化这种性能。
5. 实际应用案例
为了让大侠更好地理解 ROC 和 AUC 在实际中的应用,我们将展示它们在不同领域中的应用,如医学诊断和金融风险评估,并通过实际案例进行代码实现。
5.1 在不同领域中的应用
医学诊断
在医学诊断中,ROC 曲线和 AUC 被广泛用于评估诊断测试的性能。例如,在筛查癌症时,医生希望测试能够正确识别出患病和未患病的患者。ROC 曲线可以帮助医生选择最佳的阈值,从而最大化检测的准确性。
金融风险评估
在金融领域,ROC 和 AUC 被用于评估信用评分模型的性能。例如,银行希望识别高风险借款人,以降低贷款违约率。ROC 曲线可以帮助银行选择适当的阈值,以平衡风险和收益。
5.2 实际案例分析及代码实现
我们将使用一个模拟的医学诊断数据集来演示如何应用 ROC 和 AUC。假设我们有一个数据集,包含患者的各种特征以及他们是否患有某种疾病。
代码示例和结果分析
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_curve, roc_auc_score, accuracy_score, confusion_matrix
# 加载乳腺癌数据集
data = load_breast_cancer()
X = data.data
y = data.target
# 将数据集分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 训练一个逻辑回归模型
model = LogisticRegression(max_iter=10000)
model.fit(X_train, y_train)
# 预测测试集
y_pred = model.predict(X_test)
y_pred_prob = model.predict_proba(X_test)[:, 1]
# 计算混淆矩阵和准确率
cm = confusion_matrix(y_test, y_pred)
accuracy = accuracy_score(y_test, y_pred)
# 计算 ROC 曲线和 AUC
fpr, tpr, thresholds = roc_curve(y_test, y_pred_prob)
auc = roc_auc_score(y_test, y_pred_prob)
# 可视化结果
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.title("混淆矩阵")
plt.imshow(cm, interpolation='nearest', cmap=plt.cm.Blues)
plt.colorbar()
plt.xlabel("预测标签")
plt.ylabel("真实标签")
plt.xticks([0, 1], ["未患病", "患病"])
plt.yticks([0, 1], ["未患病", "患病"])
for i in range(2):
for j in range(2):
plt.text(j, i, cm[i, j], ha="center", va="center", color="red")
plt.subplot(1, 2, 2)
plt.title("ROC 曲线")
plt.plot(fpr, tpr, color='blue', lw=2, label=f"AUC = {auc:.2f}")
plt.plot([0, 1], [0, 1], color='gray', lw=1, linestyle='--', label='随机猜测')
plt.xlabel("假阳性率")
plt.ylabel("真阳性率")
plt.legend(loc="lower right")
plt.tight_layout()
plt.show()
print(f"准确率: {accuracy:.2f}")
print(f"AUC: {auc:.2f}")
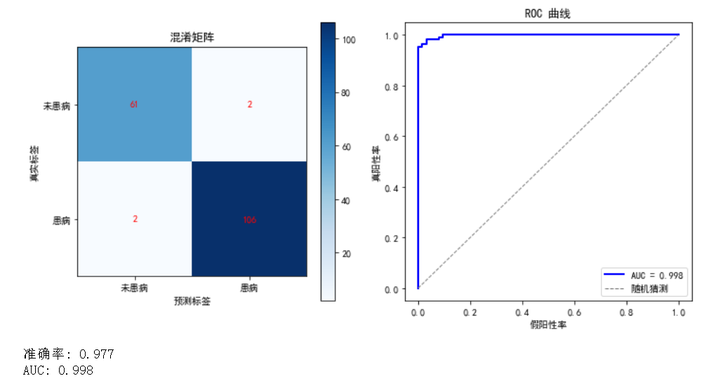
结果分析
- 准确率:模型的准确率(Accuracy)为 0.98,这意味着在所有测试样本中,有 98% 的样本被正确分类。
- AUC 值:AUC 值为 0.998,这意味着模型在区分未患病和患病患者方面表现非常完美。AUC = 0.998 表示模型在所有可能的阈值下都能完全区分正类和负类样本,这是一种理想状态。
解释
- 准确率为 0.98:在大多数情况下,这是一个很高的准确率,表明模型几乎所有的预测都是正确的。
