SnowFlake雪花算法
简介
自然界不存在两片完全一样的雪花,每一片都是独一无二的,雪花算法的命名由此而来,所有雪花算法表示生成的ID唯一,且生成的ID是按照一定的结构组成。
组成结构
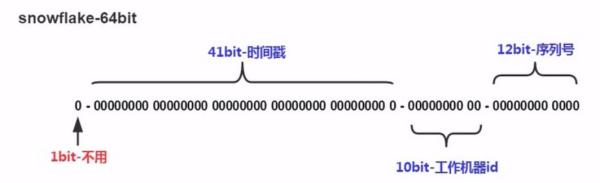
上图可以看到雪花算法的结构由四部分组成,首位无效符,所以我们主要看后面三部分
- 第一部分:由41位的时间戳组成,可以提高查询速度。
- 第二部分:由10位机器码组成,适用于分布式环境下各节点进行标记,10位的长度最多支持部署1024个节点。
- 第三部分:由12位序列号组成,可以同一节点同一毫秒生成多个2^12 - 1(4095)个ID序号。
由于生成的id按时间戳生成,所以ID是按时间递增
分布式系统内不会产生重复ID
使用
环境: .Net Core 3.0
先NuGet一下SnowFlake,这里使用的是Snowflake.Core
下面是实例Demo
private static List<string> list = new List<string>();
static void Main(string[] args)
{
Snowflake.Core.IdWorker work = new Snowflake.Core.IdWorker(1, 1);
for (int i = 0; i < 1000; i++)
{
var id = work.NextId();
if (list.Contains(id.ToString()))
{
Console.WriteLine("存在");
}
else
{
list.Add(id.ToString());
Console.WriteLine(id.ToString());
}
}
}
Code
使用时创建IdWorder对象需要单例,如果重复创建会造成重复生成重复ID
最后附上源码
/**
* Twitter的分布式自增ID雪花算法snowflake
* @author MENG
* @create 2018-08-23 10:21
**/
public class SnowFlake { /**
* 起始的时间戳
*/
private final static long START_STMP = 1480166465631L; /**
* 每一部分占用的位数
*/
private final static long SEQUENCE_BIT = 12; //序列号占用的位数
private final static long MACHINE_BIT = 5; //机器标识占用的位数
private final static long DATACENTER_BIT = 5;//数据中心占用的位数 /**
* 每一部分的最大值
*/
private final static long MAX_DATACENTER_NUM = -1L ^ (-1L << DATACENTER_BIT);
private final static long MAX_MACHINE_NUM = -1L ^ (-1L << MACHINE_BIT);
private final static long MAX_SEQUENCE = -1L ^ (-1L << SEQUENCE_BIT); /**
* 每一部分向左的位移
*/
private final static long MACHINE_LEFT = SEQUENCE_BIT;
private final static long DATACENTER_LEFT = SEQUENCE_BIT + MACHINE_BIT;
private final static long TIMESTMP_LEFT = DATACENTER_LEFT + DATACENTER_BIT; private long datacenterId; //数据中心
private long machineId; //机器标识
private long sequence = 0L; //序列号
private long lastStmp = -1L;//上一次时间戳 public SnowFlake(long datacenterId, long machineId) {
if (datacenterId > MAX_DATACENTER_NUM || datacenterId < 0) {
throw new IllegalArgumentException("datacenterId can't be greater than MAX_DATACENTER_NUM or less than 0");
}
if (machineId > MAX_MACHINE_NUM || machineId < 0) {
throw new IllegalArgumentException("machineId can't be greater than MAX_MACHINE_NUM or less than 0");
}
this.datacenterId = datacenterId;
this.machineId = machineId;
} /**
* 产生下一个ID
*
* @return
*/
public synchronized long nextId() {
long currStmp = getNewstmp();
if (currStmp < lastStmp) {
throw new RuntimeException("Clock moved backwards. Refusing to generate id");
} if (currStmp == lastStmp) {
//相同毫秒内,序列号自增
sequence = (sequence + 1) & MAX_SEQUENCE;
//同一毫秒的序列数已经达到最大
if (sequence == 0L) {
currStmp = getNextMill();
}
} else {
//不同毫秒内,序列号置为0
sequence = 0L;
} lastStmp = currStmp; return (currStmp - START_STMP) << TIMESTMP_LEFT //时间戳部分
| datacenterId << DATACENTER_LEFT //数据中心部分
| machineId << MACHINE_LEFT //机器标识部分
| sequence; //序列号部分
} private long getNextMill() {
long mill = getNewstmp();
while (mill <= lastStmp) {
mill = getNewstmp();
}
return mill;
} private long getNewstmp() {
return System.currentTimeMillis();
} public static void main(String[] args) {
SnowFlake snowFlake = new SnowFlake(1, 1); long start = System.currentTimeMillis();
for (int i = 0; i < 1000000; i++) {
System.out.println(snowFlake.nextId());
} System.out.println(System.currentTimeMillis() - start); }
}
总结
组成结构大致分为了无效位、时间位、机器位和序列号位。其特点是自增、有序、纯数字组成查询效率高且不依赖于数据库。适合在分布式的场景中应用,可根据需求调整具体实现细节。

SnowFlake雪花算法的更多相关文章
- 分布式Snowflake雪花算法
前言 项目中主键ID生成方式比较多,但是哪种方式更能提高的我们的工作效率.项目质量.代码实用性以及健壮性呢,下面作了一下比较,目前雪花算法的优点还是很明显的. 优缺点比较 UUID(缺点:太长.没法排 ...
