Python爬虫实战案例:取喜马拉雅音频数据详解
前言
喜马拉雅是专业的音频分享平台,汇集了有声小说,有声读物,有声书,FM电台,儿童睡前故事,相声小品,鬼故事等数亿条音频,我最喜欢听民间故事和德云社相声集,你呢?
今天带大家爬取喜马拉雅音频数据,一起期待吧!!
这个案例的视频地址在这里
https://v.douyu.com/show/a2JEMJj3e3mMNxml
项目目标
爬取喜马拉雅音频数据
受害者地址
https://www.ximalaya.com/
本文知识点:
- 1、系统分析网页性质
- 2、多层数据解析
- 3、海量音频数据保存
环境:
- python 3.6
- pycharm
- requests
- parsel
思路:(爬虫案例)
- 1.确定数据所在的链接地址(url)
- 2.通过代码发送url地址的请求
- 3.解析数据(要的, 筛选不要的)
- 4.数据持久化(保存)
案例思路:
- 1. 在静态数据中获取音频的id值
- 2. 发送指定id值json数据请求(src)
- 3. 从json数据中解析音频所对应的URL地址
开始写代码
先导入所需的模块
import requests
import parsel # 数据解析模块
import re
1.确定数据所在的链接地址(url) 逆向分析 网页性质(静态网页/动态网页)
打开开发者工具,播放一个音频,在Madie里面可以找到一个数据包
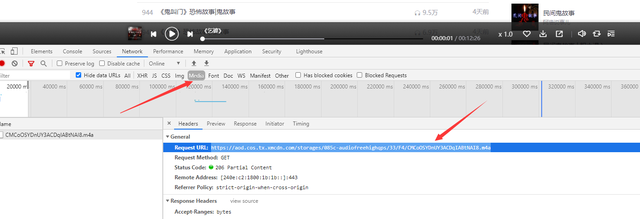
复制URL,搜索
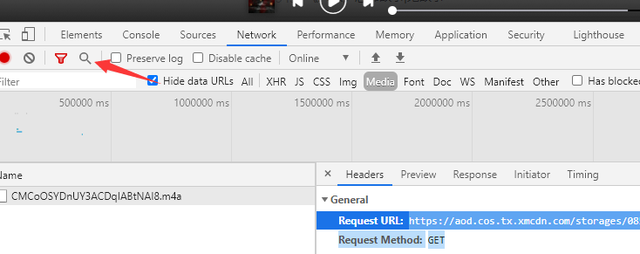
找到ID值

继续搜索,找到请求头参数

url = 'https://www.ximalaya.com/youshengshu/4256765/p{}/'.format(page)
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}
2.通过代码发送url地址的请求
response = requests.get(url=url, headers=headers)
html_data = response.text
3.解析数据(要的, 筛选不要的) 解析音频的 id值
selector = parsel.Selector(html_data)
lis = selector.xpath('//div[@class="sound-list _is"]/ul/li') for li in lis:
try:
title = li.xpath('.//a/@title').get() + '.m4a'
href = li.xpath('.//a/@href').get()
# print(title, href) m4a_id = href.split('/')[-1]
# print(href, m4a_id) # 发送指定id值json数据请求(src)
json_url = 'https://www.ximalaya.com/revision/play/v1/audio?id={}&ptype=1'.format(m4a_id)
json_data = requests.get(url=json_url, headers=headers).json()
# print(json_data) # 提取音频地址
m4a_url = json_data['data']['src']
# print(m4a_url) # 请求音频数据
m4a_data = requests.get(url=m4a_url, headers=headers).content new_title = change_title(title)
4.数据持久化(保存)
with open('video\\' + new_title, mode='wb') as f:
f.write(m4a_data)
print('保存完成:', title)
最后还要处理文件名非法字符
def change_title(title):
pattern = re.compile(r"[\/\\\:\*\?\"\<\>\|]") # '/ \ : * ? " < > |'
new_title = re.sub(pattern, "_", title) # 替换为下划线
return new_title
完整代码
import re import requests
import parsel # 数据解析模块 def change_title(title):
"""处理文件名非法字符的方法"""
pattern = re.compile(r"[\/\\\:\*\?\"\<\>\|]") # '/ \ : * ? " < > |'
new_title = re.sub(pattern, "_", title) # 替换为下划线
return new_title for page in range(13, 33):
print('---------------正在爬取第{}页的数据----------------'.format(page))
# 1.确定数据所在的链接地址(url) 逆向分析 网页性质(静态网页/动态网页)
url = 'https://www.ximalaya.com/youshengshu/4256765/p{}/'.format(page)
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'} # 2.通过代码发送url地址的请求
response = requests.get(url=url, headers=headers)
html_data = response.text
# print(html_data) # 3.解析数据(要的, 筛选不要的) 解析音频的 id值
selector = parsel.Selector(html_data)
lis = selector.xpath('//div[@class="sound-list _is"]/ul/li') for li in lis:
try:
title = li.xpath('.//a/@title').get() + '.m4a'
href = li.xpath('.//a/@href').get()
# print(title, href) m4a_id = href.split('/')[-1]
# print(href, m4a_id) # 发送指定id值json数据请求(src)
json_url = 'https://www.ximalaya.com/revision/play/v1/audio?id={}&ptype=1'.format(m4a_id)
json_data = requests.get(url=json_url, headers=headers).json()
# print(json_data) # 提取音频地址
m4a_url = json_data['data']['src']
# print(m4a_url) # 请求音频数据
m4a_data = requests.get(url=m4a_url, headers=headers).content new_title = change_title(title)
# print(new_title) # 4.数据持久化(保存)
with open('video\\' + new_title, mode='wb') as f:
f.write(m4a_data)
print('保存完成:', title)
except:
pass
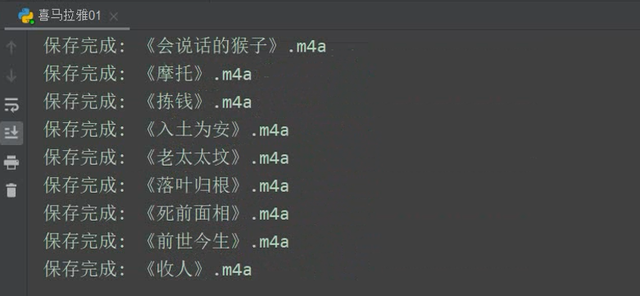
运行代码,效果如下图
Python爬虫实战案例:取喜马拉雅音频数据详解的更多相关文章
- Python爬虫:爬取喜马拉雅音频数据详解
前言 喜马拉雅是专业的音频分享平台,汇集了有声小说,有声读物,有声书,FM电台,儿童睡前故事,相声小品,鬼故事等数亿条音频,我最喜欢听民间故事和德云社相声集,你呢? 今天带大家爬取喜马拉雅音频数据,一 ...
