DeepCoder: A Deep Neural Network Based Video Compression
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!
Abstract:
在深度学习的最新进展的启发下,我们提出了一种基于卷积神经网络(CNN)的视频压缩框架DeepCoder。我们分别对预测信号和残差信号应用独立的CNN网络。采用标量量化和哈夫曼编码将量化后的特征映射编码为二进制流。本文采用固定的32×32块来证明我们的想法,并与已知的H.264/AVC视频编码标准进行了性能比较,具有可比较的率失真性能。这里使用结构相似性(SSIM)来测量失真,因为它更接近感知响应。
I. INTRODUCTION:
视频压缩是本地存储和网络流媒体的一个重要过程。例如,一秒的1080p 30Hz(即fps或帧/秒)YUV 420格式的原始视频大小约为93MB。即使是最新的无线网络,都不能实时地以如此高的速率支持这些原始视频数据的传输。几乎所有著名的视频压缩标准都是采用基于运动补偿和变换的混合编码框架[1]。预测信号 fp 是使用相邻像素或时域位移块构造的,然后对残差 fr 进行变换、量化,最后进行熵编码。为了提高重构信号的质量,引入了必要的滤波器,如去块效应、采样自适应偏移(SAO)。
同时,研究人员试图探索其他的可能性,例如使用学习到的字典,或者使用固定或自适应原子[2]–[4]加上固定变换基(如DCT)。在这种实现中,块由加权(稀疏)字典和转换的基系数表示。
受到深度学习的启发,基于神经网络的图像有损压缩[5]–[7]引起了学术界和工业界的广泛关注。特别是谷歌的研究人员最近发表了两篇论文,涉及使用递归神经网络(RNN)进行缩略图和全分辨率图像压缩[6],[7]。它由连接(堆叠)的自动编码器组成,这些编码器使用经过训练的网络来表示具有预先定义的位深度的块(例如示例中的4位)。输入块和以训练网络为基础的表征之间的残差将使用相同的训练网络输入到下一阶段,这就是所谓的反复使用。每个步骤的相应系数都会进行编码。步骤越多,块表征所需的比特就越多,重构质量就越好。我们可以看到,在每个步骤中使用训练网络基的信号块是一种使用自适应变换基的分解。
与文献中已有的技术不同,我们利用“学习字典”和“神经网络”的优点,提出了一种新的有损视频编码框架。根据经典的“预测”加“变换”思想对视频压缩的成功历史,我们将任何输入的视频信号作为“预测”和“误差(残差)”样本的组合,即 f = fp + fr 。我们提出使用训练后的神经网络对其进行重构。给出这两部分,并将相应的系数编码到流中。在分别给定的相当远的数学信号分布下,将独立网络应用于“预测”和“残差”。标量量化用于编码系数,然后是最直接的哈夫曼熵编码。为了简单起见,我们在本文中应用了固定32×32块进行帧间和帧内编码的处理。只有一个参考帧用于时域预测。
与著名的H.264/AVC相比,我们的DeepCoder在使用视频编码标准化社区常用的测试序列进行测试时,显示出了相似的率失真效率,大约有1%的BD-Rate损失。这里,BD-Rate是使用SSIM[8]和比特率来测量的。总的来说,对于这种利用神经网络进行视频编码的初步探索,我们的DeepCoder显示出了潜力,我们相信随着未来的微调和精心的编码工具设计,编码效率将大大提高。
本论文的其他工作如下:第二节详细介绍了我们提出使用神经网络进行视频压缩的系统结构,并在第三节中进行了性能评估,最后在第四节中给出了总结性的意见。
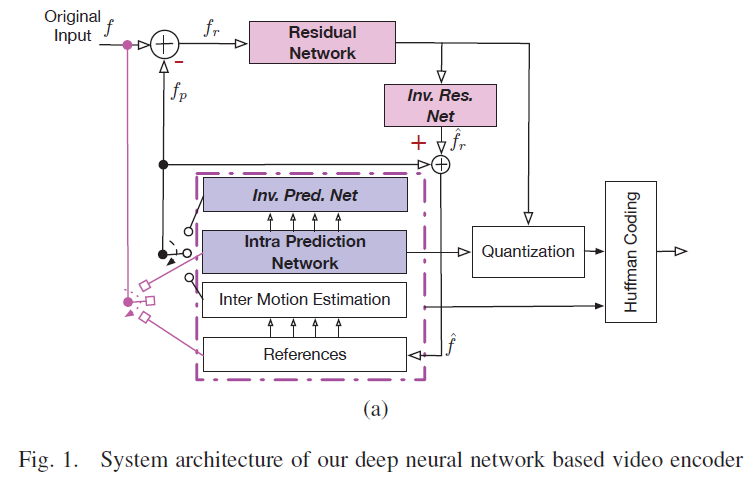