- .Net Core ORM选择之路,哪个才适合你 通用查询类封装之Mongodb篇 Snowflake(雪花算法)的JavaScript实现 【开发记录】如何在B/S项目中使用中国天气的实时天气功能 【开发记录】微信小游戏开发入门——俄罗斯方块
.Net Core ORM选择之路,哪个才适合你 因为老板的一句话公司项目需要迁移到.Net Core ,但是以前同事用的ORM不支持.Net Core 开发过程也遇到了各种坑,插入条数多了也特别 ...
- 分布式ID生成器 snowflake(雪花)算法
在springboot的启动类中引入 @Bean public IdWorker idWorkker(){ return new IdWorker(1, 1); } 在代码中调用 @Autowired ...
- 说起分布式自增ID只知道UUID?SnowFlake(雪花)算法了解一下(Python3.0实现)
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_155 但凡说起分布式系统,我们肯定会对一些海量级的业务进行分拆,比如:用户表,订单表.因为数据量巨大一张表完全无法支撑,就会对其进 ...
- SnowFlake 雪花算法详解与实现 & MP中的应用
BackGround 现在的服务基本是分布式,微服务形式的,而且大数据量也导致分库分表的产生,对于水平分表就需要保证表中 id 的全局唯一性. 对于 MySQL 而言,一个表中的主键 id 一般使用自 ...
- Snowflake(雪花算法)的JavaScript实现
现在好多的ID都是服务器端生成的,当然JS也可以生成GUID或者UUID之类的,但是如果想要有序……这时就想到了雪花算法,但是都知道JS中Number的最大值为Number.MAX_SAFE_INTE ...
- 分布式主键解决方案之--Snowflake雪花算法
0--前言 对于分布式系统环境,主键ID的设计很关键,什么自增intID那些是绝对不用的,比较早的时候,大部分系统都用UUID/GUID来作为主键,优点是方便又能解决问题,缺点是插入时因为UUID/G ...
- Go语言实现Snowflake雪花算法
转载请声明出处哦~,本篇文章发布于luozhiyun的博客:https://www.luozhiyun.com/archives/527 每次放长假的在家里的时候,总想找点简单的例子来看看实现原理,这 ...
- snowflake 雪花算法 分布式实现全局id生成
snowflake是Twitter开源的分布式ID生成算法,结果是一个long型的ID. 这种方案大致来说是一种以划分命名空间(UUID也算,由于比较常见,所以单独分析)来生成ID的一种算法,这种方案 ...
- 分布式系统为什么不用自增id,要用雪花算法生成id???
1.为什么数据库id自增和uuid不适合分布式id id自增:当数据量庞大时,在数据库分库分表后,数据库自增id不能满足唯一id来标识数据:因为每个表都按自己节奏自增,会造成id冲突,无法满足需求. ...
随机推荐
- 2024-11-27:字符串的分数。用go语言,给定一个字符串 s,我们可以定义其“分数”为相邻字符的 ASCII 码差值绝对值的总和。 请计算并返回字符串 s 的分数。 输入:s = “hello“
2024-11-27:字符串的分数.用go语言,给定一个字符串 s,我们可以定义其"分数"为相邻字符的 ASCII 码差值绝对值的总和. 请计算并返回字符串 s 的分数. 输入:s ...
- Three.js入门-相机控制器
概念介绍 在开始前,我们先看一下效果,我在场景中创建了一个立方体,当我们点击鼠标左键并拖动时,可以旋转相机视角,滚动鼠标滚轮可以缩放相机视角. 相信看了动图效果,大家对相机控件有了一个直观的认识.它是 ...
- CSS 变量与运算
1.变量 变量声明:变量名使用 "--" 为前缀,且区分大小写 /* 全局变量 */ :root{ --bgColor: red; } /* 布局变量 */ p{ --bgColo ...
- 【Amadeus原创】wordpress 从服务器收到预料之外的响应。此文件可能已被成功上传。请检查媒体库或刷新本页。此响应不是合法的JSON响应。解决方法。
两种报错方式: 1.此响应不是合法的JSON响应. 2.从服务器收到预料之外的响应.此文件可能已被成功上传.请检查媒体库或刷新本页. 情况:媒体服务器上传小文件没问题,大一点的文件报这个错误. 原因: ...
- PDFSharp - Graphics 绘制接口
PDFSharp - Graphics Graphics - PDFsharp and MigraDoc Wiki 所有的 Graphics 类型都设计成模仿来自 System.Drawing 命名空 ...
- 2024年1月Java项目开发指南11:axios请求与接口统一管理
axios中文网:https://www.axios-http.cn/ 安装 npm install axios 配置 在src下创建apis文件夹 创建axios.js文件 配置如下: // src ...
- [转]OpenSSL主配置文件openssl.cnf
https://www.cnblogs.com/f-ck-need-u/p/6091027.html openssl系列文章:http://www.cnblogs.com/f-ck-need-u/p/ ...
- .NET 9 中的 多级缓存 HybridCache
HybridCache是什么 在 .NET 9 中,Microsoft 将 HybridCache 带入了框架体系. HybridCache 是一种新的缓存模型,设计用于封装本地缓存和分布式缓存,使用 ...
- Vue3使用Vuex 教程(这才是真正的小白教程!)
我的项目是vue3+element-plus 我是个菜鸡,我不懂前端.想做一个tags的导航标签页.但是点击标签页之后页面仍然是会重新请求.感觉这不就跟没做一样吗? 遂百度GPT,第一种方式采用的就是 ...
- [转]vue调试工具vue-devtools安装及使用(亲测有效,望采纳)
vue调试工具vue-devtools安装及使用(亲测有效,望采纳) 本文主要介绍 vue的调试工具 vue-devtools 的安装和使用 工欲善其事, 必先利其器, 快快一起来用vue-devto ...