Turbo Boyer-Moore algorithm
MySQL :: MySQL 8.0 Reference Manual :: 8.3.9 Comparison of B-Tree and Hash Indexes https://dev.mysql.com/doc/refman/8.0/en/index-btree-hash.html
If you use ... LIKE '% and string%'string is longer than three characters, MySQL uses the Turbo Boyer-Moore algorithm to initialize the pattern for the string and then uses this pattern to perform the search more quickly.
Turbo-BM algorithm http://igm.univ-mlv.fr/~lecroq/string/node15.html
Boyer-Moore algorithm http://igm.univ-mlv.fr/~lecroq/string/node14.html#SECTION00140
Boyer-Moore algorithm
- performs the comparisons from right to left;
- preprocessing phase in O(m+
 ) time and space complexity;
) time and space complexity; - searching phase in O(mn) time complexity;
- 3n text character comparisons in the worst case when searching for a non periodic pattern;
- O(n / m) best performance.
The Boyer-Moore algorithm is considered as the most efficient string-matching algorithm in usual applications. A simplified version of it or the entire algorithm is often implemented in text editors for the «search» and «substitute» commands.
The algorithm scans the characters of the pattern from right to left beginning with the rightmost one. In case of a mismatch (or a complete match of the whole pattern) it uses two precomputed functions to shift the window to the right. These two shift functions are called the good-suffix shift (also called matching shift and the bad-character shift (also called the occurrence shift).
Assume that a mismatch occurs between the character x[i]=a of the pattern and the character y[i+j]=b of the text during an attempt at position j.
Then, x[i+1 .. m-1]=y[i+j+1 .. j+m-1]=u and x[i]  y[i+j]. The good-suffix shift consists in aligning the segment y[i+j+1 .. j+m-1]=x[i+1 .. m-1] with its rightmost occurrence in x that is preceded by a character different from x[i](see figure 13.1).
y[i+j]. The good-suffix shift consists in aligning the segment y[i+j+1 .. j+m-1]=x[i+1 .. m-1] with its rightmost occurrence in x that is preceded by a character different from x[i](see figure 13.1).

Figure 13.1. The good-suffix shift, u re-occurs preceded by a character c different from a.
If there exists no such segment, the shift consists in aligning the longest suffix v of y[i+j+1 .. j+m-1] with a matching prefix of x (see figure 13.2).

Figure 13.2. The good-suffix shift, only a suffix of u re-occurs in x.
The bad-character shift consists in aligning the text character y[i+j] with its rightmost occurrence in x[0 .. m-2]. (see figure 13.3)

Figure 13.3. The bad-character shift, a occurs in x.
If y[i+j] does not occur in the pattern x, no occurrence of x in y can include y[i+j], and the left end of the window is aligned with the character immediately after y[i+j], namely y[i+j+1] (see figure 13.4).

Figure 13.4. The bad-character shift, b does not occur in x.
Note that the bad-character shift can be negative, thus for shifting the window, the Boyer-Moore algorithm applies the maximum between the the good-suffix shift and bad-character shift. More formally the two shift functions are defined as follows.
The good-suffix shift function is stored in a table bmGs of size m+1.
- Let us define two conditions:
-

Cs(i, s): for each k such that i < k < m, s 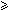 k or x[k-s]=x[k] and
k or x[k-s]=x[k] and -
Co(i, s): if s <i then x[i-s] x[i]
Then, for 0 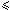 i < m: bmGs[i+1]=min{s>0 : Cs(i, s) and Co(i, s) hold}
i < m: bmGs[i+1]=min{s>0 : Cs(i, s) and Co(i, s) hold}
and we define bmGs[0] as the length of the period of x. The computation of the table bmGs use a table suff defined as follows: for 1 i < m, suff[i]=max{k : x[i-k+1 .. i]=x[m-k .. m-1]}
The bad-character shift function is stored in a table bmBc of size . For c in 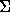 : bmBc[c] = min{i : 1 i <m-1 and x[m-1-i]=c} if c occurs in x, m otherwise.
