你应该懂得AI大模型(十三) 之 推理框架
在大语言模型(LLM)技术爆发的今天,从 ChatGPT 到开源的 LLaMA、Qwen 系列,模型能力不断突破,但将这些 “智能大脑” 落地到实际业务中,却面临着效率、成本和部署复杂度的三重挑战。此时,大模型推理框架成为了连接理论与实践的关键桥梁。
一、什么是大模型推理框架
大模型推理框架是专门优化预训练大模型 “推理阶段” 的工具集,专注于解决模型部署中的效率、成本和工程化问题。与训练框架(如 PyTorch、TensorFlow)不同,推理框架不参与模型参数的学习过程,而是聚焦于如何让训练好的模型在生产环境中更快速、更经济、更稳定地响应请求。
简单来说,训练框架负责 “教会模型思考”,而推理框架负责 “让模型高效地回答问题”。
二、推理框架的核心作用
推理框架的核心作用
1、提升响应速度
未经优化的大模型推理可能需要数秒甚至数十秒才能生成结果,而推理框架通过注意力机制优化(如 PagedAttention)、动态批处理等技术,可将延迟压缩至毫秒级,满足实时交互场景需求
2、降低资源消耗
大模型动辄数十亿甚至千亿参数,原生推理需占用数十 GB 显存。推理框架通过量化技术(如 INT4/INT8)、KV 缓存优化等手段,可将显存占用降低 50%-75%,同时支持单 GPU 部署更大模型。
3、简化工程落地
提供开箱即用的 API 服务(REST/gRPC)、负载均衡、动态扩缩容等功能,将复杂的分布式推理逻辑封装成简单接口,让开发者无需深入底层优化即可部署高可用服务。
4、适配多样化场景
支持云服务器、边缘设备、端侧终端等多环境部署,兼容 NVIDIA GPU、AMD GPU、CPU 甚至专用 AI 芯片(如昇腾),满足不同企业的硬件条件。
三、主流大模型推理框架
目前市场上的推理框架可分为 “通用型”(适配多模型和硬件)和 “专用型”(针对特定场景深度优化),以下是企业级项目中最常用的几种:
1. vLLM:高吞吐量的开源明星
由 UC Berkeley 团队开发的 vLLM,凭借其创新的PagedAttention 技术(借鉴操作系统内存分页机制管理 KV 缓存)成为开源社区的焦点。
核心优势:
支持动态批处理(Continuous Batching),吞吐量是原生 Hugging Face Transformers 的 10-20 倍;
无缝兼容 Hugging Face 模型格式,LLaMA、Mistral、Qwen 等主流模型可直接部署;
轻量级设计,单条命令即可启动服务,适合快速测试和生产部署。
适用场景:高并发 API 服务(如客服机器人、内容生成平台),尤其适合 NVIDIA GPU 环境。
2. Text Generation Inference(TGI):Hugging Face 生态的官方选择
作为 Hugging Face 推出的推理框架,TGI 深度集成了 Transformers、Tokenizers 等工具链,是开源模型部署的 “嫡系” 方案。
核心优势:
支持张量并行(多 GPU 拆分模型),轻松部署 13B/70B 等大模型;
•
内置日志、监控和 A/B 测试工具,便于企业级运维;
原生支持流式输出(Stream),优化对话交互体验。
适用场景:依赖 Hugging Face 生态的企业,或需要快速部署开源模型进行验证的场景。
3. TensorRT-LLM:NVIDIA 硬件的性能王者
NVIDIA 官方推出的 TensorRT-LLM 是基于 TensorRT 引擎的大模型推理优化框架,专为 NVIDIA GPU 打造。
核心优势:
采用编译型优化(将模型转为 TensorRT 引擎),延迟比 vLLM 低 30%-50%;
支持 INT4/INT8 量化和稀疏性优化,在 H100/A100 等高端 GPU 上性能极致;
