Distributed | MapReduce
最近终于抽出时间开始学习MIT 6.824,本文为我看MapReduce论文和做lab后的总结。
lab要用到go语言,这也是我第一次接触。可以参考go语言圣经学习基本语法。
[Go语言圣经]
MapReduce 简介
MapReduce描述了一种编程模型,由处理数据的map函数生成中间键值对(Key/Value),再由Reduce函数处理中间键值对生成输出文件。根据用户自定义的map和reduce函数不同,可以实现不同的功能。下面我简单总结了个人觉得比较关键的部分。
执行概述
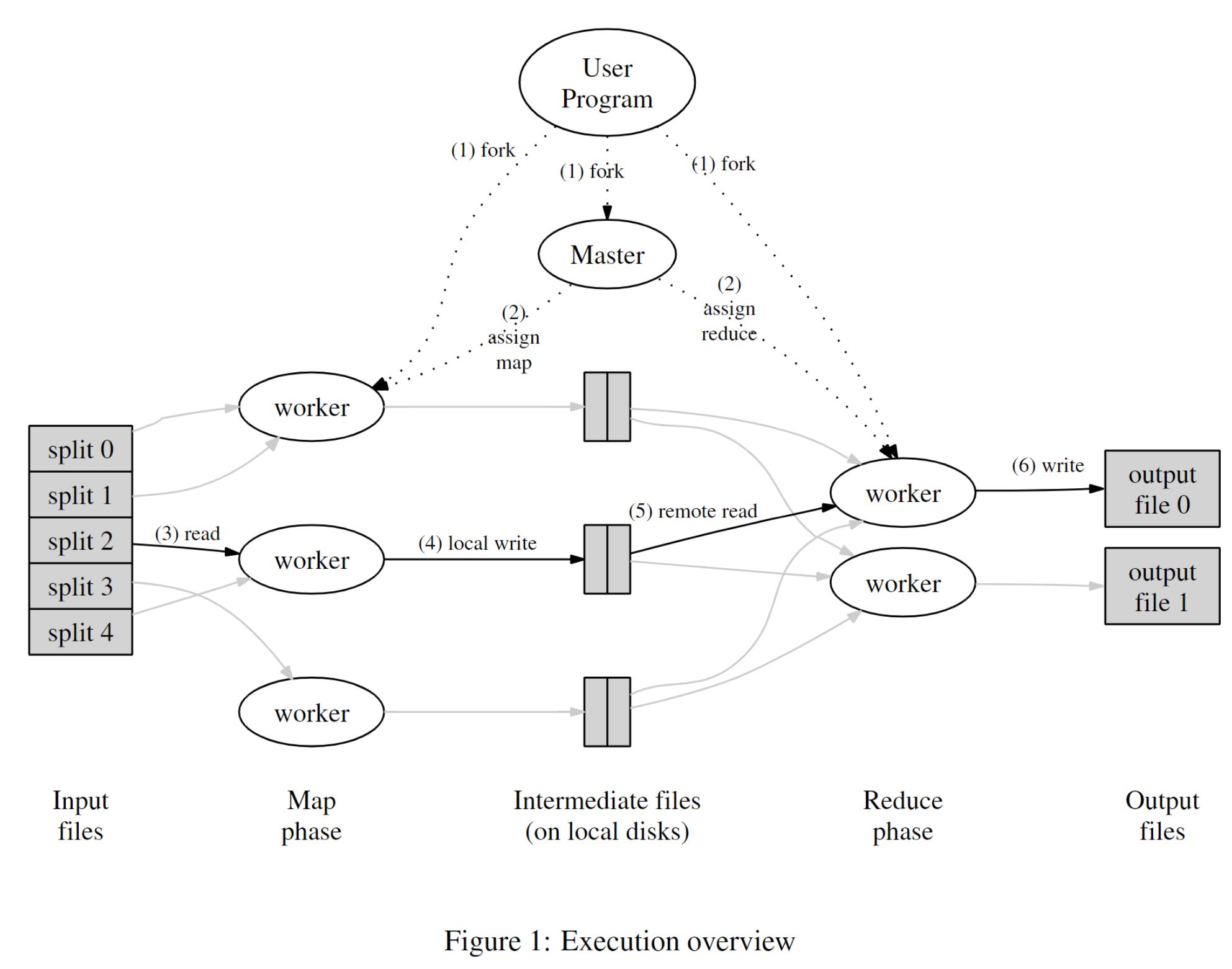
在MapReduce中存在两种程序:master (也即lab中的coordinator) 和worker。master负责分配任务和接受反馈,更新任务列表。worker负责完成map和reduce任务。
在程序运行前,mapreduce库会将输入的数据切分成M个片段,即M个map任务,然后启动master和worker。master会对每个空闲的worker分配map或者reduce任务。
被分配了map任务的worker读取相应任务的数据,解析出键值对,生成中间键值对存入本地磁盘。这些键值对根据key的不同,被分区函数划分到R个区域内。worker将这些数据的位置传回master,master会将这些位置转发给执行reduce操作的worker。
执行reduce任务的worker在接受任务后,使用RPC的方式读取数据,并根据key进行排序,然后调用reduce函数生成R个输出文件。
容错
由于数百上千台机器同时运行,发生网络故障/设备中断是常有的事情,因此需要应对故障的方案。
worker故障
master会周期性的ping下每个worker,如果在一定时间内收不到来自某个worker的响应,master就会将该worker标记为failed,该worker正在执行的任务会被重置为【待执行】。master会将这些任务交给其他worker重新执行。
对于已经执行完的任务。如果是已完成的map任务,由于中间数据储存在发生故障的worker磁盘中,无法读取,因此需要重新执行该任务。如果是reduce任务则无须再执行,因为完成时输出文件已经储存在全局系统中。
master故障
一种解决方案是,将master上的数据周期性地写入磁盘,发生故障后从最新的checkpoint创建出一个新的备份,重启master进程。但往往需要人工干预。
Master的数据结构
在Master中包含了一些数据结构。它保存了每个Map任务和每个Reduce任务的状态(闲置,正在运行,以及完成),以及非空闲任务的worker机器的ID。
备用任务
在MapReduce计算中,一台机器花费了异常长的时间去完成最后几个Map或者Reduce任务会导致执行总时间延长很多。因此当一个MapReduce任务接近完成时,master可以调度一个备用(backup)任务来执行正在执行的任务。无论是主任务还是备用任务完成,都视为整个计算完成。可以显著减少大型计算花费的时间。
Lab1 总结
虽然看论文的时候感觉自己对MapReduce的执行过程了解的比较透彻,但是在实际实现全过程的时候才发现有很多地方没有注意到。果然是实践出真知。
在过程中遇到的一个比较大的坑是我对go的struct不够了解。go中struct用变量名的首字母大小写来区分public和private(可导出和不可导出),习惯了驼峰命名法的我并没有注意到。因此在测试的时候才需要全盘修改,花费了一些精力。
