第2章 RDD编程(2.1-2.2)
第2章 RDD编程
2.1 编程模型
在Spark中,RDD被表示为对象,通过对象上的方法调用来对RDD进行转换。经过一系列的transformations定义RDD之后,就可以调用actions触发RDD的计算,action可以是向应用程序返回结果(count, collect等),或者是向存储系统保存数据(saveAsTextFile等)。在Spark中,只有遇到action,才会执行RDD的计算(即延迟计算),这样在运行时可以通过管道的方式传输多个转换。
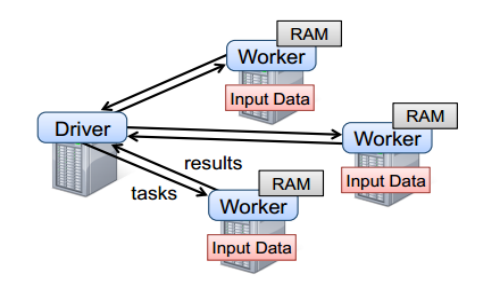
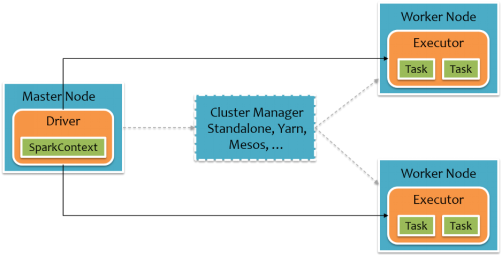
要使用Spark,开发者需要编写一个Driver程序,它被提交到集群以调度运行Worker,如下图所示。Driver中定义了一个或多个RDD,并调用RDD上的action,Worker则执行RDD分区计算任务。
2.2 RDD创建
在Spark中创建RDD的创建方式大概可以分为三种:从集合中创建RDD;从外部存储创建RDD;从其他RDD创建。
由一个已经存在的Scala集合创建,集合并行化。
val rdd1 = sc.parallelize(Array(1,2,3,4,5,6,7,8))
而从集合中创建RDD,Spark主要提供了两种函数:parallelize和makeRDD。我们可以先看看这两个函数的声明:
def parallelize[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T]
def makeRDD[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T]
def makeRDD[T: ClassTag](seq: Seq[(T, Seq[String])]): RDD[T]
我们可以从上面看出makeRDD有两种实现,而且第一个makeRDD函数接收的参数和parallelize完全一致。其实第一种makeRDD函数实现是依赖了parallelize函数的实现,来看看Spark中是怎么实现这个makeRDD函数的:
def makeRDD[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope {
parallelize(seq, numSlices)
}
我们可以看出,这个makeRDD函数完全和parallelize函数一致。但是我们得看看第二种makeRDD函数函数实现了,它接收的参数类型是Seq[(T, Seq[String])],Spark文档的说明是:
Distribute a local Scala collection to form an RDD, with one or more location preferences (hostnames of Spark nodes) for each object. Create a new partition for each collection item.
原来,这个函数还为数据提供了位置信息,来看看我们怎么使用:
scala> val guigu1= sc.parallelize(List(1,2,3))
guigu1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[10] at parallelize at <console>:21
scala> val guigu2 = sc.makeRDD(List(1,2,3))
guigu2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[11] at makeRDD at <console>:21
scala> val seq = List((1, List("slave01")),| (2, List("slave02")))
seq: List[(Int, List[String])] = List((1,List(slave01)),
(2,List(slave02)))
scala> val guigu3 = sc.makeRDD(seq)
guigu3: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[12] at makeRDD at <console>:23
scala> guigu3.preferredLocations(guigu3.partitions(1))
res26: Seq[String] = List(slave02)
scala> guigu3.preferredLocations(guigu3.partitions(0))
res27: Seq[String] = List(slave01)
scala> guigu1.preferredLocations(guigu1.partitions(0))
res28: Seq[String] = List()
我们可以看到,makeRDD函数有两种实现,第一种实现其实完全和parallelize一致;而第二种实现可以为数据提供位置信息,而除此之外的实现和parallelize函数也是一致的,如下:
def parallelize[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope {
assertNotStopped()
new ParallelCollectionRDD[T](this, seq, numSlices, Map[Int, Seq[String]]())
}
def makeRDD[T: ClassTag](seq: Seq[(T, Seq[String])]): RDD[T] = withScope {
assertNotStopped()
val indexToPrefs = seq.zipWithIndex.map(t => (t._2, t._1._2)).toMap
new ParallelCollectionRDD[T](this, seq.map(_._1), seq.size, indexToPrefs)
}
都是返回ParallelCollectionRDD,而且这个makeRDD的实现不可以自己指定分区的数量,而是固定为seq参数的size大小。
由外部存储系统的数据集创建,包括本地的文件系统,还有所有Hadoop支持的数据集,比如HDFS、Cassandra、HBase等
scala> val atguigu = sc.textFile("hdfs://hadoop102:9000/RELEASE")
atguigu: org.apache.spark.rdd.RDD[String] = hdfs:// hadoop102:9000/RELEASE MapPartitionsRDD[4] at textFile at <console>:24
第2章 RDD编程(2.1-2.2)的更多相关文章
- 第2章 RDD编程(2.3)
第2章 RDD编程(2.3) 2.3 TransFormation 基本RDD Pair类型RDD (伪集合操作 交.并.补.笛卡尔积都支持) 2.3.1 map(func) 返回一个新的RDD,该 ...