提供 C++/Python 接口,支持多模型并行策略。
适用场景:对延迟敏感的工业级场景(如金融风控、实时对话),需依赖 NVIDIA GPU。
4. LMDeploy:轻量高效的多场景适配者
、 LMDeploy 以 “轻量、高效、多场景兼容” 为特色,尤其对国产模型支持友好。
核心优势:
支持 INT4/INT8/FP16 多种精度,可在消费级 GPU(如 RTX 3090)甚至 CPU 上部署;
提供模型转换、量化、服务部署全链路工具,降低工程门槛;
适配 Qwen、LLaMA、Baichuan 等主流模型,国产模型优化更精细。
适用场景:资源受限的边缘设备、多模型混合部署场景,或国产模型优先的企业。
5. DeepSpeed-Inference:超大规模模型的分布式专家
由 Microsoft 和华盛顿大学联合开发的 DeepSpeed-Inference,专为千亿级参数模型设计。
核心优势:
支持张量并行、管道并行等多种分布式策略,可拆分 100B + 参数模型;
集成 ZeRO 优化技术,减少多 GPU 通信开销;
兼容 PyTorch 生态,便于与训练流程衔接。
适用场景:需要部署超大规模模型(如 GPT-3 175B、LLaMA 70B)的企业,需多 GPU 集群支持。
四、推理框架的核心差异与选型维度
不同框架的差异主要体现在技术路线、硬件适配和功能侧重上,企业选型时需关注以下维度:
1. 性能指标:延迟 vs 吞吐量
低延迟优先:TensorRT-LLM(编译优化)> vLLM(PagedAttention)> TGI;
高吞吐量优先:vLLM(动态批处理)> TGI > LMDeploy;
显存效率:LMDeploy(量化优化)> TensorRT-LLM(INT4)> vLLM。
2. 硬件兼容性
NVIDIA GPU 专属:TensorRT-LLM(性能最佳)、vLLM(兼容性好);
跨硬件支持:LMDeploy(CPU/GPU/ 边缘设备)、ONNX Runtime(多芯片适配);
国产芯片适配:LMDeploy(昇腾支持)、ONNX Runtime(寒武纪 / 地平线插件)。
3. 模型兼容性
开源模型全覆盖:TGI(Hugging Face 生态)、vLLM(主流模型);
国产模型优化:LMDeploy(Qwen/Baichuan)> TGI > TensorRT-LLM;
超大规模模型:DeepSpeed-Inference(100B + 参数)> TensorRT-LLM(张量并行)。
4. 部署复杂度
快速上手:vLLM(单命令启动)、TGI(Docker 一键部署);
工业级部署:TensorRT-LLM(需编译模型)、DeepSpeed-Inference(分布式配置);
轻量部署:LMDeploy(资源占用低)、ONNX Runtime(跨平台打包)。
五、使用LMdeploy部署模型
笔者使用的是Autodl服务器,因此需要做个SSH隧道。
5.1配置Conda环境--javascripttypescriptshellbashsqljsonhtmlcssccppjavarubypythongorustmarkdown
conda create -n lmdeploy python=3.10 -y
conda activate lmdeploy
pip install lmdeploy modelscope gradio partial-json-parser
export LMDEPLOY_USE_MODELSCOPE=True
验证lmdeploy安装--
lmdeploy --version
5.2下载模型
#这些库大家缺啥装啥就可以,不是都得装,看服务器提示缺什么。
pip install modelscope
pip install openai.
pip install tqdm.