在lab中我们要实现的是一个在本地机器执行的mapreduce任务。和论文中介绍的不同,这个mapreduce没有实现对worker的周期检测,也不需要储存每个worker的状态,而是当worker在一段时间(lab中为10s)内没有完成任务时,直接将该worker视为故障,重新分配任务。并且任务时由worker主动申请再由master进行分配。这对于小任务是可行的,但对于无法预测时间的大型任务,应当按论文中进行实现。
在执行过程中,必须要先将map任务全部执行完,才能执行reduce任务。因为reduce任务要读取全部数据进行排序。当map任务已经分配完但没有全部完成时,部分没有任务可以执行的worker可能会空转。
for {
switch reply.State{
case 0:
//map任务
case 1:
//reduce任务
case 2:
continue //暂时没有任务,等待下一次申请
case 3:
break //所有任务均已完成,worker停止工作
}
在任务分配上,我简单的采用了数组初始化所有任务,在分配任务时从数组中寻找【待执行】的任务(即state为0),更优化的方式可以考虑任务队列。将任务依次入队,对已经执行的任务出队,如果任务执行失败(超时),则重新入队。这样免去了遍历的过程。
因为在mrcoordinator.go中我们可以看到,每隔1s中会执行一次c.Done(),因此可以在c.Done()中增加每次任务的运行时间。
m := mr.MakeCoordinator(os.Args[1:], 10)
for m.Done() == false {
time.Sleep(time.Second)
}
论文中提到通过写入临时文件并重命名它的方式,可以避免在崩溃生成部分写入的文件,造成混乱。ioutil库可以创建临时文件,并在写入结束后重命名为标准文件格式。
在实际上手时,可以先从worker开始,根据程序中给的example,分析执行过程,再在程序中添加对应的实现。RPC调用的函数必须要有返回值,否则运行时会报错找不到该函数。
实现代码
以下为实现代码,通过了全部测试。
//worker.go
package mr
import "fmt"
import "log"
import "net/rpc"
import "hash/fnv"
import (
"time"
"os"
"sort"
"io/ioutil"
"strconv"
"encoding/json"
)
//
// Map functions return a slice of KeyValue.
//
type KeyValue struct {
Key string
Value string
}
type ByKey []KeyValue
// for sorting by key.
func (a ByKey) Len() int { return len(a) }
func (a ByKey) Swap(i, j int) { a[i], a[j] = a[j], a[i] }
func (a ByKey) Less(i, j int) bool { return a[i].Key < a[j].Key }
//
// use ihash(key) % NReduce to choose the reduce
// task number for each KeyValue emitted by Map.
//
func ihash(key string) int {
h := fnv.New32a()
h.Write([]byte(key))
return int(h.Sum32() & 0x7fffffff)
}
//
// main/mrworker.go calls this function.
//
func Worker(mapf func(string, string) []KeyValue,