- AUC = 0.998:表示模型在所有可能的阈值下都能完全区分未患病和患病患者,展示了模型极高的区分能力。

6. 相关概念的对照和对比
在这部分内容中,我们将对 ROC/AUC 与其他评估指标进行对照和对比,以便大侠更全面地理解这些指标在模型评估中的作用。
6.1 ROC/AUC 与混淆矩阵
混淆矩阵是一种用来评价分类模型性能的工具,它通过展示真阳性(TP)、假阳性(FP)、真阴性(TN)和假阴性(FN)的数量来评估模型。ROC 曲线和 AUC 则是从不同的阈值下综合评估模型的性能。
示例代码:
from sklearn.metrics import confusion_matrix, accuracy_score
# 预测测试集
y_pred = model.predict(X_test)
y_pred_prob = model.predict_proba(X_test)[:, 1]
# 计算混淆矩阵
cm = confusion_matrix(y_test, y_pred)
accuracy = accuracy_score(y_test, y_pred)
# 输出混淆矩阵和准确率
print("混淆矩阵:")
print(cm)
6.2 ROC/AUC 与 PR 曲线
PR 曲线(Precision-Recall Curve)是另一种评估二分类模型的方法,特别适用于不平衡数据集。它通过展示查准率(Precision)和召回率(Recall)之间的关系来评估模型性能。
- 查准率(Precision):表示在所有被预测为正类的样本中,实际为正类的比例。
- 召回率(Recall):表示在所有实际为正类的样本中,被正确预测为正类的比例。
示例代码:
from sklearn.metrics import precision_recall_curve
# 计算 PR 曲线
precision, recall, _ = precision_recall_curve(y_test, y_pred_prob)
# 可视化 PR 曲线
plt.figure()
plt.plot(recall, precision, color='blue', lw=2, label='PR 曲线')
plt.xlabel("召回率")
plt.ylabel("查准率")
plt.title("PR 曲线")
plt.legend(loc="lower left")
plt.show()
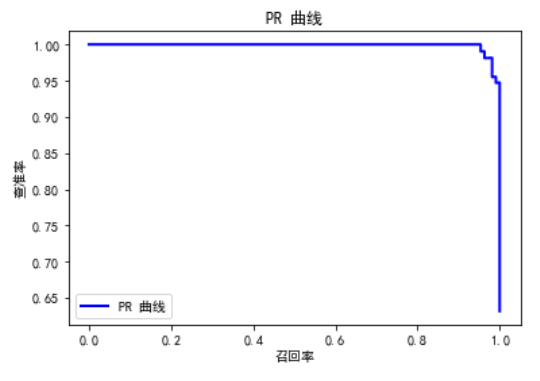
6.3 其他评估指标(如 Precision、Recall)与 ROC/AUC 的关系
除了 ROC/AUC 和 PR 曲线,其他常用的评估指标还有:
- 准确率(Accuracy):表示被正确分类的样本占总样本的比例。
- 查准率(Precision):表示在所有被预测为正类的样本中,实际为正类的比例。
- 召回率(Recall):表示在所有实际为正类的样本中,被正确预测为正类的比例。
- F1 分数(F1 Score):查准率和召回率的调和平均数,用于综合评价模型的精确性和召回率。
示例代码:
from sklearn.metrics import precision_score, recall_score, f1_score
# 计算查准率、召回率和 F1 分数
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
# 输出结果
print(f"查准率: {precision:.2f}")
print(f"召回率: {recall:.2f}")
print(f"F1 分数: {f1:.2f}")

7. 误区和注意事项
在使用 ROC 和 AUC 评估分类模型性能时,大侠需要注意一些常见的误区和使用注意事项,以便准确地理解和应用这些指标。
7.1 常见误区
误区一:高准确率等于高性能
高准确率并不一定意味着模型性能优秀,尤其是在类别不平衡的情况下。正如前文所示,即使一个模型总是预测为大多数类,其准确率也可能很高,但其实际分类能力可能非常差。
误区二:AUC 值越高越好
虽然 AUC 值高表示模型性能好,但在某些应用场景下,其他指标如查准率(Precision)和召回率(Recall)可能更加重要。例如,在医疗诊断中,召回率(即灵敏度)通常比 AUC 更加关键,因为漏诊的代价非常高。
误区三:单一指标评价模型
依赖单一指标评价模型性能是不全面的。最好结合多个指标(如 AUC、准确率、查准率、召回率和 F1 分数)来综合评估模型的性能。
7.2 使用 ROC/AUC 时的注意事项
注意事项一:数据不平衡问题