: bmBc[c] = min{i : 1 i <m-1 and x[m-1-i]=c} if c occurs in x, m otherwise.
Tables bmBc and bmGs can be precomputed in time O(m+) before the searching phase and require an extra-space in O(m+). The searching phase time complexity is quadratic but at most 3n text character comparisons are performed when searching for a non periodic pattern. On large alphabets (relatively to the length of the pattern) the algorithm is extremely fast. When searching for am-1b in bn the algorithm makes only O(n / m) comparisons, which is the absolute minimum for any string-matching algorithm in the model where the pattern only is preprocessed.
The C code
void preBmBc(char *x, int m, int bmBc[]) {
int i;
for (i = 0; i < ASIZE; ++i)
bmBc[i] = m;
for (i = 0; i < m - 1; ++i)
bmBc[x[i]] = m - i - 1;
}
void suffixes(char *x, int m, int *suff) {
int f, g, i;
suff[m - 1] = m;
g = m - 1;
for (i = m - 2; i >= 0; --i) {
if (i > g && suff[i + m - 1 - f] < i - g)
suff[i] = suff[i + m - 1 - f];
else {
if (i < g)
g = i;
f = i;
while (g >= 0 && x[g] == x[g + m - 1 - f])
--g;
suff[i] = f - g;
}
}
}
void preBmGs(char *x, int m, int bmGs[]) {
int i, j, suff[XSIZE];
suffixes(x, m, suff);
for (i = 0; i < m; ++i)
bmGs[i] = m;
j = 0;
for (i = m - 1; i >= 0; --i)
if (suff[i] == i + 1)
for (; j < m - 1 - i; ++j)
if (bmGs[j] == m)
bmGs[j] = m - 1 - i;
for (i = 0; i <= m - 2; ++i)
bmGs[m - 1 - suff[i]] = m - 1 - i;
}
void BM(char *x, int m, char *y, int n) {
int i, j, bmGs[XSIZE], bmBc[ASIZE];
/* Preprocessing */
preBmGs(x, m, bmGs);
preBmBc(x, m, bmBc);
/* Searching */
j = 0;
while (j <= n - m) {
for (i = m - 1; i >= 0 && x[i] == y[i + j]; --i);
if (i < 0) {
OUTPUT(j);
j += bmGs[0];
}
else
j += MAX(bmGs[i], bmBc[y[i + j]] - m + 1 + i);
}
}
Preprocessing phase

mBc and bmGs tables used by Boyer-Moore algorithm
Searching phase
- AHO, A.V., 1990, Algorithms for finding patterns in strings. in Handbook of Theoretical Computer Science, Volume A, Algorithms and complexity, J. van Leeuwen ed., Chapter 5, pp 255-300, Elsevier, Amsterdam.
- AOE, J.-I., 1994, Computer algorithms: string pattern matching strategies, IEEE Computer Society Press.
- BAASE, S., VAN GELDER, A., 1999, Computer Algorithms: Introduction to Design and Analysis, 3rd Edition, Chapter 11, pp. ??-??, Addison-Wesley Publishing Company.
- BAEZA-YATES R., NAVARRO G., RIBEIRO-NETO B., 1999, Indexing and Searching, in Modern Information Retrieval, Chapter 8, pp 191-228, Addison-Wesley.
- BEAUQUIER, D., BERSTEL, J., CHRÉTIENNE, P., 1992, Éléments d'algorithmique, Chapter 10, pp 337-377, Masson, Paris.
- BOYER R.S., MOORE J.S., 1977, A fast string searching algorithm. Communications of the ACM. 20:762-772.
- COLE, R., 1994, Tight bounds on the complexity of the Boyer-Moore pattern matching algorithm, SIAM Journal on Computing 23(5):1075-1091.
- CORMEN, T.H., LEISERSON, C.E., RIVEST, R.L., 1990. Introduction to Algorithms, Chapter 34, pp 853-885, MIT Press.