- Python爬虫之爬取淘女郎照片示例详解
这篇文章主要介绍了Python爬虫之爬取淘女郎照片示例详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧 本篇目标 抓取淘宝MM ...
- python爬虫实战---爬取大众点评评论
python爬虫实战—爬取大众点评评论(加密字体) 1.首先打开一个店铺找到评论 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经 ...
- Python爬虫实战---抓取图书馆借阅信息
Python爬虫实战---抓取图书馆借阅信息 原创作品,引用请表明出处:Python爬虫实战---抓取图书馆借阅信息 前段时间在图书馆借了很多书,借得多了就容易忘记每本书的应还日期,老是担心自己会违约 ...
- python爬虫25 | 爬取下来的数据怎么保存? CSV 了解一下
大家好 我是小帅b 是一个练习时长两年半的练习生 喜欢 唱! 跳! rap! 篮球! 敲代码! 装逼! 不好意思 我又走错片场了 接下来的几篇文章 小帅b将告诉你 如何将你爬取到的数据保存下来 有文本 ...
- Python爬虫之抓取豆瓣影评数据
脚本功能: 1.访问豆瓣最受欢迎影评页面(http://movie.douban.com/review/best/?start=0),抓取所有影评数据中的标题.作者.影片以及影评信息 2.将抓取的信息 ...
- Python爬虫实战案例:爬取爱奇艺VIP视频
一.实战背景 爱奇艺的VIP视频只有会员能看,普通用户只能看前6分钟.比如加勒比海盗5的URL:http://www.iqiyi.com/v_19rr7qhfg0.html#vfrm=19-9-0-1 ...
- Python爬虫学习==>第八章:Requests库详解
学习目的: request库比urllib库使用更加简洁,且更方便. 正式步骤 Step1:什么是requests requests是用Python语言编写,基于urllib,采用Apache2 Li ...
- Python爬虫入门:Urllib parse库使用详解(二)
文字转载:https://www.jianshu.com/p/e4a9e64082ef,转载内容仅供学习 如有侵权,请联系删除 获取url参数 urlparse 和 parse_qs ParseRes ...
随机推荐
- C# 中的 ref 已经被放开,或许你已经不认识了
一:背景 1. 讲故事 最近在翻 netcore 源码看,发现框架中有不少的代码都被 ref 给修饰了,我去,这还是我认识的 ref 吗?就拿 Span 来说,代码如下: public readonl ...
- Zookeeper(4)---ZK集群部署和选举
一.集群部署 1.准备三台机器,安装好ZK.强烈建议奇数台机器,因为zookeeper 通过判断大多数节点的存活来判断整个服务是否可用.3个节点,挂掉了2个表示整个集群挂掉,而用偶数4个,挂掉了2个也 ...
- 最全总结 | 聊聊 Python 办公自动化之 Word(上)
1. 前言 日常自动化办公中,使用 Python 真的能做到事半功倍! 在上一个系列中,我们对 Python 操作 Excel 进行了一次全面总结 最全总结 | 聊聊 Python 办公自动化之 Ex ...
- php curl 请求封装
/** * curl 封装函数 * @param string $url 请求地址 * @param string $data 请求数据 * @param string $type 请求方式 默认为G ...
- Linux下Flask环境
一,安装python3.6.4 wget http://www.python.org/ftp/python/3.6.4/Python-3.6.4.tgz tar -xvzf Python-3.6.4. ...
- <摘自>飞:jxl简析2 [ http://www.emlog.net/fei ]
[<摘自>飞:jxl简析:http://www.emlog.net/fei] (二)应用 在进行实践前 , 我们需要对 excel 有一个大致的了解 ,excel 文件由一个工作簿 (Wo ...
- netfilter 的扩展功能
目前内核已经有filter 功能,但是往往实际运用中需要用到一些定制的filter 功能, 所以这个时候仅仅依靠现有的不能完成,于是就出现了conntrack的扩展功能, 最直接的就是tftp he ...
- 链路层输出 -qdisc
二层发送中,实现qdisc的主要函数是__dev_xmit_skb和net_tx_action,本篇将分析qdisc实现的原理,仅对框架进行分析. 其框架如下图所示 qdisc初始化 pktsched ...
- Python_图解教程
说明:本教程用图片+源码讲解Python常见的问题,共勉! 1.Python包的调用 # coding:utf8 # from pakge.mymodel import test from bao ...
- Qt For MacOs环境搭建
使用VMWARE关于macos镜像搭建,参考https://blog.csdn.net/u011415782/article/details/78505422 关于darwin8.5.5 来安装vmt ...