在处理类别不平衡的数据集时,AUC 和 ROC 曲线可以提供更全面的评估,但仍需要结合 PR 曲线等其他指标进行综合分析。
注意事项二:选择合适的阈值
ROC 曲线展示了模型在不同阈值下的性能表现,需要根据具体应用场景选择合适的阈值。例如,在金融风险评估中,选择较低的阈值可能会增加风险,但可以减少漏检。
注意事项三:模型的校准
确保模型的概率输出是校准的,即输出的概率与实际发生的概率一致。模型校准可以通过可靠性图(Calibration Curve)等方法进行评估和调整。
[ 抱个拳,总个结 ]
经过前面的详细讲解,我们已经全面了解了 ROC 曲线和 AUC 的概念、计算方法、代码实现以及在不同领域中的应用。下面对文章的核心内容进行简要回顾:
核心要点回顾
- 基础概念:ROC 曲线是用来评价二分类模型性能的工具,通过显示真阳性率(TPR)和假阳性率(FPR)之间的权衡来帮助我们理解模型的分类能力。AUC(曲线下面积)是 ROC 曲线下的面积,用于量化模型的整体表现。
- 详细解释:我们详细解释了 TPR 和 FPR 的定义,绘制 ROC 曲线的步骤,并通过实例代码演示了如何计算和绘制 ROC 曲线以及 AUC。还对 AUC 的数学定义、意义及其优缺点进行了分析。
- 代码示范:通过使用 Python 和 scikit-learn 库,我们实现了如何计算和绘制 ROC 曲线及 AUC,并通过实例展示了这些指标在实际应用中的效果。
- 实际应用案例:我们使用乳腺癌数据集进行模型训练和评估,展示了 ROC 和 AUC 在医学诊断中的实际应用,并通过代码详细演示了如何计算和解释这些指标。
- 相关概念对照和对比:我们对 ROC/AUC 与混淆矩阵、PR 曲线等其他评估指标进行了对照和对比,帮助全面理解这些指标的作用,并根据具体应用场景选择合适的评估方法。
- 误区和注意事项:我们讨论了在使用 ROC 和 AUC 时常见的误区和需要注意的事项,提醒大侠避免在模型评估中常见的错误,并提供了结合多种评估指标综合分析模型性能的方法。
关键概念回顾
- ROC 曲线:评估模型在不同阈值下的性能,通过展示 TPR 和 FPR 的关系来帮助理解模型的分类能力。
- AUC:量化 ROC 曲线下的面积,用于综合评价模型的整体表现,AUC 值越大表示模型性能越好。
- 混淆矩阵:展示模型的分类结果,通过四个基本要素(TP、FP、TN、FN)来评估模型性能。
- PR 曲线:展示查准率和召回率之间的关系,特别适用于类别不平衡的数据集。
- 校准曲线:评估模型的概率输出是否与实际概率一致,确保模型的概率预测是准确的。
通过这篇文章的讲解,希望大侠们能够更加全面地理解和应用 ROC 曲线和 AUC,在实际项目中灵活运用这些知识,提升模型评估的准确性和可靠性。
- 科研为国分忧,创新与民造福 -

日更时间紧任务急,难免有疏漏之处,还请大侠海涵 内容仅供学习交流之用,部分素材来自网络,侵联删
[ 算法金,碎碎念 ]
全网同名,日更万日,让更多人享受智能乐趣
如果觉得内容有价值,烦请大侠多多 分享、在看、点赞,助力算法金又猛又持久、很黄很 BL 的日更下去;
同时邀请大侠 关注、星标 算法金,围观日更万日,助你功力大增、笑傲江湖
算法金 | 一文彻底理解机器学习 ROC-AUC 指标的更多相关文章
- keras 上添加 roc auc指标
https://stackoverflow.com/questions/41032551/how-to-compute-receiving-operating-characteristic-roc-a ...
- 一文让你彻底理解准确率,精准率,召回率,真正率,假正率,ROC/AUC
参考资料:https://zhuanlan.zhihu.com/p/46714763 ROC/AUC作为机器学习的评估指标非常重要,也是面试中经常出现的问题(80%都会问到).其实,理解它并不是非常难 ...
- CIKM Competition数据挖掘竞赛夺冠算法陈运文
CIKM Competition数据挖掘竞赛夺冠算法陈运文 背景 CIKM Cup(或者称为CIKM Competition)是ACM CIKM举办的国际数据挖掘竞赛的名称.CIKM全称是Intern ...
- 【分类问题中模型的性能度量(二)】超强整理,超详细解析,一文彻底搞懂ROC、AUC
文章目录 1.背景 2.ROC曲线 2.1 ROC名称溯源(选看) 2.2 ROC曲线的绘制 3.AUC(Area Under ROC Curve) 3.1 AUC来历 3.2 AUC几何意义 3.3 ...
