NodeJs实现简单的爬虫
1.爬虫:爬虫,是一种按照一定的规则,自动地抓取网页信息的程序或者脚本;利用NodeJS实现一个简单的爬虫案例,爬取Boss直聘网站的web前端相关的招聘信息,以广州地区为例;
2.脚本所用到的nodejs模块
express 用来搭建一个服务,将结果渲染到页面
swig 模板引擎
cheerio 用来抓取页面的数据
requests 用来发送请求数据(具体可查:https://www.npmjs.com/package/requests)
async 用来处理异步操作,解决请求嵌套的问题,脚本中只使用了async.whilst(test,iteratee,callback),具体可见:https://caolan.github.io/async/
3.实现流程:
首先先获取到所爬取页面的URL,打开boss直聘网站,搜索web前端既可以获取到https://www.zhipin.com/c101280100-p100901/?page=1&ka=page-next

然后通过Chrome浏览器打开F12,获取到信息中多对应的dom节点,即可知道想要获取信息;
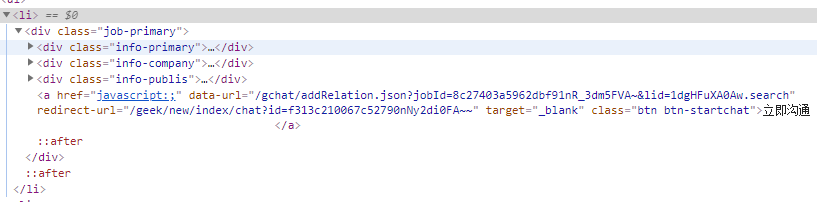
4.代码实现
目录结构:
app.js
var cheerio = require('cheerio');
var requests = require('requests');
var async = require('async');
var express = require('express');
var swig = require('swig');
var app = express();
swig.setDefaults({cache:false});
app.set('views','./views/');
app.set('view engine','html');
app.engine('html',swig.renderFile);
app.get('/',function(req,res,next){
var page = 1; //当前页数
var list = []; //保存记录
async.whilst(
function(){
return page < 11;
},
function(callback){
requests(`https://www.zhipin.com/c101280100-p100901/?page=${page}&ka=page-next`)
.on('data',function(chunk){
var $ = cheerio.load(chunk.toString());
$('.job-primary').each(function(){
var company = $(this).find('.info-company .company-text .name').text();
var job_title = $(this).find('.info-primary .name .job-title').text();
var salary = $(this).find('.info-primary .name .red').text();
var description = $(this).find('.info-company .company-text p').text();
var area = $(this).find('.info-primary p').text();
var item = {
company:company,
job_title:job_title,
salary:salary,
description:description,
area:area
};
list.push(item);
});
page++;
callback();
}).on('end',function(err){
if(err){
console.log(err);
}
if(page==10){
res.render('index',{
lists:list
});
}
});
},
function(err){
console.log(err);
}
);
});
//监听
app.listen(8080);
view/index.html页面
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
</head>
<style>
table{
width:1300px;
border:1px solid #ccc;
border-collapse: collapse;
text-align: center;
margin:0 auto;
}
td,tr,th{
border:1px solid #ccc;
border-collapse: collapse;
}
tr{
height:30px;
line-height: 30px;
}
</style>
<body>
<table>
<thead>
<tr>
<th>公司名称</th>
<th>公司地址</th>
<th>薪资</th>
<th>公司描述</th>
<th>岗位名称</th>
</tr>
</thead>
<tbody>
{% for list in lists %}
<tr>
<td>{{list.company}}</td>
<td>{{list.area}}</td>
<td>{{list.salary}}</td>
<td>{{list.description}}</td>
<td>{{list.job_title}}</td>
</tr>
{% endfor %}
</tbody>
</table> </body>
</html>
5.启动
直接通过 node app.js启动即可;
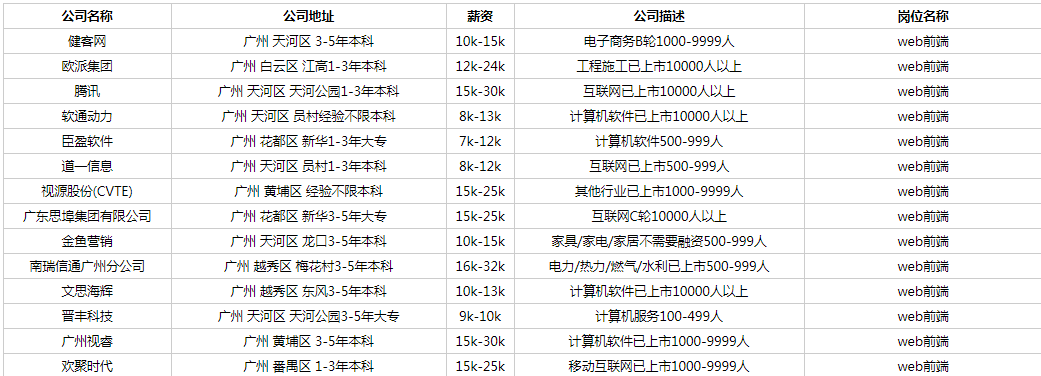
6.运行结果(http://localhost:8080),只截取部分数据
NodeJs实现简单的爬虫的更多相关文章
- 视频博文结合的教程:用nodejs实现简单的爬虫
教学视频地址: https://v.qq.com/x/page/b0643tut4ze.html 前言 本喵最近工作中需要使用node,并也想晋升为全栈工程师,所以开始了node学习之旅,在学习过 ...
