python SQLAlchemy ORM——从零开始学习03 如何针对数据库信息进行排序
03 如何进行排序
3-1准备工作:
因为要排序,所以需要随机多谢数据,model见后文。也需要random进行随机
from model import User, Engine
from sqlalchemy.orm import sessionmaker
import random
Session = sessionmaker(bind=Engine)
session = Session()
def add_random():
names = ['arthur', 'Abigail Williams', 'caster', 'Lilith']
ages = [14, 18, 20, 21, 23, 25, 28, 30, 31, 100]
for x in range(20):
user = User(name=random.choice(names), age=random.choice(ages)) # 创建随机user
session.add(user) # 这里每次添加,会存放到缓冲区,之后一并提交,虽然可以使用users存放再add_all,但是这增加了开销,不过可读性增加了
session.commit()
数据库可以看到【不一定相等,毕竟是随机,但数量是20就行】:

如果多次点击了导致多于20个怎么办,我确实是点多了一次,用我自己写的这个接口就能删到只剩20了,或者你自己修改都可以
def remove_at_lest_20():
users = session.query(User).filter(User.id > 20).all()
for user_one in users:
session.delete(user_one)
session.commit()
3-2 排序
其实只需要了解order_by()这个接口就好,先看看官方对这个接口的eg:
q = session.query(Entity).order_by(Entity.id, Entity.name)
其实基本上同理,他可以接收多个参数
def order_sort():
Users = session.query(User).order_by(User.age, User.name).all()
# Users = session.query(User).order_by(User.age.desc(), User.name).all() #其中使用.desc可以进行倒序排序
for user in Users:
print(user)
顺序的结果是(部分):
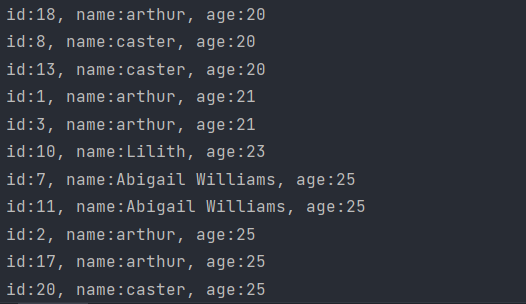
倒叙的结果也是没问题的:
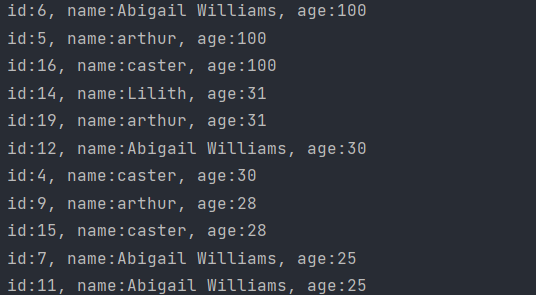
PS:注意,如果后面commit是没有效果的,因为需要显式修改数据库才能记录【如add、del、修改】这里使用排序是不会对源数据进行修改的。
3-3 code
model
from sqlalchemy import create_engine, Integer, String
from sqlalchemy.orm import DeclarativeBase, mapped_column,Mapped
from typing import Optional
url = "sqlite:///database_02.db" #记得修改一下自己的数据库
Engine = create_engine(url,echo=True)
class Base(DeclarativeBase): #通过类构造,这样子会有语法提示
pass
class User(Base): #构造自己的User表
__tablename__ = "User"
id:Mapped[int] = mapped_column(primary_key=True) #构造方法和之前不一样,但是效果是一样的,我这里偷学了,不用管,直接复制就好
name:Mapped[str] = mapped_column(nullable=True)
age:Mapped[Optional[int]]
def __repr__(self): #方便后续直接print的,有兴趣可以了解一下
return f"id:{self.id}, name:{self.name}, age:{self.age}"
Base.metadata.create_all(Engine)
lesson2
from model import User, Engine
from sqlalchemy.orm import sessionmaker
import random
Session = sessionmaker(bind=Engine)
session = Session()
def add_random():
names = ['arthur', 'Abigail Williams', 'caster', 'Lilith']
ages = [14, 18, 20, 21, 23, 25, 28, 30, 31, 100]
for x in range(20):
user = User(name=random.choice(names), age=random.choice(ages)) # 创建随机user
session.add(user) # 这里每次添加,会存放到缓冲区,之后一并提交,虽然可以使用users存放再add_all,但是这增加了开销,不过可读性增加了
session.commit()
def remove_at_lest_20():
users = session.query(User).filter(User.id > 20).all()
for user_one in users:
session.delete(user_one)
session.commit()
def order_sort():
# Users = session.query(User).order_by(User.age, User.name).all()
Users = session.query(User).order_by(User.age.desc(), User.name).all() #其中使用.desc可以进行倒序排序
for user in Users:
print(user)
if __name__ == '__main__':
order_sort()
# remove_at_lest_20()
python SQLAlchemy ORM——从零开始学习03 如何针对数据库信息进行排序的更多相关文章
- Python sqlalchemy orm 外键关联
创建外键关联 并通过relationship 互相调用 如图: 实现代码: import sqlalchemy # 调用链接数据库 from sqlalchemy import create_engi ...