- Spark机器学习 Day2 快速理解机器学习
Spark机器学习 Day2 快速理解机器学习 有两个问题: 机器学习到底是什么. 大数据机器学习到底是什么. 机器学习到底是什么 人正常思维的过程是根据历史经验得出一定的规律,然后在当前情况下根据这 ...
- 动态规划(Dynamic Programming)算法与LC实例的理解
动态规划(Dynamic Programming)算法与LC实例的理解 希望通过写下来自己学习历程的方式帮助自己加深对知识的理解,也帮助其他人更好地学习,少走弯路.也欢迎大家来给我的Github的Le ...
- ROC AUC
1.什么是性能度量? 我们都知道机器学习要建模,但是对于模型性能的好坏(即模型的泛化能力),我们并不知道是怎样的,很可能这个模型就是一个差的模型,泛化能力弱,对测试集不能很好的预测或分类.那么如何知道 ...
- 机器学习性能度量指标:AUC
在IJCAI 于2015年举办的竞赛:Repeat Buyers Prediction Competition 中, 很多参赛队伍在最终的Slides展示中都表示使用了 AUC 作为评估指标: ...
- 【Udacity】机器学习性能评估指标
评估指标 Evaluation metrics 机器学习性能评估指标 选择合适的指标 分类与回归的不同性能指标 分类的指标(准确率.精确率.召回率和 F 分数) 回归的指标(平均绝对误差和均方误差) ...
- 模型评测之IoU,mAP,ROC,AUC
IOU 在目标检测算法中,交并比Intersection-over-Union,IoU是一个流行的评测方式,是指产生的候选框candidate bound与原标记框ground truth bound ...
随机推荐
- 地址标准化服务AI深度学习模型推理优化实践
简介: 深度学习已在面向自然语言处理等领域的实际业务场景中广泛落地,对它的推理性能优化成为了部署环节中重要的一环.推理性能的提升:一方面,可以充分发挥部署硬件的能力,降低用户响应时间,同时节省成本:另 ...
- 使用WebSocket实现实时多人答题对战游戏
前言 前两章教程,我们使用WebSocket的基础特性打造了一个小小聊天室,并在第二章对其进行了集群化改造. 系列教程回顾: [WebSocket]第一章:手把手搭建WebSocket多人在线聊天室( ...
- OpenCV计算机视觉入门之图像色彩空间转换
目录 1. 引言 2. 概念 2.1 数字图像 2.2 色彩空间 3. 实践-图像读取 5. 完整代码 6. 总结 1. 引言 本文通过导入函数库.读取图像.转换图像色彩空间.缩放图像和保存图像五个步 ...
- HH的项链——题解
题目描述 直接求解会导致不同贝壳在上个区间算过但这个区间没标记的情况,所以在求解时要把上个区间的标记转移到这个区间 转移前先右边界由小到大排序,然后转移上个右边界到这个右边界的标记,同时记录上个标记出 ...
- 策略梯度玩 cartpole 游戏,强化学习代替PID算法控制平衡杆
cartpole游戏,车上顶着一个自由摆动的杆子,实现杆子的平衡,杆子每次倒向一端车就开始移动让杆子保持动态直立的状态,策略函数使用一个两层的简单神经网络,输入状态有4个,车位置,车速度,杆角度,杆速 ...
- python计算机视觉学习笔记——PIL库的用法
如果需要处理的原图及代码,请移步小编的GitHub地址 传送门:请点击我 如果点击有误:https://github.com/LeBron-Jian/ComputerVisionPractice 这个 ...
- java的synchronized有几种加锁方式
在Java中,synchronized关键字提供了内置的支持来实现同步访问共享资源,以避免并发问题.synchronized主要有三种加锁方式: 1.同步实例方法 当一个实例方法被声明为synchro ...
- SASS 插值语句 #{ }的使用
在之前我们已经使用用 / 来进行计算,但如下情况不一样 例如 p{ font: 16px/30px Arial, Helvetica, sans-serif; } 如果需要使用变量,同时又要确保 / ...
- 卷爆短剧出海:五大关键,由AIGC重构
短剧高温下,谈谈AIGC的助攻路线. 短剧,一个席卷全球的高温赛道. 以往只是踏着霸总题材,如今,内容循着精品化.IP化的自然发展风向,给内容.制作.平台等产业全链都带来新机,也让短剧消费走向文化深处 ...
- win11如何调解屏幕亮度【win10刚刚升级win11】?
打开电脑后鼠标右键,点击个性化 点击系统 点击屏幕亮度 滑动按钮,调解屏幕亮度即可