- CROCHEMORE, M., 1997. Off-line serial exact string searching, in Pattern Matching Algorithms, ed. A. Apostolico and Z. Galil, Chapter 1, pp 1-53, Oxford University Press.
- CROCHEMORE, M., HANCART, C., 1999, Pattern Matching in Strings, in Algorithms and Theory of Computation Handbook, M.J. Atallah ed., Chapter 11, pp 11-1--11-28, CRC Press Inc., Boca Raton, FL.
- CROCHEMORE, M., LECROQ, T., 1996, Pattern matching and text compression algorithms, in CRC Computer Science and Engineering Handbook, A. Tucker ed., Chapter 8, pp 162-202, CRC Press Inc., Boca Raton, FL.
- CROCHEMORE, M., RYTTER, W., 1994, Text Algorithms, Oxford University Press.
- GONNET, G.H., BAEZA-YATES, R.A., 1991. Handbook of Algorithms and Data Structures in Pascal and C, 2nd Edition, Chapter 7, pp. 251-288, Addison-Wesley Publishing Company.
- GOODRICH, M.T., TAMASSIA, R., 1998, Data Structures and Algorithms in JAVA, Chapter 11, pp 441-467, John Wiley & Sons.
- GUSFIELD, D., 1997, Algorithms on strings, trees, and sequences: Computer Science and Computational Biology, Cambridge University Press.
- HANCART, C., 1993. Analyse exacte et en moyenne d'algorithmes de recherche d'un motif dans un texte, Ph. D. Thesis, University Paris 7, France.
- KNUTH, D.E., MORRIS (Jr) J.H., PRATT, V.R., 1977, Fast pattern matching in strings, SIAM Journal on Computing6(1):323-350.
- LECROQ, T., 1992, Recherches de mot, Ph. D. Thesis, University of Orléans, France.
- LECROQ, T., 1995, Experimental results on string matching algorithms, Software - Practice & Experience 25(7):727-765.
- SEDGEWICK, R., 1988, Algorithms, Chapter 19, pp. 277-292, Addison-Wesley Publishing Company.
- SEDGEWICK, R., 1988, Algorithms in C, Chapter 19, Addison-Wesley Publishing Company.
- STEPHEN, G.A., 1994, String Searching Algorithms, World Scientific.
- WATSON, B.W., 1995, Taxonomies and Toolkits of Regular Language Algorithms, Ph. D. Thesis, Eindhoven University of Technology, The Netherlands.
- WIRTH, N., 1986, Algorithms & Data Structures, Chapter 1, pp. 17-72, Prentice-Hall.
Turbo Boyer-Moore algorithm的更多相关文章
- Leetcode OJ : Implement strStr() [ Boyer–Moore string search algorithm ] python solution
class Solution { public: int strStr(char *haystack, char *needle) { , skip[]; char *str = haystack, ...
- Boyer–Moore (BM)字符串搜索算法
在计算机科学里,Boyer-Moore字符串搜索算法是一种非常高效的字符串搜索算法.它由Bob Boyer和J Strother Moore设计于1977年.此算法仅对搜索目标字符串(关键字)进行预处 ...
- Boyer Moore算法(字符串匹配)
上一篇文章,我介绍了KMP算法. 但是,它并不是效率最高的算法,实际采用并不多.各种文本编辑器的"查找"功能(Ctrl+F),大多采用Boyer-Moore算法. Boyer-Mo ...
- Algorithm: pattern searching
kmp算法:用一个数组保存了上一个需要开始搜索的index,比如AAACAAA就是0, 1, 2, 0, 1, 2, 3, ABCABC就是0, 0, 0, 1, 2, 3,复杂度O(M+N) #in ...
- Boyer-Moore 字符串匹配算法
字符串匹配问题的形式定义: 文本(Text)是一个长度为 n 的数组 T[1..n]: 模式(Pattern)是一个长度为 m 且 m≤n 的数组 P[1..m]: T 和 P 中的元素都属于有限的字 ...