reducef func(string, []string) string) {
// Your worker implementation here.
// uncomment to send the Example RPC to the coordinator.
// CallExample()
for {
time.Sleep(time.Second) //睡眠一秒再接任务
args := ASKArgs{}
reply := ASKReply{}
callAskTask(&args, &reply)
taskNumber := reply.TaskNumber
switch reply.State{
case 0:
file, err := os.Open(reply.FileName)
if err != nil {
log.Fatalf("cannot open mapTask file", reply.FileName)
}
content, err := ioutil.ReadAll(file)
if err != nil {
log.Fatalf("cannot read mapTask file", reply.FileName)
}
file.Close()
kva := mapf(reply.FileName, string(content))
//写入mr-taskNumber-y文件中
WriteMiddleFile(kva, taskNumber, reply.NReduce)
case 1:
intermediate := []KeyValue{}
nmap := reply.NMap
for i:=0; i<nmap ; i++ {
mapFile := "mr-" + strconv.Itoa(i) + "-" + strconv.Itoa(taskNumber)
inputFile, err := os.OpenFile(mapFile, os.O_RDONLY, 0666)
if err != nil {
log.Fatalf("can not open reduceTask", mapFile)
}
dec := json.NewDecoder(inputFile)
for {
var kv []KeyValue
if err := dec.Decode(&kv); err != nil {
break
}
intermediate = append(intermediate, kv...)
}
}
sort.Sort(ByKey(intermediate))
outFile := "mr-out-" + strconv.Itoa(taskNumber)
tempReduceFile, err := ioutil.TempFile("", "mr-reduce-*")
if err != nil {
log.Fatalf("cannot open", outFile)
}
i := 0
for i < len(intermediate) {
j := i + 1
for j < len(intermediate) && intermediate[j].Key == intermediate[i].Key {
j++
}
values := []string{}
for k := i; k < j; k++ {
values = append(values, intermediate[k].Value)
}
output := reducef(intermediate[i].Key, values)
// this is the correct format for each line of Reduce output.