pip install transformers
pip install vllm#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen3-4B',cache_dir="/root/autodl-tmp/ddq")5.3模型转换
LMDeploy 推荐使用 convert 命令将模型转换为高效推理格式:
lmdeploy convert qwen3 Qwen3-7B-Chat --dst-path qwen3-7b-chat-lmdeploy
转换后的模型将存储在 qwen3-7b-chat-lmdeploy 目录,包含优化后的权重和配置文件。
此项非必选。
5.4启动推理服务
lmdeploy serve api_server /root/autodl-tmp/ddq/Qwen/Qwen3-4B --reasoning-parser qwen-qwq --server-port 23333 --session-len 8192
mdeploy serve api_server:LMDeploy 的核心命令,用于启动 API 服务端/tmp/code/models/Qwen3-0.6B:指定 Qwen3-0.6B 模型的本地路径--reasoning-parser qwen-qwq:指定使用 Qwen 系列的qwq推理解析器,适配 Qwen 模型的对话格式和推理逻辑--server-port 23333:设置 API 服务监听的端口为 23333(默认通常是 8000)--session-len 8192:设置会话上下文长度为 8192 tokens,控制模型能处理的历史对话 + 当前查询的总长度执行这条命令后,LMDeploy 会加载指定的 Qwen3-0.6B 模型,并在本地 23333 端口启动一个 HTTP API 服务,你可以通过发送 HTTP 请求与模型进行交互。
5.4.1 生产环境部署(本文实验未使用这种部署方式)
1、docker部署
# 拉取 LMDeploy 镜像
docker pull kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/lmdeploy:latest
# 启动容器
docker run -d --gpus all \
-p 8000:8000 \
-v /path/to/qwen3-7b-chat-lmdeploy:/model \
kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/lmdeploy \
lmdeploy serve api_server /model --server-port 8000
2、在 Kubernetes 中部署(使用 Arena)
arena serve custom \
--name=lmdeploy-qwen3 \
--version=v1 \
--gpus=1 \
--replicas=1 \
--restful-port=8000 \
--readiness-probe-action="tcpSocket" \
