音频数据增强及python实现
博客作者:凌逆战
博客地址:https://www.cnblogs.com/LXP-Never/p/13404523.html
音频时域波形具有以下特征:音调,响度,质量。我们在进行数据增强时,最好只做一些小改动,使得增强数据和源数据存在较小差异即可,切记不能改变原有数据的结构,不然将产生“脏数据”,通过对音频数据进行数据增强,能有助于我们的模型避免过度拟合并变得更加通用。
我发现对声波的以下改变是有用的:Noise addition(增加噪音)、增加混响、Time shifting(时移)、Pitch shifting(改变音调)和Time stretching(时间拉伸)。
本章需要使用的python库:
- matplotlib:绘制图像
- librosa:音频数据处理
- numpy:矩阵数据处理
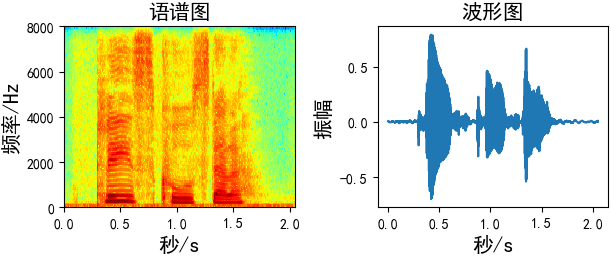
使用先画出原始语音数据的语谱图和波形图
import librosa
import numpy as np
import matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示符号
fs = 16000 wav_data, _ = librosa.load("./p225_001.wav", sr=fs, mono=True) # ########### 画图
plt.subplot(2, 2, 1)
plt.title("语谱图", fontsize=15)
plt.specgram(wav_data, Fs=16000, scale_by_freq=True, sides='default', cmap="jet")
plt.xlabel('秒/s', fontsize=15)
plt.ylabel('频率/Hz', fontsize=15) plt.subplot(2, 2, 2)
plt.title("波形图", fontsize=15)
time = np.arange(0, len(wav_data)) * (1.0 / fs)
plt.plot(time, wav_data)
plt.xlabel('秒/s', fontsize=15)
plt.ylabel('振幅', fontsize=15) plt.tight_layout()
plt.show()
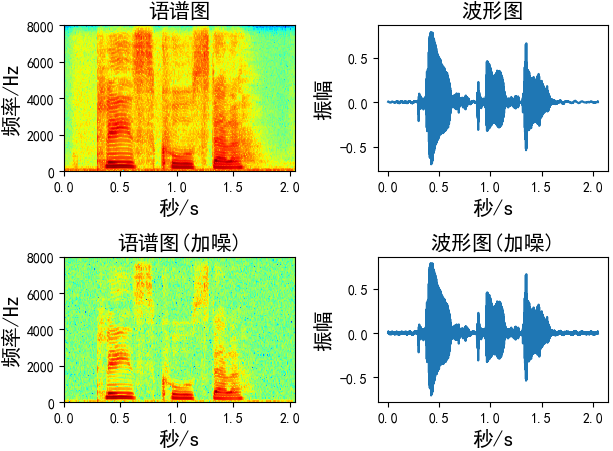
加噪
添加的噪声为均值为0,标准差为1的高斯白噪声,有两种方法对数据进行加噪
第一种:控制噪声因子
def add_noise1(x, w=0.004):
# w:噪声因子
output = x + w * np.random.normal(loc=0, scale=1, size=len(x))
return output Augmentation = add_noise1(x=wav_data, w=0.004)
第二种:控制信噪比
通过信噪比的公式推导出噪声。
$$SNR=10*log_{10}(\frac{S^2}{N^2})$$
$$N=\sqrt{\frac{S^2}{10^{\frac{SNR}{10}}}}$$
def add_noise2(x, snr):
# snr:生成的语音信噪比
P_signal = np.sum(abs(x) ** 2) / len(x) # 信号功率
P_noise = P_signal / 10 ** (snr / 10.0) # 噪声功率
return x + np.random.randn(len(x)) * np.sqrt(P_noise) Augmentation = add_noise2(x=wav_data, snr=50)

波形位移
语音波形移动使用numpy.roll函数向右移动shift距离
numpy.roll(a, shift, axis=None)