II. SYSTEM ARCHITECTURE OF NEURAL NETWORK BASED VIDEO COMPRESSION:
本节介绍我们的深度视频编码器的系统结构,如图1所示。利用帧内相关或帧间相关通过预测编码器形成图像块的紧凑表征预测,并利用帧间/帧内残差网络对残差进行压缩。预测系数和残差系数都经过量化和熵编码,生成最终的二进制流。如图1所示,整个编码系统包括预测、残差编码、量化和熵编码。本工作不考虑现有视频标准(如去块、SAO)中应用的滤波过程。在我们的系统中,三个卷积神经网络用于预测来自帧内信息的块,压缩帧间和帧内残差。残差共享相同的网络结构,但参数不同。
A. Predictive Encoder
预测是深度视频编码系统中最重要的模块。我们引入了帧内/帧间预测作为两种主要的预测方法来生成预测信号。在这个步骤中,当前帧的每个块都是从前一帧(即帧间预测)或帧内信息(即帧内预测)进行预测的。采用帧内/帧间选择法来选择更好的预测方法。
a) 帧内/帧间选择法:具体地说,输入视频的所有帧被分割成不重叠的32×32图像块,然后计算帧间预测块的均方误差(MSE)。如果均方误差小于某一常数阈值,则采用帧间预测,反之,如果均方误差大于阈值,则采用帧内预测。
b) 帧间预测以及运动估计:帧间预测通过使用来自前一帧的类似块来预测图像块。采用蛮力搜索策略对运动诱导的平移进行补偿,找到最佳匹配块。具体地说,我们对帧间预测的候选者应用一个移动的32×32窗口在前一帧的局部区域中选取块,通过选择最小均方误差的候选者中的一个来得到最佳匹配块。对于运动搜索范围,使用21×21搜索窗口来平衡性能和复杂性。
此外,我们还引入了另一种跳过模式,作为块MSE小于阈值时的一种特殊情况。跳跃模式已被证明对固定区域(如背景)非常有效。使用流中的二进制标志来推断此模式。对于每个标记为跳过模式的块,我们只流化其运动矢量并强制其残差为零。

c) 帧内预测网络:帧内预测试图利用图像块本身所包含的空间相关性来预测图像块。本文在深度学习的启发下,设计了一个帧内预测网络,并给出了其在视频编码任务中的应用前景。我们采用五层卷积网络作为编码器,如图2(a)所示。解码器与编码器是对称的对应物。对于H × W × 3的RGB图像,最终输出是尺寸为H/4 x W/4 x 4的特征图(fMap)。这个fMap被进一步量化并编码到流中。利用对称的解码器网络进行重构,得到预测信号(但存在量化噪声)。
B. Residual Encoder
经过预测,输入块由前一帧中的相似块或紧凑fMap表示。然而,这两种方法都会由于预测残差导致质量恶化。为了更好地重建视频,我们引入了残差编码来处理帧内预测和帧外预测的残差。为了简化问题,我们对两个残差使用图2(b)所示的相同网络结构,但可以使用不同的卷积权重。为了有效地捕获残差域中的特征,我们应用Inception结构[9]将两个并行卷积过程的输出结合起来。
C. Quantization and Entropy Coding
本文采用标量量化和哈夫曼熵编码方法,进一步压缩了帧内预测和残差的最终输出fMaps。
首先,我们将浮动系数缩放为8位整数。然后,我们通过直接将位深度从最高有效位(Msb)减少到最低有效位(Lsb)来应用最简单的量化,从而使得重构信号相对于率失真测量有8×(8+1)=72个组合(假设零残差)。选择产生最佳率失真(R-D)性能的一种。在这里,最好的R-D点位于R-D曲线的顶部。
量化后,使用哈夫曼码。根据量化后fMaps的直方图,推导出变长码表。短代码被分配给出现概率很高的符号,而长代码被用来表示很少出现的符号。类似的过程也被扩展到运动矢量编码。