fmt.Fprintf(tempReduceFile, "%v %v\n", intermediate[i].Key, output)
i = j
}
tempReduceFile.Close()
os.Rename(tempReduceFile.Name(), outFile)
case 2:
continue //暂时没有任务,等待下一次申请
case 3:
break //所有任务均已完成,worker停止工作
}
Args := FinishAgrs{State: reply.State, TaskNumber:taskNumber}
Reply := FinishReply{}
callFinishTask(&Args, &Reply)
if Reply.State == 1 {
break
}
}
}
func WriteMiddleFile(kva []KeyValue, taskNumber int, nReduce int) bool {
buffer := make([][]KeyValue, nReduce)
for _, value := range(kva) {
area := (ihash(value.Key)) % nReduce
buffer[area] = append(buffer[area], value)
}
for area, output := range(buffer) {
outputFile := "mr-" + strconv.Itoa(taskNumber) + "-" + strconv.Itoa(area)
tempMapFile, err := ioutil.TempFile("", "mr-map-*")
if err != nil {
log.Fatalf("cannot open tempMapFile")
}
enc := json.NewEncoder(tempMapFile)
err = enc.Encode(output)
if err != nil {
return false
}
tempMapFile.Close()
os.Rename(tempMapFile.Name(), outputFile) //通过原子地重命名避免写入时崩溃,导致内容不完整
}
return true
}
func callAskTask(args *ASKArgs, reply *ASKReply){
call("Coordinator.ASKTask", &args, &reply)
}
func callFinishTask(args *FinishAgrs, reply *FinishReply){
call("Coordinator.FinishTask", &args, &reply)
}
//
// send an RPC request to the coordinator, wait for the response.
// usually returns true.
// returns false if something goes wrong.
//
func call(rpcname string, args interface{}, reply interface{}) bool {
// c, err := rpc.DialHTTP("tcp", "127.0.0.1"+":1234")
sockname := coordinatorSock()
c, err := rpc.DialHTTP("unix", sockname)
if err != nil {
log.Fatal("dialing:", err)
}
defer c.Close()
err = c.Call(rpcname, args, reply)
if err == nil {
return true
}
fmt.Println(err)
return false
}
//rpc.go
package mr
//
// RPC definitions.
//
// remember to capitalize all names.
//
import "os"
import "strconv"
//
// example to show how to declare the arguments
// and reply for an RPC.
//
type ASKArgs struct {
//申请时不需要任何信息
}
type ASKReply struct {
State int //0-map 1-reduce 2-wait 3-shutdown
FileName string //文件名
TaskNumber int //任务号
NReduce int //reduce任务中的分区数
NMap int //Map任务的总数
}
type FinishAgrs struct{
State int //同reply,用于更新Coordinator状态
TaskNumber int
}
type FinishReply struct{
State int //0-继续接受任务 1-任务全部完成,关闭worker
}
// Add your RPC definitions here.
// Cook up a unique-ish UNIX-domain socket name
// in /var/tmp, for the coordinator.
// Can't use the current directory since
// Athena AFS doesn't support UNIX-domain sockets.
