策略梯度玩 cartpole 游戏,强化学习代替PID算法控制平衡杆
cartpole游戏,车上顶着一个自由摆动的杆子,实现杆子的平衡,杆子每次倒向一端车就开始移动让杆子保持动态直立的状态,策略函数使用一个两层的简单神经网络,输入状态有4个,车位置,车速度,杆角度,杆速度,输出action为左移动或右移动,输入状态发现至少要给3个才能稳定一会儿,给2个完全学不明白,给4个能学到很稳定的policy
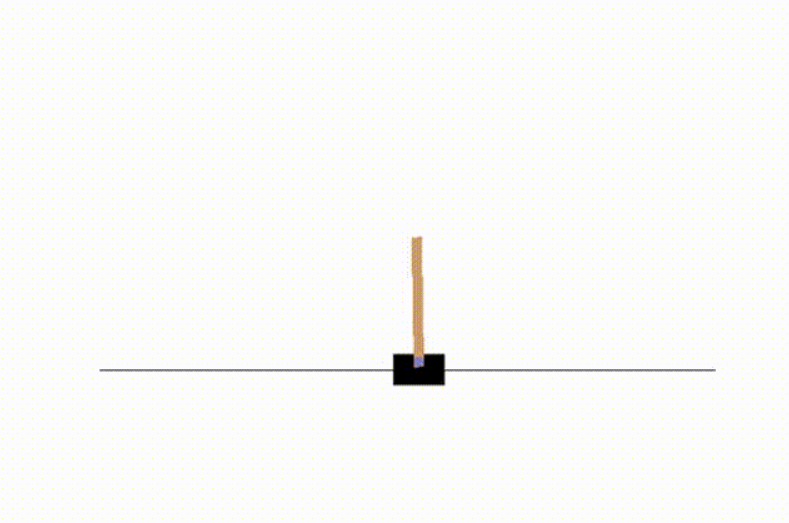
策略梯度实现代码,使用torch实现一个简单的神经网络
import gym
import torch
import torch.nn as nn
import torch.optim as optim
import pygame
import sys
from collections import deque
import numpy as np # 策略网络定义
class PolicyNetwork(nn.Module):
def __init__(self):
super(PolicyNetwork, self).__init__()
self.fc = nn.Sequential(
nn.Linear(4, 10), # 4个状态输入,128个隐藏单元
nn.Tanh(),
nn.Linear(10, 2), # 输出2个动作的概率
nn.Softmax(dim=-1)
) def forward(self, x):
# print(x) 车位置 车速度 杆角度 杆速度
selected_values = x[:, [0,1,2,3]] #只使用车位置和杆角度
return self.fc(selected_values) # 训练函数
def train(policy_net, optimizer, trajectories):
policy_net.zero_grad()
loss = 0
print(trajectories[0])
for trajectory in trajectories: # if trajectory["returns"] > 90:
# returns = torch.tensor(trajectory["returns"]).float()
# else:
returns = torch.tensor(trajectory["returns"]).float() - torch.tensor(trajectory["step_mean_reward"]).float()
# print(f"获得奖励{returns}")
log_probs = trajectory["log_prob"]
loss += -(log_probs * returns).sum() # 计算策略梯度损失
loss.backward()
optimizer.step()
return loss.item() # 主函数
def main():
env = gym.make('CartPole-v1')
policy_net = PolicyNetwork()
optimizer = optim.Adam(policy_net.parameters(), lr=0.01) print(env.action_space)
print(env.observation_space)
pygame.init()
screen = pygame.display.set_mode((600, 400))
clock = pygame.time.Clock() rewards_one_episode= []
for episode in range(10000): state = env.reset()
done = False
trajectories = []
state = state[0]
step = 0
torch.save(policy_net, 'policy_net_full.pth')
while not done:
state_tensor = torch.tensor(state).float().unsqueeze(0)
probs = policy_net(state_tensor)
action = torch.distributions.Categorical(probs).sample().item()
log_prob = torch.log(probs.squeeze(0)[action])
next_state, reward, done, _,_ = env.step(action) # print(episode)
trajectories.append({"state": state, "action": action, "reward": reward, "log_prob": log_prob})
state = next_state for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.quit()
sys.exit()
step +=1 # 绘制环境状态
if rewards_one_episode and rewards_one_episode[-1] >99:
screen.fill((255, 255, 255))
cart_x = int(state[0] * 100 + 300)
pygame.draw.rect(screen, (0, 0, 255), (cart_x, 300, 50, 30))
# print(state)
pygame.draw.line(screen, (255, 0, 0), (cart_x + 25, 300), (cart_x + 25 - int(50 * torch.sin(torch.tensor(state[2]))), 300 - int(50 * torch.cos(torch.tensor(state[2])))), 2)