D. Network Training
在这里,我们将详细介绍如何训练工作中使用的卷积神经网络。在实践中,我们使用AR-CNN[10]中提到的Twitter图像数据集进行培训。所有500个图像被分割成32x32的补丁,其中75%(660000个补丁)用作训练集,其余(165000个补丁)作为交叉验证集。由于本文所涉及的所有编码网络都有对应的解码网络,因此我们对编码器和解码器进行了成对的训练。将原始图像Xn作为输入,由CNN编码器进行压缩,并由相关的CNN解码器输出重构后的图像Yn。训练的目的是最小化以下损失函数:
 其中,Yn是重构图像,Xn是输入图像,N是批大小。
其中,Yn是重构图像,Xn是输入图像,N是批大小。
采用优化的自适应学习率算法(adadelta)[11]进行快速收敛,并首先在100个周期后生成预训练模型。为了避免局部最优,我们采用了另一种基于预训练模型的优化算法Adam(随机优化方法)[12],并在300个周期后得到最终的训练模型。所有参数设置与上述参考文件一致。
III. PERFORMANCE EVALUATION
本节将进行性能评估,以展示我们的DeepCoder。同时,我们还提供了与使用流行的x264[14]实现的著名H.264/AVC[13]的比较。我们使用默认的x264,但很少修改,以便与我们的DeepCoder进行公平比较。详情见表1。
选择视频编码标准化组使用的六个常用测试序列来验证我们提出的DeepCoder和x264的编码效率。如图3所示,这些视频涵盖了实践中的典型内容场景,包括更丰富的纹理场景,如BQSquare、BlowingBubbles、ParkScene和ParkScene;运动场景(可能带有摄像机平移),如RaceHorses;固定会议环境,如KristenAndSara。

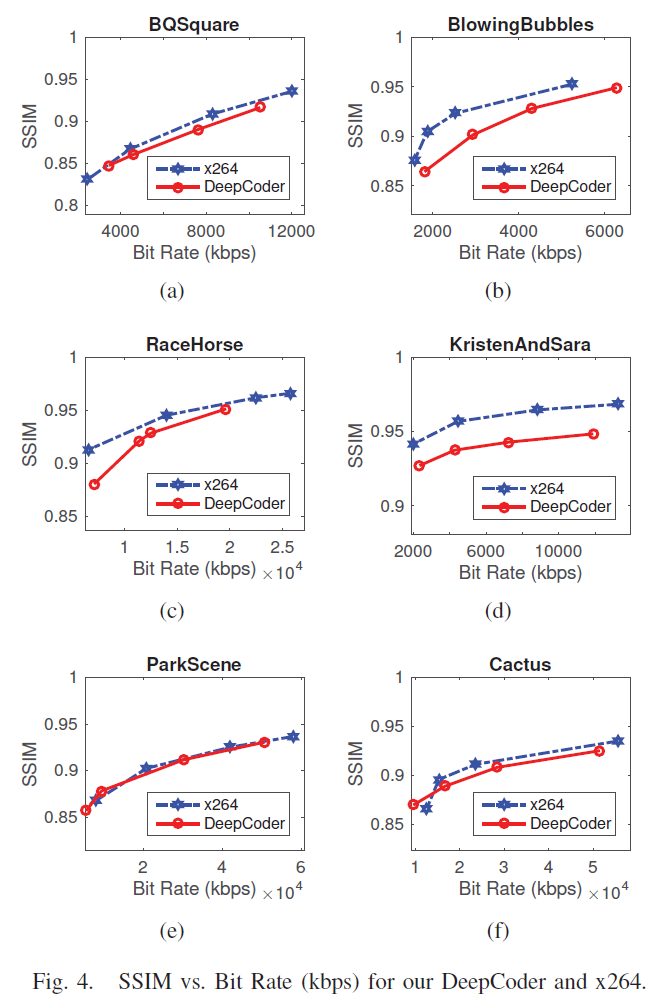
图4显示了我们的DeepCoder和基于x264的H.264/AVC获得的SSIM与比特率(kbps)的关系。使用[15]计算两条曲线之间的Bjontegaard Delta-Rate。注意,失真是由SSIM测量的,而不是传统的PSNR。如表2所示,我们的DeepCoder与众所周知的H.264/AVC相比,显示出相似的效率(平均BD-Rate损失小于2%)。
IV. CONCLUSION
本文提出了一种基于神经网络的视频编码框架DeepCoder。我们假设任何信号都可以通过它的预测和相应的残差来表示,两者都用指定的卷积神经网络来表示。对固定的32×32块进行操作。标量量化和哈夫曼码直接应用。与x264相比,我们的DeepCoder与视频编码协会使用的常见测试序列具有非常相似的编码效率(但损失很小),但它证明了基于深度神经网络的视频压缩是未来视频编码的替代方案的巨大潜力。

展望未来,我们可以探索几个潜在的途径来进一步改进我们的DeepCoder。例如,最近流行的生成对抗网络(GAN)或循环神经网络(RNN)也可以研究。运动补偿内插法[16]对传统视频编码的性能有了显著的改善。基于神经网络的插值是另一个有趣的研究方向。
REFERENCES
[1] G. J. Sullivan and T. Wiegand, “Video compression—from concepts to the H.264/AVC standard,” Proceedings of the IEEE, vol. 93, no. 1, pp. 18–31, 2005.