参数:
- a:数组
- shift:滚动的长度
- axis:滚动的维度。0为垂直滚动,1为水平滚动,参数为None时,会先将数组扁平化,进行滚动操作后,恢复原始形状
x = np.arange(10)
# array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) print(np.roll(x, 2))
# array([8, 9, 0, 1, 2, 3, 4, 5, 6, 7])
波形位移函数:
def time_shift(x, shift):
# shift:移动的长度
return np.roll(x, int(shift)) Augmentation = time_shift(wav_data, shift=fs//2)

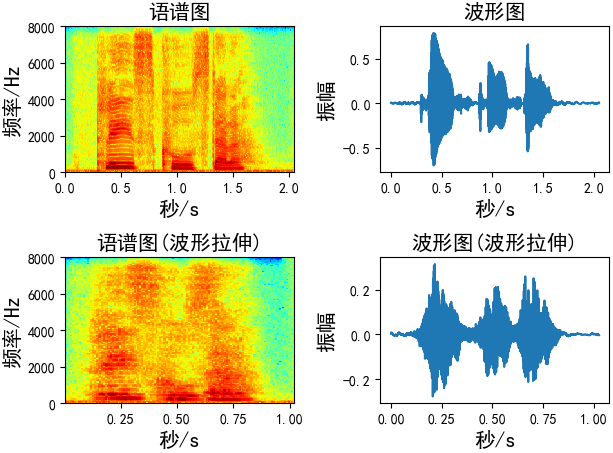
波形拉伸
在不影响音高的情况下改变声音的速度 / 持续时间。这可以使用librosa的time_stretch函数来实现。
def time_stretch(x, rate):
# rate:拉伸的尺寸,
# rate > 1 加快速度
# rate < 1 放慢速度
return librosa.effects.time_stretch(x, rate) Augmentation = time_stretch(wav_data, rate=2)
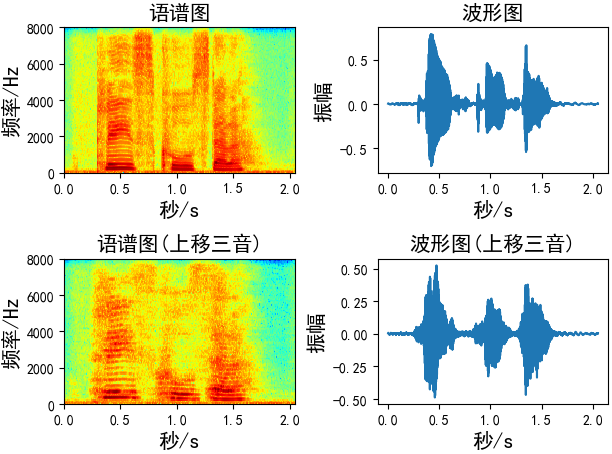
音高修正(Pitch Shifting)
音高修正只改变音高而不影响音速,我发现-5到5之间的步数更合适
def pitch_shifting(x, sr, n_steps, bins_per_octave=12):
# sr: 音频采样率
# n_steps: 要移动多少步
# bins_per_octave: 每个八度音阶(半音)多少步
return librosa.effects.pitch_shift(x, sr, n_steps, bins_per_octave=bins_per_octave) # 向上移三音(如果bins_per_octave为12,则六步)
Augmentation = pitch_shifting(wav_data, sr=fs, n_steps=6, bins_per_octave=12)
# 向上移三音(如果bins_per_octave为24,则3步)
Augmentation = pitch_shifting(wav_data, sr=fs, n_steps=3, bins_per_octave=24)
# 向下移三音(如果bins_per_octave为12,则六步)
Augmentation = pitch_shifting(wav_data, sr=fs, n_steps=-6, bins_per_octave=12)
音频数据增强及python实现的更多相关文章
- Python库 - Albumentations 图片数据增强库
Python图像处理库 - Albumentations,可用于深度学习中网络训练时的图片数据增强. Albumentations 图像数据增强库特点: 基于高度优化的 OpenCV 库实现图像快速数 ...
- Python爬虫音频数据
一:前言 本次爬取的是喜马拉雅的热门栏目下全部电台的每个频道的信息和频道中的每个音频数据的各种信息,然后把爬取的数据保存到mongodb以备后续使用.这次数据量在70万左右.音频数据包括音频下载地址, ...
- 【Tool】Augmentor和imgaug——python图像数据增强库
Augmentor和imgaug--python图像数据增强库 Tags: ComputerVision Python 介绍两个图像增强库:Augmentor和imgaug,Augmentor使用比较 ...