- Python sqlalchemy orm 多对多外键关联
多对多外键关联 注:使用三张表进行对应关联 实现代码: # 创建3个表 配置外键关联 # 调用Column创建字段 加类型 from sqlalchemy import Table, Column, ...
- Python SQLAlchemy ORM示例
SQLAlchemy的是Python的SQL工具包和对象关系映射,给应用程序开发者提供SQL的强大功能和灵活性. 安装 pip install mysql-python pip install sql ...
- Python sqlalchemy orm 常用操作
增add # 创建表1 # 注:高级封装 import sqlalchemy # 调用链接数据库 from sqlalchemy import create_engine # 调用基类Base fro ...
- Python sqlalchemy orm 多外键关联
多外键关联 注:在两个表之间进行多外键链接 如图: 案例: # 创建两张表并添加外键主键 # 调用Column创建字段 加类型 from sqlalchemy import Integer, For ...
- python中orm框架学习
安装sqlalchemy pip3 install sqlalchemy 创建表结构: from sqlalchemy import Column,String,create_engine from ...
- [Python接口自动化]从零开始学习python自动化(1):环境搭建
第一步:安装python编译环境 安装python编译环境之前,必须保证已安装jdk哈,如果为安装,请参考https://jingyan.baidu.com/article/6dad5075d1dc4 ...
- Python SQLAlchemy --3
本文為 Python SQLAlchemy ORM 一系列教學文: 刪除 學會如何查詢之後,就能夠進行後續的刪除.更新等操作. 同樣地,以幾個範例做為學習的捷徑. 123456789 user_1 = ...
- Python SQLAlchemy --2
本文為 Python SQLAlchemy ORM 一系列教學文: 接下來會更深入地探討查詢的使用. 查詢的基本使用法為 session.query(Mapped Class),其後可加 .group ...
- Python SQLAlchemy --1
本文為 Python SQLAlchemy ORM 一系列教學文: SQLAlchemy 大概是目前 Python 最完整的資料庫操作的套件了,不過最令人垢病的是它的文件真的很難閱讀,如果不搭配個實例 ...
随机推荐
- React h5架构
目录 目录 初始化项目架构 React h5架构 工具 技术栈 搭建流程 一.Vite构建项目 二.添加 git 三.运行项目 四.配置 Eslint 校验代码 五.配置 Prettier 格式化代码 ...
- 关于STL容器的简单总结
关于STL容器的简单总结 转载自 1.结构体中重载运算符的示例 //结构体小于符号的重载 struct buf { int a,b; bool operator < (const buf& ...
- MMdetection 问题报错 mmdet/evaluation/metrics/coco_metric.py data[‘category_id’] = self.cat_ids[label] IndexError: list index out of range
方案一:有人说 在自己定义的 conifg文件中增加 metainfo = { 'classes': ('class1','class2', 'class2',), 'palette': [ (220 ...
- 22.使用Rancher2.0搭建Kubernetes集群
使用Rancher2.0搭建Kubernetes集群 中文文档:https://docs.rancher.cn/docs/rancher2 安装Rancher2.0 使用下面命令,我们快速的安装 # ...
- byte,关于127+1等于多少
public class Main { public static void main(String[] args) { Integer i1 = 100; Integer i2 = 100; Int ...
- AT cf17 final J Tree MST
AT cf17 final J Tree MST 考场上想出的黑题,然而写挂了-- 思路 考场推出 boruvka 算法,会的直接跳过就好. 结论:一个点向另外一个点连出的最小边,一定在最小生成树上. ...
- P3920 WC2014 紫荆花之恋
P3920 WC2014 紫荆花之恋 毒瘤题目,动态点分树. 前置科技点 替罪羊树 高速平衡树(除去 fhq_treap 和 splay 之外的所有平衡树) 约定 \(dis(u,v)\) 为原树上 ...
- mysql 批量重命名数据表、统一给表加前缀
背景 一个本地数据库,里面有 90 个数据表.由于历史原因,现在需要批量给以前的数据表加上一个前缀.于是安排人吭哧吭呲的人工修改,耗费一天工时.过了几天,又需要把统一前缀去掉.内心早已问候 @¥#%% ...
- mysql8创建用户
create user test_user@'%' identified by 'test2022@'; grant all privileges on test.* to test_user@'%' ...
- golang之fmt格式化
常用fmt中用于格式化的占位符 普通占位符 占位符 说明 举例 输出 %v 相应值的默认格式. Printf("%v", people) {zhangsan}, %+v 打印结构体 ...