--readiness-probe-action-option="port: 8000" \
--readiness-probe-option="initialDelaySeconds: 60" \ # Qwen3启动较慢,延长初始检查时间
--readiness-probe-option="periodSeconds: 30" \
--image=kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/lmdeploy:latest \
--data=qwen3-model:/model/Qwen3-7B-Chat \ # 挂载模型数据卷
"lmdeploy serve api_server /model/Qwen3-7B-Chat --server-port 8000"
5.4.2 通过MobaXterm建立SSH隧道
笔者喜欢在vscode中使用remote插件直接进行端口转发,因为笔者没有那么多服务器管理的需求,这个习惯因人而已。
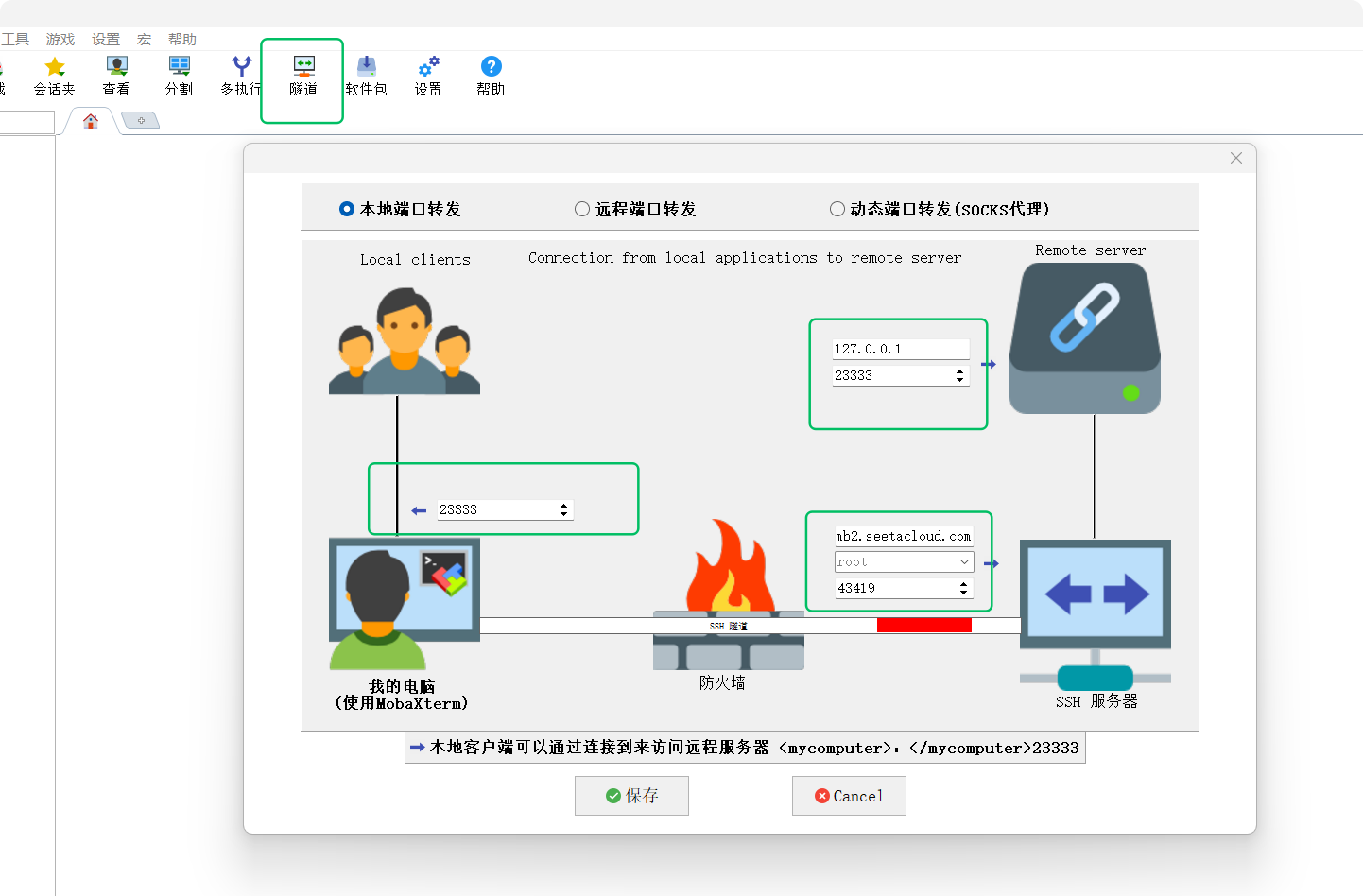

5.4.3 在CherryStudio中测试隧道效果

你应该懂得AI大模型(十三) 之 推理框架的更多相关文章
- AI大模型学习了解
# 百度文心 上线时间:2019年3月 官方介绍:https://wenxin.baidu.com/ 发布地点: 参考资料: 2600亿!全球最大中文单体模型鹏城-百度·文心发布 # 华为盘古 上线时 ...
- 华为高级研究员谢凌曦:下一代AI将走向何方?盘古大模型探路之旅
摘要:为了更深入理解千亿参数的盘古大模型,华为云社区采访到了华为云EI盘古团队高级研究员谢凌曦.谢博士以非常通俗的方式为我们娓娓道来了盘古大模型研发的"前世今生",以及它背后的艰难 ...
- 保姆级教程:用GPU云主机搭建AI大语言模型并用Flask封装成API,实现用户与模型对话
导读 在当今的人工智能时代,大型AI模型已成为获得人工智能应用程序的关键.但是,这些巨大的模型需要庞大的计算资源和存储空间,因此搭建这些模型并对它们进行交互需要强大的计算能力,这通常需要使用云计算服务 ...
- 文心一言,通营销之学,成一家之言,百度人工智能AI大数据模型文心一言Python3.10接入
"文心"取自<文心雕龙>一书的开篇,作者刘勰在书中引述了一个古代典故:春秋时期,鲁国有一位名叫孔文子的大夫,他在学问上非常有造诣,但是他的儿子却不学无术,孔文子非常痛心 ...
- HBase实践案例:知乎 AI 用户模型服务性能优化实践
用户模型简介 知乎 AI 用户模型服务于知乎两亿多用户,主要为首页.推荐.广告.知识服务.想法.关注页等业务场景提供数据和服务, 例如首页个性化 Feed 的召回和排序.相关回答等用到的用户长期兴趣特 ...
- zz独家专访AI大神贾扬清:我为什么选择加入阿里巴巴?
独家专访AI大神贾扬清:我为什么选择加入阿里巴巴? Natalie.Cai 拥有的都是侥幸,失去的都是人生 关注她 5 人赞同了该文章 本文由 「AI前线」原创,原文链接:独家专访AI大神贾扬清:我 ...
