INTERSPEECH2020 语音情感分析论文之我见
摘要:本文为大家带来InterSpeech2020 语音情感分析25篇论文中的其中8篇的总结。
本文分享自华为云社区《INTERSPEECH2020 语音情感分析论文总结一》,原文作者:Tython。
1. Learning Utterance-level Representations with Label Smoothing for Speech Emotion Recognition(INTERSPEECH2020)
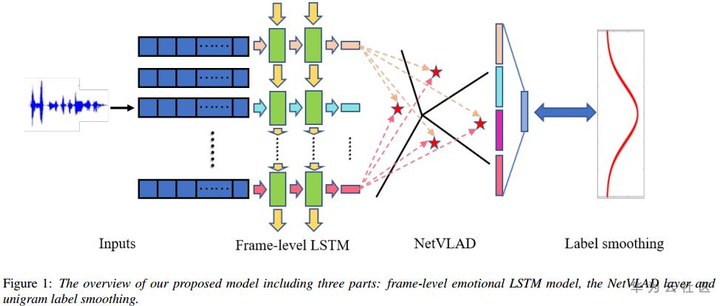
(1)数据处理:IEMOCAP四分类,leave-one-speaker-out,unweighted accuracy。openSMILE对短时帧提取147维LLDs特征。
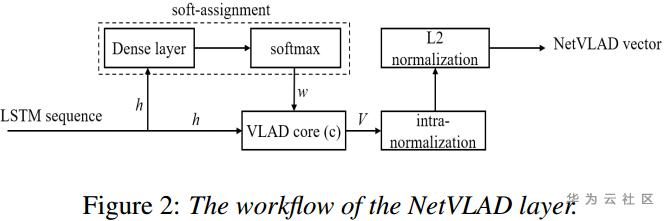
(2)模型方法:采用LSTM对一句话的多个segment的特征序列建模,输出的特征序列经过NetVLAD进行聚类压缩,由原来的N*D的维度降为K*D,再对降维后的特征进行softmax分类。在类别标签上,作者采用标签平滑(label smoothing)策略,即在训练过程中,加入非匹配的(X,y)数据对,也叫作label-dropout(dropping the real labels and replace them with others),并分配一个权值小的标签。以此提升模型的适应性,减少过拟合。
(3)NetVLAD源自图像特征提取方法的一种VLAD,通过对图像的特征向量聚类,得聚类中心并做残差,将一个若干局部特征压缩为特定大小全局特征的方法。具体可参考https://zhuanlan.zhihu.com/p/96718053
(4)实验:NetVLAD可看作一种pooling方法,最后WA达62.6%,高出weighted-pooling2.3个百分点。label smoothing前后的效果分别是59.6%和62%,相差两个百分点。
(5)总结:最大的贡献在于对每个frame的特征进行NetVLAD做类似池化操作,筛选有用特征;另外在训练方式上也引入label smoothing操作,提升效果两个点。
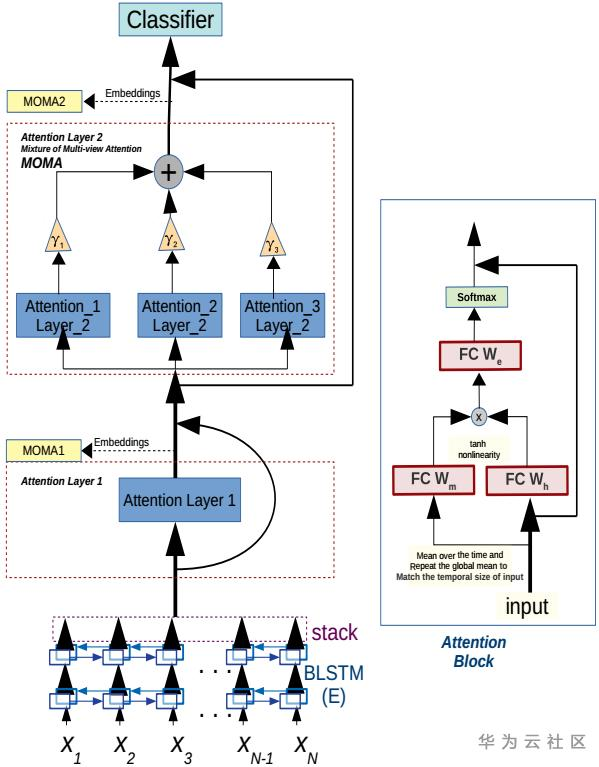
2. Removing Bias with Residual Mixture of Multi-View Attention for Speech Emotion Recognition(INTERSPEECH2020)
(1)数据处理:IEMOCAP数据四分类,Session1-4训练,Session5测试。特征提取23维的log-Mel filterbank。