[2] P. Schmid-Saugeon and A. Zakhor, “Dictionary design for matching pursuit and application to motion-compensated video coding,” IEEE Trans. Circuits Syst. Video Technol., vol. 14, no. 6, pp. 880–886, 2004.
[3] J. Zepeda, C. Guillemot, and E. Kijak, “Image compression using sparse representations and the iteration-tuned and aligned dictionary,” IEEE J. Selected Topics in Signal Processing, vol. 5, no. 5, pp. 1061–1073, 2011.
[4] Y. Xue and Y. Wang, “Video coding using a self-adaptive redundant dictionary consisting of spatial and temporal prediction candidates,” in Proc. IEEE Int. Conf. Multimedia and Expo (ICME), 2014.
[5] A. Atreya and D. O’Shea, “Novel lossy compression algorithms with stacked autoencoders,” Stanford University CS229, Tech. Rep., 2009.
[6] G. Toderici, S. M. O’Malley, S.-J. Hwang, D. Vincent, D. Minnen, S. Baluja, M. Covell, and R. Sukthankar, “Variable rate image compression with recurrent neural networks,” CoRR, vol. abs/1511.06085, 2015. [Online]. Available: http://arxiv.org/abs/1511.06085
[7] G. Toderici, D. Vincent, N. Johnston, S.-J. Hwang, D. Minnen, J. Shor, and M. Covell, “Full resolution image compression with recurrent neural networks,” CoRR, vol. abs/1608.05148, 2016. [Online]. Available: http://arxiv.org/abs/1608.05148
[8] Z. Wang, A. C. Bovik, H. Sheikh, and E. P. Simoncelli, “Image quality assessment: from error visibility to structural similarity,” IEEE Trans. Image Processing, vol. 13, no. 4, pp. 600–612, April 2004.
[9] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich, “Going deeper with convolutions,” in Proc. of the IEEE CVPR, 2015, pp. 1–9.
[10] K. Yu, C. Dong, C. C. Loy, and X. Tang, “Deep convolution networks for compression artifacts reduction,” arXiv:1608.02778, Aug. 2016.
[11] M. D. Zeiler, “ADADELTA: An adaptive learning rate method,” arXiv:1212.5701v1, Dec. 2012.
[12] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv:1412.6980v9, Jan. 2017.
[13] T. Wiegand, G. J. Sullivan, G. Bjontegaard, and A. Luthra, “Overview of the H.264/AVC video coding standard,” IEEE Trans. Circuits Syst. Video Technol., vol. 13, no. 7, pp. 560–576, 2003.
[14] “x264,” http://www.videolan.org/developers/x264.html, 2016.
[15] G. Bjontegaard, “Calculation of average PSNR differences between R-D curves,” in Doc. VCEG-M33, ITU-T VCEG 13th Meeting, 2001.
[16] B. Girod, “Motion-compensating prediction with fractional pel accuracy,” IEEE Trans. Commun., vol. 41, no. 4, pp. 604–612, Apr. 1993.