pygame.display.flip()
clock.tick(200) print(f"第{episode}回合",f"运行{step}步后挂了")
# 为策略梯度计算累积回报
returns = 0 for traj in reversed(trajectories):
returns = traj["reward"] + 0.99 * returns
traj["returns"] = returns
if rewards_one_episode:
# print(rewards_one_episode[:10])
traj["step_mean_reward"] = np.mean(rewards_one_episode[-10:])
else:
traj["step_mean_reward"] = 0
rewards_one_episode.append(returns)
# print(rewards_one_episode[:10])
train(policy_net, optimizer, trajectories) def play(): env = gym.make('CartPole-v1')
policy_net = PolicyNetwork()
pygame.init()
screen = pygame.display.set_mode((600, 400))
clock = pygame.time.Clock() state = env.reset()
done = False
trajectories = deque()
state = state[0]
step = 0
policy_net = torch.load('policy_net_full.pth')
while not done:
state_tensor = torch.tensor(state).float().unsqueeze(0)
probs = policy_net(state_tensor)
action = torch.distributions.Categorical(probs).sample().item()
log_prob = torch.log(probs.squeeze(0)[action])
next_state, reward, done, _,_ = env.step(action) # print(episode)
trajectories.append({"state": state, "action": action, "reward": reward, "log_prob": log_prob})
state = next_state for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.quit()
sys.exit() # 绘制环境状态
screen.fill((255, 255, 255))
cart_x = int(state[0] * 100 + 300)
pygame.draw.rect(screen, (0, 0, 255), (cart_x, 300, 50, 30))
# print(state)
pygame.draw.line(screen, (255, 0, 0), (cart_x + 25, 300), (cart_x + 25 - int(50 * torch.sin(torch.tensor(state[2]))), 300 - int(50 * torch.cos(torch.tensor(state[2])))), 2)
pygame.display.flip()
clock.tick(60)
step +=1 print(f"运行{step}步后挂了") if __name__ == '__main__':
main() #训练
# play() #推理
运行效果,训练过程不是很稳定,有时候学很多轮次也学不明白,有时侯只需要几十次就可以学明白了

策略梯度玩 cartpole 游戏,强化学习代替PID算法控制平衡杆的更多相关文章
- 策略梯度训练cartpole小游戏
我原来已经安装了anaconda,在此基础上进入cmd进行pip install tensorflow和pip install gym就可以了. 在win10的pycharm做的. policy_gr ...
- TensorFlow利用A3C算法训练智能体玩CartPole游戏
本教程讲解如何使用深度强化学习训练一个可以在 CartPole 游戏中获胜的模型.研究人员使用 tf.keras.OpenAI 训练了一个使用「异步优势动作评价」(Asynchronous Advan ...
- DRL 教程 | 如何保持运动小车上的旗杆屹立不倒?TensorFlow利用A3C算法训练智能体玩CartPole游戏
本教程讲解如何使用深度强化学习训练一个可以在 CartPole 游戏中获胜的模型.研究人员使用 tf.keras.OpenAI 训练了一个使用「异步优势动作评价」(Asynchronous Advan ...
- 【强化学习】DQN 算法改进
DQN 算法改进 (一)Dueling DQN Dueling DQN 是一种基于 DQN 的改进算法.主要突破点:利用模型结构将值函数表示成更加细致的形式,这使得模型能够拥有更好的表现.下面给出公式 ...
- 【算法总结】强化学习部分基础算法总结(Q-learning DQN PG AC DDPG TD3)
总结回顾一下近期学习的RL算法,并给部分实现算法整理了流程图.贴了代码. 1. value-based 基于价值的算法 基于价值算法是通过对agent所属的environment的状态或者状态动作对进 ...