- nodeJS实现简单网页爬虫功能
前面的话 本文将使用nodeJS实现一个简单的网页爬虫功能 网页源码 使用http.get()方法获取网页源码,以hao123网站的头条页面为例 http://tuijian.hao123.com/h ...
- nodejs的简单爬虫
闲聊 好久没写博客了,前几天小颖在朋友的博客里看到了用nodejs的简单爬虫.所以小颖就自己试着做了个爬博客园数据的demo.嘻嘻...... 小颖最近养了条泰日天,自从养了我家 ...
- nodejs实现最简单的爬虫
本文将以抓取百度搜索结果中关键词的相关搜索为例子,教会大家以nodejs制作最简单的爬虫: 开始之前呢,先来个公众号求粉: 将使用的node模块及属性介绍: request: ...
- 用nodejs实现简单爬虫
前言 本喵最近工作中需要使用node,并也想晋升为全栈工程师,所以开始了node学习之旅,在学习过程中, 我会总结一些实用的例子,做成博文和视频教程,以实例形式来理解体会node的用法,所以跟小猫 ...
- 每天几分钟跟小猫学前端之node系列:用node实现最简单的爬虫
先来段求分小视频: https://www.iesdouyin.com/share/video/6550631947750608142/?region=CN&mid=6550632036246 ...
- 用node.js从零开始去写一个简单的爬虫
如果你不会Python语言,正好又是一个node.js小白,看完这篇文章之后,一定会觉得受益匪浅,感受到自己又新get到了一门技能,如何用node.js从零开始去写一个简单的爬虫,十分钟时间就能搞定, ...
- Selenium + PhantomJS + python 简单实现爬虫的功能
Selenium 一.简介 selenium是一个用于Web应用自动化程序测试的工具,测试直接运行在浏览器中,就像真正的用户在操作一样 selenium2支持通过驱动真实浏览器(FirfoxDrive ...
- asp.net简单小爬虫
所谓爬虫简单点说,就是把别人网站上的东西爬下来,至于爬做什么用就看你自己了,比如:把别人网站上的东西爬下来放在自己网站中(感觉有点像小偷^v^). 这里随便写了一个爬虫代码(可以自己再去进行完善): ...
随机推荐
- Java学习---常见的模式
Java的常见模式 适配器模式 package com.huawei; import java.io.BufferedReader; import java.io.IOException; impor ...
- 5 hbase-shell + hbase的java api
本博文的主要内容有 .HBase的单机模式(1节点)安装 .HBase的单机模式(1节点)的启动 .HBase的伪分布模式(1节点)安装 .HBase的伪分布模式(1节点)的启动 .HBase ...
- Azure Internet 负载均衡器建立
摘自微软官方文档 Azure load balancer 是位于第 4 层 (TCP, UDP) 的负载均衡器. 该负载均衡器可以在云服务或负载均衡器集的虚拟机中运行状况良好的服务实例之间分配传入流量 ...
- [BZOJ 2322][BeiJing2011]梦想封印
梦想封印 题意 原题面: Problem 2322. -- [BeiJing2011]梦想封印 2322: [BeiJing2011]梦想封印 Time Limit: 20 Sec Memory L ...
- 只用最适合的! 全面对比主流 .NET 报表控件:水晶报表、FastReport、ActiveReports 和 Stimulsoft
前言 随着 .NET 平台的出现,报表相关的开发控件随之出现,目前已经有若干成熟的产品可供开发人员使用,本文旨在通过从不同维度对比目前最流行的4款 .NET报表控件,给所有报表开发人员在做产品选型时一 ...
- Github的commit规范
参考链接:GIT写出好的 commit message 基本要求 第一行应该少于50个字. 随后是一个空行 第一行题目也可以写成:Fix issue #8976 永远不在 git commit 上增加 ...
- Alpha Scrum2
Alpha Scrum2 牛肉面不要牛肉不要面 Alpha项目冲刺(团队作业5) 各个成员在 Alpha 阶段认领的任务 林志松:督促和监督团队进度.协调组内合作,前端页面编写,博客发布 林书浩.陈远 ...
- poi导出excel出现本工作薄不能再使用其他新字体的解决方法
最近使用POI处理EXCEL,当处理的单元格太多时,就会出现,本工作薄使用字体过多,不能再使用其他新的字体的是提示. 网上很多方法告诉我,要怎么修改excel文件,但是这个解决不了问题啊,难道让客户去 ...
- Safari自动代理
1. 准备一个代理服务器,我使用的是GoAgent. 2. 准备一个PAC文件,我是从chrome导出的. 3. 准备一个本地文件服务器或web服务器,我是因为手头有一个使用NodeJS的小项目,所以 ...
- Django创建基本流程
Django创建基本流程 1.创建工程:django-admin startproject 工程名 2.创建应用:python manage.py startapp 应用名 3.激活项目:修改sett ...