func coordinatorSock() string {
s := "/var/tmp/824-mr-"
s += strconv.Itoa(os.Getuid())
return s
}
//coordinator.go
package mr
import "log"
import "net"
import "os"
import "net/rpc"
import "net/http"
import (
"sync"
)
//缺少检测故障,不能主动分配任务
//由设备主动申请任务,不需要轮训检查设备是否响应,因此不需要机器号
type Coordinator struct {
State int //0-map 1-reduce 2-finish
NMap int //map任务总数
NReduce int //reduce分区数
MapTask map[int]*mapTask //map任务数组
ReduceTask map[int]*reduceTask //reduce任务数组
Mu sync.Mutex
}
type mapTask struct {
FileName string
State int //0-待做 1-进行中 2-已完成
RunTime int
}
type reduceTask struct {
State int //0-待做 1-进行中 2-已完成
RunTime int
}
func (c *Coordinator) TickTick() {
if c.State == 0 {
for TaskNumber, task := range(c.MapTask){
if task.State == 1 {
c.MapTask[TaskNumber].RunTime += 1
if c.MapTask[TaskNumber].RunTime>=10 {
c.MapTask[TaskNumber].State = 0
}
}
}
} else if c.State == 1 {
for TaskNumber, task := range(c.ReduceTask){
if task.State == 1 {
c.ReduceTask[TaskNumber].RunTime += 1
if c.ReduceTask[TaskNumber].RunTime>=10 {
c.ReduceTask[TaskNumber].State = 0
}
}
}
}
}
func (c *Coordinator) ASKTask(args *ASKArgs, reply *ASKReply) error{
c.Mu.Lock()
defer c.Mu.Unlock()
reply.State = 2
reply.NMap = c.NMap
reply.NReduce = c.NReduce
switch c.State {
case 0:
for TaskNumber, task := range(c.MapTask) {
if task.State == 0 {
reply.FileName = task.FileName
reply.State = 0
reply.TaskNumber = TaskNumber
c.MapTask[TaskNumber].State = 1
break
}
}
case 1:
for TaskNumber, task := range(c.ReduceTask) {
if task.State == 0 {
reply.State = 1
reply.TaskNumber = TaskNumber
c.ReduceTask[TaskNumber].State = 1
break
}
}
case 2:
reply.State = 3
}
return nil
}
func (c *Coordinator) FinishTask(args *FinishAgrs, reply *FinishReply) error{
c.Mu.Lock()
defer c.Mu.Unlock()
reply.State = 0
if args.State == 0 {
c.MapTask[args.TaskNumber].State = 2
c.CheckState()
} else {
c.ReduceTask[args.TaskNumber].State = 2
c.CheckState()
if c.State == 2 {
reply.State = 1
}
}
return nil
}
func (c *Coordinator) CheckState() {
for _, task := range(c.MapTask) {
if task.State == 0 || task.State == 1 {
c.State = 0
return
}
}
for _, task := range(c.ReduceTask) {
if task.State == 0 || task.State == 1 {
c.State = 1
return
}
}
c.State = 2
}
//
// start a thread that listens for RPCs from worker.go
//
func (c *Coordinator) server() {
rpc.Register(c)
rpc.HandleHTTP()
//l, e := net.Listen("tcp", ":1234")
sockname := coordinatorSock()
os.Remove(sockname)
l, e := net.Listen("unix", sockname)
if e != nil {
log.Fatal("listen error:", e)
}
go http.Serve(l, nil)
}
//
// main/mrcoordinator.go calls Done() periodically to find out
// if the entire job has finished.
//
func (c *Coordinator) Done() bool {
c.Mu.Lock()
defer c.Mu.Unlock()
ret := false
c.TickTick() //在每次检查是否完成时,增加任务时间
if c.State == 2 {
ret = true
} else {
ret = false
}
return ret
}
//
// create a Coordinator.
// main/mrcoordinator.go calls this function.
// nReduce is the number of reduce tasks to use.
//
func MakeCoordinator(files []string, nReduce int) *Coordinator {
maptask := make(map[int]*mapTask)
reducetask := make(map[int]*reduceTask)
for i, filename := range(files) {
maptask[i] = &mapTask{FileName: filename, State: 0, RunTime: 0}
}
for j := 0; j < nReduce; j++ {
reducetask[j] = &reduceTask{State: 0, RunTime: 0}
}
c := Coordinator{State: 0, NMap: len(files), NReduce: nReduce, MapTask: maptask, ReduceTask: reducetask, Mu: sync.Mutex{}}
c.server()
return &c
}
Distributed | MapReduce的更多相关文章
- MapReduce的核心资料索引 [转]
转自http://prinx.blog.163.com/blog/static/190115275201211128513868/和http://www.cnblogs.com/jie46583173 ...
- MapReduce C++ Library
MapReduce C++ Library for single-machine, multicore applications Distributed and scalable computing ...