- 强化学习(十七) 基于模型的强化学习与Dyna算法框架
在前面我们讨论了基于价值的强化学习(Value Based RL)和基于策略的强化学习模型(Policy Based RL),本篇我们讨论最后一种强化学习流派,基于模型的强化学习(Model Base ...
- 强化学习-时序差分算法(TD)和SARAS法
1. 前言 我们前面介绍了第一个Model Free的模型蒙特卡洛算法.蒙特卡罗法在估计价值时使用了完整序列的长期回报.而且蒙特卡洛法有较大的方差,模型不是很稳定.本节我们介绍时序差分法,时序差分法不 ...
- 强化学习8-时序差分控制离线算法Q-Learning
Q-Learning和Sarsa一样是基于时序差分的控制算法,那两者有什么区别呢? 这里已经必须引入新的概念 时序差分控制算法的分类:在线和离线 在线控制算法:一直使用一个策略选择动作和更新价值函数, ...
- 强化学习读书笔记 - 13 - 策略梯度方法(Policy Gradient Methods)
强化学习读书笔记 - 13 - 策略梯度方法(Policy Gradient Methods) 学习笔记: Reinforcement Learning: An Introduction, Richa ...
- 基于Keras的OpenAI-gym强化学习的车杆/FlappyBird游戏
强化学习 课程:Q-Learning强化学习(李宏毅).深度强化学习 强化学习是一种允许你创造能从环境中交互学习的AI Agent的机器学习算法,其通过试错来学习.如上图所示,大脑代表AI Agent ...
随机推荐
- HTTP协议安全头部的笔记
本文于2016年3月完成,发布在个人博客网站上. 考虑个人博客因某种原因无法修复,于是在博客园安家,之前发布的文章逐步搬迁过来. 近日项目组对当前开发.维护的Web系统做了AppScan扫描,扫描的结 ...
- 在nginx中使用proxy protocol协议
目录 简介 proxy protocol在nginx中应用 在nginx中配置使用proxy protocol 在nginx中启用proxy protocol 使用Real‑IP modules 请求 ...
- Python 中的字符串基础与应用
在Python中,字符串可以用单引号或双引号括起来.'hello' 与 "hello" 是相同的.您可以使用print()函数显示字符串文字: 示例: print("He ...
- Numpy通用函数及向量化计算
Python(Cpython)对于较大数组的循环操作会比较慢,因为Python的动态性和解释性,在做每次循环时,必须做数据类型的检查和函数的调度. Numpy为很多类型的操作提供了非常方便的.静态类型 ...
- 用户触达难?流失率高?HMS Core预测服务和智能运营,助你提前掌握营销时机,解决此难题。
用户流失了,触达难? 活动做了那么多,转化仍然很低? 运营也需要提前思考,预测用户动向,提前精准触达,才能事半功倍.结合HMS Core分析服务的预测服务和智能运营,洞察营销时机,实时落地营销策略,提 ...
- redis 简单整理——哨兵简单介绍[二十八]
前言 简单介绍一下哨兵模式. 正文 Redis的主从复制模式下,一旦主节点由于故障不能提供服务,需要人 工将从节点晋升为主节点,同时还要通知应用方更新主节点地址,对于很多 应用场景这种故障处理的方式是 ...
- 批处理for 的理解及例子
前言 首先for的代码形式是: for %i in (set) do command 这里面有一些小知识知识点: 比如说i是变量,那么i可以换成其他字符吗?答案是可以的.但是必须是26个字母中的其中一 ...
- 重新点亮linux 命令树————二进制安装[十一八]
前言 简单介绍一下二进制安装 正文 wget https://openresty.org/download/openresty-1.15.8.1.tar.gz tar -zxf openresty-V ...
- vue项目中嵌入软键盘(中文/英文)
键盘效果是这样,样式可以自己调整.gittee地址:https://gitee.com/houxianzhou/VirtualKeyboard.git步骤1 安装使用jQuery npm instal ...
- Bilibili资深运维工程师:DCDN在游戏应用加速中的实践
简介: bilibili资深运维工程师李宁分享<DCDN在游戏应用加速中的实践>从bilibili游戏应用的效果和成本入手,深入浅出地分享DCDN全站加速在游戏加速场景中的应用. 日前,云 ...