DeepCoder: A Deep Neural Network Based Video Compression的更多相关文章
- 论文阅读笔记六十四: Architectures for deep neural network based acoustic models defined over windowed speech waveforms(INTERSPEECH 2015)
论文原址:https://pdfs.semanticscholar.org/eeb7/c037e6685923c76cafc0a14c5e4b00bcf475.pdf 摘要 本文研究了利用深度神经网络 ...
- 论文笔记——A Deep Neural Network Compression Pipeline: Pruning, Quantization, Huffman Encoding
论文<A Deep Neural Network Compression Pipeline: Pruning, Quantization, Huffman Encoding> Prunin ...
- A Survey of Model Compression and Acceleration for Deep Neural Network时s
A Survey of Model Compression and Acceleration for Deep Neural Network时s 本文全面概述了深度神经网络的压缩方法,主要可分为参数修 ...
- 深度神经网络如何看待你,论自拍What a Deep Neural Network thinks about your #selfie
Convolutional Neural Networks are great: they recognize things, places and people in your personal p ...
- 论文翻译:2022_PACDNN: A phase-aware composite deep neural network for speech enhancement
论文地址:PACDNN:一种用于语音增强的相位感知复合深度神经网络 引用格式:Hasannezhad M,Yu H,Zhu W P,et al. PACDNN: A phase-aware compo ...
- XiangBai——【AAAI2017】TextBoxes_A Fast Text Detector with a Single Deep Neural Network
XiangBai--[AAAI2017]TextBoxes:A Fast Text Detector with a Single Deep Neural Network 目录 作者和相关链接 方法概括 ...
- What are the advantages of ReLU over sigmoid function in deep neural network?
The state of the art of non-linearity is to use ReLU instead of sigmoid function in deep neural netw ...
- 论文笔记之:Decoupled Deep Neural Network for Semi-supervised Semantic Segmentation
Decoupled Deep Neural Network for Semi-supervised Semantic Segmentation xx
- Deep Learning: Assuming a deep neural network is properly regulated, can adding more layers actually make the performance degrade?
Deep Learning: Assuming a deep neural network is properly regulated, can adding more layers actually ...
随机推荐
- File类的基本概念与递归
一.File类 1.概念 File类:是文件和目录路径名的抽象表示形式. 即,Java中把文件或者目录(文件夹)都封装成File对象.也就是说如果我们要去操作硬盘上的文件,或者文件夹只要找到File这 ...
- Button基本用语
1.self.btn2 = Button(root,image = photo,command = self.login) 使用 image 图片作为按钮,command 作为响应 2.self.bt ...
- PHP chr() 函数
实例 从不同 ASCII 值返回字符: <?php高佣联盟 www.cgewang.comecho chr(52) . "<br>"; // Decimal va ...
- JDK1.8中HashMap的hash算法和寻址算法
JDK 1.8 中 HashMap 的 hash 算法和寻址算法 HashMap 源码 hash() 方法 static final int hash(Object key) { int h; ret ...
- day18.os模块 对系统进行操作
一.os操作 1.system()在python中执行系统命令 # os.system("ifconfig") # os.system("touch 1.txt" ...
- JDBC(3)-数据库事务
一.环境搭建(复习) 首先建立lib目录然后要把对应的jar包导进来 然后就是jdbc.properties文件 user=root password=123456 url=jdbc:mysql:// ...
- 10分钟 Castle.Windsor 适配 Asp.Net Core 3.0
Asp.Net Core 3.0以上,不再能通过修改Starup.ConfigureServices返回值(IServiceProvider),所以只能调用IHostBuilder.UseServic ...
- 【AHOI2009】同类分布 题解(数位DP)
题目大意:求$[l,r]$中各位数之和能被该数整除的数的个数.$0\leq l\leq r\leq 10^{18}$. ------------------------ 显然数位DP. 搜索时记录$p ...
- 解决 IntelliJ IDEA占用C盘过大空间问题
原文地址:https://blog.csdn.net/weixin_44449518/article/details/103334235 问题描述: 在保证其他软件缓存不影响C盘可用空间的基础上,当我 ...
- 趣讲 PowerJob 超强大的调度层,开始表演真正的技术了
本文适合有 Java 基础知识的人群 作者:HelloGitHub-Salieri HelloGitHub 推出的<讲解开源项目>系列. 写在前面的碎碎念:终于到了万众期待的调度层原理了. ...