- MapReduce剖析笔记之七:Child子进程处理Map和Reduce任务的主要流程
在上一节我们分析了TaskTracker如何对JobTracker分配过来的任务进行初始化,并创建各类JVM启动所需的信息,最终创建JVM的整个过程,本节我们继续来看,JVM启动后,执行的是Child ...
- MapReduce剖析笔记之六:TaskTracker初始化任务并启动JVM过程
在上面一节我们分析了JobTracker调用JobQueueTaskScheduler进行任务分配,JobQueueTaskScheduler又调用JobInProgress按照一定顺序查找任务的流程 ...
- MapReduce剖析笔记之二:Job提交的过程
上一节以WordCount分析了MapReduce的基本执行流程,但并没有从框架上进行分析,这一部分工作在后续慢慢补充.这一节,先剖析一下作业提交过程. 在分析之前,我们先进行一下粗略的思考,如果要我 ...
- [MapReduce] Google三驾马车:GFS、MapReduce和Bigtable
声明:此文转载自博客开发团队的博客,尊重原创工作.该文适合学分布式系统之前,作为背景介绍来读. 谈到分布式系统,就不得不提Google的三驾马车:Google FS[1],MapReduce[2],B ...
- 使用MapReduce实现join操作
在关系型数据库中,要实现join操作是非常方便的,通过sql定义的join原语就可以实现.在hdfs存储的海量数据中,要实现join操作,可以通过HiveQL很方便地实现.不过HiveQL也是转化成 ...
- 分布式系统(Distributed System)资料
这个资料关于分布式系统资料,作者写的太好了.拿过来以备用 网址:https://github.com/ty4z2008/Qix/blob/master/ds.md 希望转载的朋友,你可以不用联系我.但 ...
- hadoop 学习笔记:mapreduce框架详解
开始聊mapreduce,mapreduce是hadoop的计算框架,我学hadoop是从hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
随机推荐
- web effects collection
web effects collection typewriter effect js 打字机效果 http://www.mattboldt.com/demos/typed-js/ https://g ...
- scrollTo & js auto scroll & scrollX & scrollY
scrollTo & js auto scroll & scrollX & scrollY scrollX & scrollY 获取 scroll top height ...
- Linux & SIGUSER1
Linux & SIGUSER1 https://stackoverflow.com/questions/10824886/how-to-signal-an-application-witho ...
- babel 常用操作
astexplorer babel-types code to ast const { parse } = babel; const code = ` for (let k in ${data}) { ...
- C/C++子函数参数传递,堆栈帧、堆栈参数详解
本文转载自C/C++子函数参数传递,堆栈帧.堆栈参数详解 导语 因为参数传递和汇编语言有很大联系,之后会出现较多x86汇编代码. 该文会先讲一下x86的堆栈参数传递过程,然后再分析C/C++子函数是怎 ...
- .NET 云原生架构师训练营(模块二 基础巩固 安全)--学习笔记
2.8 安全 认证 VS 授权 ASP .NET Core 认证授权中间件 认证 JWT 认证 授权 认证 VS 授权 认证是一个识别用户是谁的过程 授权是一个决定用户可以干什么的过程 401 Una ...
- 第30天学习打卡(异常概述 IO流概述)
异常概述 即非正常情况,通俗的说,异常就是程序出现的错误 异常的分类(Throwable) 异常(Exception) 合理的应用程序可能需要捕获的问题 举例:NullPointerException ...
- Django-1.11中文文档-模型Models(一)
官方文档链接 模型是数据信息的唯一并明确的来源.它包含了我们储存的数据的基本字段和行为.通常,每个模型映射到一张数据库表. 基本概念: 每个模型都是django.db.models.Model的一个子 ...
- Docker下FastDFS环境搭建
本文使用docker进行搭建. #拉取镜像docker pull delron/fastdfs#创建tracker容器docker create --network=host --name trac ...
- 微信小程序一周时间表
<view class="dateView"> <image class="dateLeft" bindtap="prevWeek& ...