hadoop部署安装(四)KAFKA+SCALA
3.8 配置scala
下载,解压
wget https://downloads.lightbend.com/scala/2.13.0-M5/scala-2.13.0-M5.tgz
tar -zxvf scala-2.13.0-M2.tgz
mv scala-2.13.0-M5 /usr/local/scala
环境变量设置
sudo vi /etc/profile
#scala
export SCALA_HOME=/usr/local/scala
export PATH=${SCALA_HOME}/bin:$PATH
source /etc/profile
执行 scala 命令,输出以下信息,表示安装成功:
scala

3.9配置Kafka
解压文件,移动到约定目录,进入config配置文件server.properties
tar xf kafka_2.12-2.3.0.tgz
mv kafka_2.12-2.3.0 /usr/local/kafka
cd /usr/local/kafka/config
vim server.properties
修改第一处:
broker.id=0
host.name=master
#master节点为0,slave1为1,slave2为2。
修改第二处:
log.dirs=/usr/local/kafka/logs
zookeeper.connect=master:2181,slave1:2181,slave2:2181
#规定日志路径,便于排错。
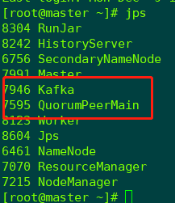
启动kafka,必须优先启动zookeeper
/usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
hadoop部署安装(四)KAFKA+SCALA的更多相关文章
- Hadoop 2.2.0部署安装(笔记,单机安装)
SSH无密安装与配置 具体配置步骤: ◎ 在root根目录下创建.ssh目录 (必须root用户登录) cd /root & mkdir .ssh chmod 700 .ssh & c ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十二)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网。
Centos7出现异常:Failed to start LSB: Bring up/down networking. 按照<Kafka:ZK+Kafka+Spark Streaming集群环境搭 ...
- Hadoop教程(五)Hadoop分布式集群部署安装
Hadoop教程(五)Hadoop分布式集群部署安装 1 Hadoop分布式集群部署安装 在hadoop2.0中通常由两个NameNode组成,一个处于active状态,还有一个处于standby状态 ...
- Hadoop之中的一个:Hadoop的安装部署
说到Hadoop不得不说云计算了,我这里大概说说云计算的概念,事实上百度百科里都有,我仅仅是copy过来,好让我的这篇hadoop博客内容不显得那么单调.骨感.云计算近期今年炒的特别火,我也是个刚開始 ...
- kafka&&kafka-manager部署安装
一.zk集群部署 二.kafka部署安装 1.创建kafka用户和日志路径,(直接执行) groupadd kafka useradd -g kafka kafka mkdir -p /web/kaf ...
- Hadoop学习---安装部署
hadoop框架 Hadoop使用主/从(Master/Slave)架构,主要角色有NameNode,DataNode,secondary NameNode,JobTracker,TaskTracke ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网。
使用VMW安装四台CentOS-7-x86_64-DVD-1804.iso虚拟机: 计划配置三台centos虚拟机: master:192.168.0.120 slave1:192.168.0.121 ...
- hadoop+yarn+hbase+storm+kafka+spark+zookeeper)高可用集群详细配置
配置 hadoop+yarn+hbase+storm+kafka+spark+zookeeper 高可用集群,同时安装相关组建:JDK,MySQL,Hive,Flume 文章目录 环境介绍 节点介绍 ...
- Spark集群 + Akka + Kafka + Scala 开发(2) : 开发一个Spark应用
前言 在Spark集群 + Akka + Kafka + Scala 开发(1) : 配置开发环境,我们已经部署好了一个Spark的开发环境. 本文的目标是写一个Spark应用,并可以在集群中测试. ...
- Spark集群 + Akka + Kafka + Scala 开发(1) : 配置开发环境
目标 配置一个spark standalone集群 + akka + kafka + scala的开发环境. 创建一个基于spark的scala工程,并在spark standalone的集群环境中运 ...
随机推荐
- 安全可信 | 通过双项测试!TeleDB实力亮剑!
近日,天翼云TeleDB数据库在中国信通院"可信数据库"系列测试的赛道上,一次性跨越"分布式事务型数据库基础能力测试"与"性能测试"的双重大 ...
- 玩转云端 | 天翼云边缘安全加速平台AccessOne实用窍门之多款产品管理难?一站式平台管理全hold住!
随着数字化转型深入推进,企业信息化建设成效显著,同时其所面临的安全与性能挑战也日趋复杂,既要确保业务系统的安全性,同时也要提供快速.流畅的用户体验,以提升用户满意度和业务竞争力. 在传统的解决方案中, ...
- Prometheus修改默认数据存储时间
Prometheus修改默认数据存储时间 Prometheus 的数据存储时间是通过命令行参数 --storage.tsdb.retention.time 来设置的.这个参数指定了 Prometheu ...
- EMR集群信息查看-Hive
一.日志 1.hivemetastore日志 简介:查看运行情况,其它组件会通过hivemetastore获取表信息 tail -f /data/emr/hive/logs/hadoop-hiveme ...
- Luogu P8710 [蓝桥杯 2020 省 AB1] 网络分析 题解 [ 绿 ] [ 带权并查集 ]
原题 分析 本题由于从一个节点发信息,同一个集合内的所有点都会收到信息,显然是一道要求维护各节点间关系的题,因此采用并查集的数据结构进行求解. 但由于维护关系的同时还要维护权值,所以采用带权并查集,它 ...
- ABB喷涂机器人控制柜维护保养
ABB喷涂机器人的管理与维护保养目的是减少机器人的故障率和停机时间,充分利用机器人这一生产要素,最大限度地提高产效率.喷涂机器人维修与保养在企业生产中尤为重要,直接影响到系统的寿命,必须精心维护. A ...
- Android设备基础信息获取 源码修改方式 APK开发
APK 获取设备信息 头文件 import java.io.BufferedReader; import java.io.File; import java.io.FileFilter; import ...
- Typescript通用帮助类,格式化日期时间等
/** * 格式化日期选项 */ export class DateFormatOption { "M+": number;//月 "d+": number;/ ...
- Linux - centos6.6升级openssh9.7p1
一.注意事项 1.任何会被修改的配置文件都要提前备份 2.每一步操作都要记录 3.提前预演,知道可能遇到的问题,以及对应的解决方法,能够在生产环境上升级时,更快完成操作. 4.一开始用来操作的ssh会 ...
- 【Pre】Exercise Log
Pre2 #Task1 测评机(Java8)不支持enhanced Switch. Switch中,将case后的:改为->后,将会取消fall through,可以删去break; #Task ...