- 阿里开源新一代 AI 算法模型,由达摩院90后科学家研发
最炫的技术新知.最热门的大咖公开课.最有趣的开发者活动.最实用的工具干货,就在<开发者必读>! 每日集成开发者社区精品内容,你身边的技术资讯管家. 每日头条 阿里开源新一代 AI 算法模型 ...
- 搭乘“AI大数据”快车,肌肤管家,助力美业数字化发展
经过疫情的发酵,加速推动各行各业进入数据时代的步伐.美业,一个通过自身技术.产品让用户变美的行业,在AI大数据的加持下表现尤为突出. 对于美妆护肤企业来说,一边是进入存量市场,一边是疫后的复苏期,一边 ...
- DeepSpeed Chat: 一键式RLHF训练,让你的类ChatGPT千亿大模型提速省钱15倍
DeepSpeed Chat: 一键式RLHF训练,让你的类ChatGPT千亿大模型提速省钱15倍 1. 概述 近日来,ChatGPT及类似模型引发了人工智能(AI)领域的一场风潮. 这场风潮对数字世 ...
- 无插件的大模型浏览器Autodesk Viewer开发培训-武汉-2014年8月28日 9:00 – 12:00
武汉附近的同学们有福了,这是全球第一次关于Autodesk viewer的教室培训. :) 你可能已经在各种场合听过或看过Autodesk最新推出的大模型浏览器,这是无需插件的浏览器模型,支持几十种数 ...
随机推荐
- Fastapi中Swagger UI加载缓慢的解决方案
在国内网络经常遇到Swagger UI加载缓慢的问题,这是由于Swagger UI的CSS和JS代码源在国外导致的,所以我们的解决方法是更改Swagger UI的CSS代码和JS代码源到国内的CND实 ...
- Druid监控页面配置
springboot的yml配置文件添加如下配置: spring: # 数据库连接相关配置 datasource: druid: filters: stat,wall stat-view-servle ...
- 不得不说一下vite
vite简介 Vite 是一个由原生 ESM 驱动的 Web 开发构建工具.在开发环境下基于浏览器原生 ES imports 开发,在生产环境下基于 Rollup 打包. vite作用 快速的冷启动: ...
- ABB机器人指令 PackRawBytes
参数: Value, RawData \Network , StartIndex ,\Hex1|IntX|\Float4|\ASCII; Value: 需要打包的数据, 类型包含num.dnum, b ...
- HyperWorks的shrink warp meshing
在HyperWorks中,针对某些具有复杂几何特征的零部件的网格剖分,Altair HyperMesh 向用户提供了一种名为 Shrink Warp Meshing 的技术,快捷高效地完成有限元模型前 ...
- MKL库线性方程组求解(LAPACKE_?gesv)
LAPACK(Linear Algebra PACKage)库,是用Fortran语言编写的线性代数计算库,包含线性方程组求解(\(AX=B\)).矩阵分解.矩阵求逆.求矩阵特征值.奇异值等.该库用B ...
- AB test样本量计算器的具体使用方法
在实际的AB test中一般都是直接使用一些AB test计算工具求解的,一方面是公式太复杂记不住,计算也比较耗费时间,另一方面在老板眼里计算器计算反而比手动计算更不容易出错 接下来以用的比较多的ev ...
- js下载cos或者oos资源
const url = "http://cos.dshvv.com/aegis/xby.mp3"; const btn = document.querySelector(" ...
- CF1918B Minimize Inversions 题解
CF1918B Minimize Inversions 诈骗题,点破一文不值. 交换元素 \(i,j\) 时可能有以下四种情况: 情况一:\(a_i\lt a_j,b_i\lt b_j\),此时总逆序 ...
- 前端开发系列070-JQuery篇之框架事件处理
JavaScript以事件驱动来实现页面的交互,其核心是以消息为基础,以事件来驱动.虽然利用传统的JavaScript事件处理方式也能够完成页面交互,但jQuery框架增加并扩展了基本的事件处理机制, ...