- Majority Element问题---Moore's voting算法
Leetcode上面有这么一道难度为easy的算法题:找出一个长度为n的数组中,重复次数超过一半的数,假设这样的数一定存在.O(n2)和O(nlog(n))(二叉树插入)的算法比较直观.Boyer–M ...
- Erlang/Elixir精选-第5期(20200106)
The forgotten ideas in computer science-Joe Armestrong 在2020年的第一期里面,一起回顾2018年Joe的 The forgotten idea ...
- grep之字符串搜索算法Boyer-Moore由浅入深(比KMP快3-5倍)
这篇长文历时近两天终于完成了,前两天帮网站翻译一篇文章“为什么GNU grep如此之快?”,里面提及到grep速度快的一个重要原因是使用了Boyer-Moore算法作为字符串搜索算法,兴趣之下就想了解 ...
- Google Interview University - 坚持完成这套学习手册,你就可以去 Google 面试了
作者:Glowin链接:https://zhuanlan.zhihu.com/p/22881223来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明出处. 原文地址:Google ...
- leetcode 229 Majority Element II
这题用到的基本算法是Boyer–Moore majority vote algorithm wiki里有示例代码 1 import java.util.*; 2 public class Majori ...
随机推荐
- Autofac官方文档翻译--一、注册组件--4组件扫描
官方文档:http://docs.autofac.org/en/latest/register/scanning.html Autofac 组件扫描 在程序集中Autofac 可以使用约定来找到并注册 ...
- vue+element对常用表格的简单封装
在后台管理和中台项目中, table是使用率是特别的高的, 虽然element已经有table组件, 但是分页和其他各项操作还是要写一堆的代码, 所以就在原有的基础上做了进一步的封装 所涵盖的功能有: ...
- Spring源码深度解析之Spring MVC
Spring源码深度解析之Spring MVC Spring框架提供了构建Web应用程序的全功能MVC模块.通过策略接口,Spring框架是高度可配置的,而且支持多种视图技术,例如JavaServer ...
- JAVA_JNI字段描述符“([Ljava/lang/String;)V”(Android)
JNI字段描述符"([Ljava/lang/String;)V "([Ljava/lang/String;)V" 它是一种对函数返回值和参数的编码.这种编码叫做JNI字段 ...
- hadoop大数据组件启动
1.1.启动集群 sbin/start-dfs.sh注:这个启动脚本是通过ssh对多个节点的namenode.datanode.journalnode以及zkfc进程进行批量启动的. 1.2.启动Na ...
- 循序渐进VUE+Element 前端应用开发(31)--- 系统的日志管理,包括登录日志、接口访问日志、实体变化历史日志
在一个系统的权限管理模块中,一般都需要跟踪一些具体的日志,ABP框架的系统的日志管理,包括登录日志.接口访问日志.实体变化历史日志,本篇随笔介绍ABP框架中这些日志的管理和界面处理. 1.系统登录日志 ...
- 风炫安全WEB安全学习第二十三节课 利用XSS获取COOKIE
风炫安全WEB安全学习第二十三节课 利用XSS获取COOKIE XSS如何利用 获取COOKIE 我们使用pikachu写的pkxss后台 使用方法: <img src="http:/ ...
- 杭电1720---A+B Coming(技巧:使用%x)
Problem Description Many classmates said to me that A+B is must needs. If you can't AC this problem, ...
- day116:MoFang:显示背包解锁/未解锁格子数&显示背包的道具物品&背包解锁
目录 1.显示背包的已解锁/未解锁格子数 2.显示背包中的道具物品 3.用户购买道具的时候,判断背包存储是否达到上限 4.道具也可以使用积分购买 5.在商城界面根据金额/积分显示不同商品 6.背包解锁 ...
- Linux设置系统时区
https://www.xlsys.cn/1741.html 如果你的 Linux 系统时区配置不正确,必需要手动调整到正确的当地时区.NTP 对时间的同步处理只计算当地时间与 UTC 时间的偏移量, ...