- Learning Spark中文版--第三章--RDD编程(2)
Common Transformations and Actions 本章中,我们浏览了Spark中大多数常见的transformation(转换)和action(开工).在包含特定数据类型的RD ...
- Learning Spark中文版--第三章--RDD编程(1)
本章介绍了Spark用于数据处理的核心抽象概念,具有弹性的分布式数据集(RDD).一个RDD仅仅是一个分布式的元素集合.在Spark中,所有工作都表示为创建新的RDDs.转换现有的RDD,或者调 ...
- 《Spark快速大数据分析》—— 第三章 RDD编程
- Spark学习笔记2:RDD编程
通过一个简单的单词计数的例子来开始介绍RDD编程. import org.apache.spark.{SparkConf, SparkContext} object word { def main(a ...
- 2. RDD编程
2.1 编程模型 在Spark中,RDD被表示为对象,通过对象上的方法调用来对RDD进行转换.经过一系列的transformations定义RDD之后,就可以调用actions触发RDD的计算,act ...
- 《深入浅出Node.js》第7章 网络编程
@by Ruth92(转载请注明出处) 第7章 网络编程 Node 只需要几行代码即可构建服务器,无需额外的容器. Node 提供了以下4个模块(适用于服务器端和客户端): net -> TCP ...
- 《深入浅出Node.js》第4章 异步编程
@by Ruth92(转载请注明出处) 第4章 异步编程 Node 能够迅速成功并流行起来的原因: V8 和 异步 I/O 在性能上带来的提升: 前后端 JavaScript 编程风格一致 一.函数式 ...
- Spark菜鸟学习营Day3 RDD编程进阶
Spark菜鸟学习营Day3 RDD编程进阶 RDD代码简化 对于昨天练习的代码,我们可以从几个方面来简化: 使用fluent风格写法,可以减少对于中间变量的定义. 使用lambda表示式来替换对象写 ...
随机推荐
- 跟老刘学运维day02~部署虚拟环境安装Linux系统(1)
第1章 部署虚拟环境安装Linux系统 所谓“工欲善其事,必先利其器” 1.准备工具 VmwareWorkStation 15.5——虚拟机软件(必需) RedHatEnterpriseLinux ...
- 数字转字符串&&字符串转数字
一开始写错了呜呜呜 先是<< 再是>>
- 学习JavaScript数据结构与算法 2/15
第一章 JavaScript简介 js不同于C/C++,C#,JAVA,不是强类型语言. 通常,代码质量可以用全局变量和函数的数量来考量(数量越多越糟).因此,尽可能避免使用全局变量. JS数据类型 ...
- html中input提示文字样式修改
在很多网站上我们都看到input输入框显示提示文字,让我们一起来看看如果在input输入框中显示提示文字.我们只需要在<input>标签里添加:placeholder="提示文字 ...
- pandas属性和方法
Series对象的常用属性和方法 loc[ ]和iloc[ ]格式示例表 Pandas提供的数据整理方法 Pandas分组对象的属性和方法 date_range函数的常用freq参数表
- PHP decbin() 函数
实例 把十进制转换为二进制: <?phpecho decbin("3") . "<br>";echo decbin("1" ...
- Promise核心基础
基础 Promise 抽象表达:是js中进行异步编程的新的解决方案 具体解释:1.从语法上来说是一个构造函数 2.从功能上来说promise对象用来封装一个异步操作并可以获取其结果 状态改变:0.ne ...
- 小波变换检测信号突变点的MATLAB实现
之前在不经意间也有接触过求突变点的问题.在我看来,与其说是求突变点,不如说是我们常常玩的"找不同".给你两幅图像,让你找出两个图像中不同的地方,我认为这其实也是找突变点在生活中的应 ...
- 【Python 实例】面向对象 | 请输入一周中某天的名称的第一个字母来判断以下是星期几,如果第一个字母一样则继续判断第二个字母
[Python 实例]面向对象 | 请输入一周中某天的名称的第一个字母来判断以下是星期几,如果第一个字母一样则继续判断第二个字母 题目: 解答: 运行结果: 题目: 请输入一周中某天的名称的第一个字母 ...
- Android监听器无法跳转的可能原因之一。。。
主菜前的厨师前言: 各位大牛,牛崽崽,这是本牛崽第一次写博客,牛崽崽我初出茅庐,但是我会很用心的写自己的每一份随笔,写的不好的大家见谅. 今天就来说说本牛崽在实现监听器时遇到的问题: 本牛崽因为也是刚 ...