- Python爬虫实战案例:取喜马拉雅音频数据详解
前言 喜马拉雅是专业的音频分享平台,汇集了有声小说,有声读物,有声书,FM电台,儿童睡前故事,相声小品,鬼故事等数亿条音频,我最喜欢听民间故事和德云社相声集,你呢? 今天带大家爬取喜马拉雅音频数据,一 ...
- Python爬虫:爬取喜马拉雅音频数据详解
前言 喜马拉雅是专业的音频分享平台,汇集了有声小说,有声读物,有声书,FM电台,儿童睡前故事,相声小品,鬼故事等数亿条音频,我最喜欢听民间故事和德云社相声集,你呢? 今天带大家爬取喜马拉雅音频数据,一 ...
- python将xml文件数据增强(labelimg)
在处理faster-rcnn和yolo时笔者使用labelimg标注图片 但是我们只截取了大概800张左右的图,这个量级在训练时肯定是不够的,所以我们需要使用数据增强(无非是旋转加噪调量度)来增加我们 ...
- 数据增强利器--Augmentor
最近遇到数据样本数目不足的问题,自己写的增强工具生成数目还是不够,终于在网上找到一个数据增强工具包,足够高级,足够傻瓜.想要多少就有多少!再也不怕数据不够了! 简介 Augmentor是一个Pytho ...
- Win10下数据增强及标注工具安装
Win10下数据增强及标注工具安装 一. 数据增强利器—Augmentor 1.安装 只需在控制台输入:pip install Augmentor 2.简介 Augmentor是用于图像增强的软件 ...
- YoloV4当中的Mosaic数据增强方法(附代码详细讲解)码农的后花园
上一期中讲解了图像分类和目标检测中的数据增强的区别和联系,这期讲解数据增强的进阶版- yolov4中的Mosaic数据增强方法以及CutMix. 前言 Yolov4的mosaic数据增强参考了CutM ...
随机推荐
- go语言之文件操作
一: 相关的API 1func Create(name string) (file *File, err Error) 根据提供的文件名创建新的文件,返回一个文件对象,默认权限是0666 2 func ...
- android 数据绑定(6)自定义绑定方法、双向数据绑定
1.官方文档 https://developer.android.com/topic/libraries/data-binding/binding-adapters https://developer ...
- 关于action的使用在firefox报错的问题
现在的网站有很多都是鼠标移到上面去才会显示出相应的一些标签之类的东西,然后再进行操作,但是因为要操作的元素一开始是隐藏的,就没办法直接定位,只能调用action来模拟鼠标悬停操作,也就是下面这句代码: ...
- C III
http://cossacksworld.ucoz.co.uk/load/c_iii_files/79 http://cossacksworld.ucoz.co.uk/load/c_iii_files ...
- 蒲公英 · JELLY技术周刊 Vol.21 -- 技术周刊 · React Hooks vs Vue 3 + Composition API
蒲公英 · JELLY技术周刊 Vol.21 选 React 还是 Vue,每个人心中都会有自己的答案,有很多理由去 pick 心水的框架,但是当我们扪心自问,我们真的可以公正的来评价这两者之间的差异 ...
- 【CF】Sereja and Arcs
#include <bits/stdc++.h> #define llong long long using namespace std; const int N = 1e5; const ...
- mybatis-spring-boot-starter 1.3.0 操作实体类的SpringBoot例子
例程下载:https://files.cnblogs.com/files/xiandedanteng/gatling20200428-02.zip 需求:使用mybatis实现对hy_emp表的CRU ...
- mysql InnoDB引擎是否支持hash索引
看一下mysql官方文档:https://dev.mysql.com/doc/refman/5.7/en/create-index.html , 从上面的图中可以得知,mysql 是支持hash索引的 ...
- IDAPython 安装和设置(windows+linux)
安装步骤: 我采用的是IDA 6.8 windows安装: 机器上安装了Python,到Python的官网—http://www.python.org/getit/下载2.7的安装包.注意对应操作系统 ...
- 企业邮箱选择,商务办公为什么选TOM企业邮箱?
企业邮箱是工作中的重要工具,它可以帮助我们更规范的上传下达.更高效的管理工作,也是拓展合作伙伴的敲门砖及必杀技.比如写一封诚意满满的合作邀请,再比如重要关头写一封合作协议.毫不夸张,企业邮箱不仅能节省 ...