(2)模型方法:一个Utterance分成N帧,依次输入BLSTM(Hidden layer 512 nodes),得到N*1024大小的矩阵,输入第一个Attention layer 1。将该layer的输出合上原始的矩阵一起分别输入三个Attention_i_Layer_2,该三个attention层分别独立并受超参数gama控制。然后将三个输出求和,并输入一个全连接层(1024 nodes),最后softmax层做分类。
(3)实验:采用WA,UA作为评价指标,但是文章定义UA错误,UA的定义实际为WA。而WA的定义也存疑。实验效果UA达80.5%,实为segment-level的Accuracy。并没有通用的句子级的Accuracy,也是评价的一个trick。
(4)总结:论文的创新主要对经过BLSTM的特征进行多个Attention操作,作为MOMA模块,取得显著的效果提升。但是该提升只体现在segment-level的准确率,参考意义不大。
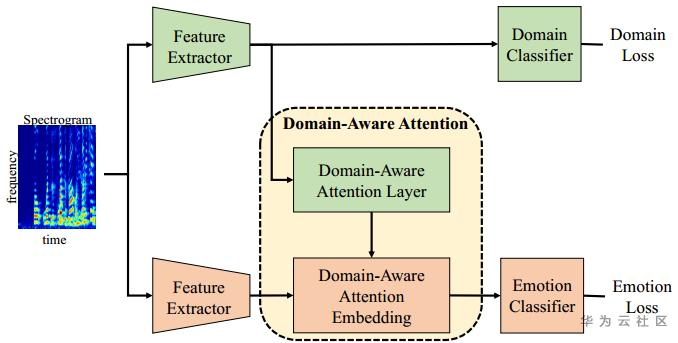
3. Adaptive Domain-Aware Representation Learning for Speech Emotion Recognition
(1)数据处理:IEMOCAP数据四分类,leave-one-speaker-out。STFT汉明窗提取频谱特征,窗长分别为20ms, 40ms,窗移10ms。
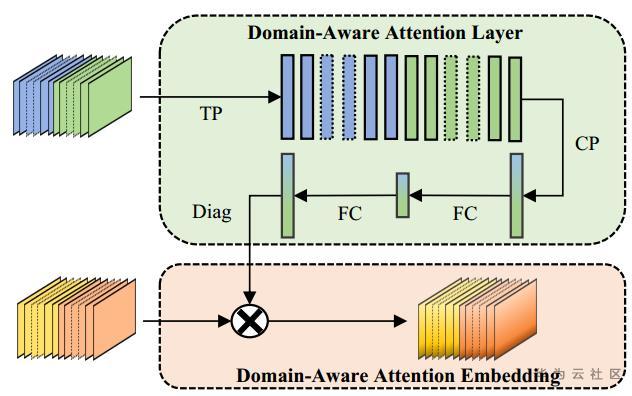
(2)模型方法:输入同一频谱图,分成两部分,一部分到Domain-Aware Attention模块(time pooling, channel pooling and fully connected layer, respectively),另一部分至Emotion模块,做time pooling, channel-wise fully connected(各channel分别全连接)。然后Domain模块输出一个向量,将向量变成对角矩阵,与Emotion模块的输出矩阵相乘,使得领域信息融入到emotion embedding。最后多任务学习,分别求Domain loss和Emotion loss。这里的Domain并不是指不同领域的数据,而是指性别、年龄等额外信息。
(3)实验:WA达到73.02%,UA达到65.86%,主要对Happy情绪的分类不准确。相比单任务emotion分类,多任务WA高出3%,WA高出9%。
(4)总结:论文实质上就是多任务学习,以此提升情绪分类效果。
4. Speech Emotion Recognition with Discriminative Feature Learning
(1)数据处理:IEMOCAP数据四分类,train:validate:test=0.55:0.25:0.2。所有utterance切分或填充到7.5s,提取LLDs特征log-Melfilterbank四十维特征,窗长分别为25ms,窗移10ms。
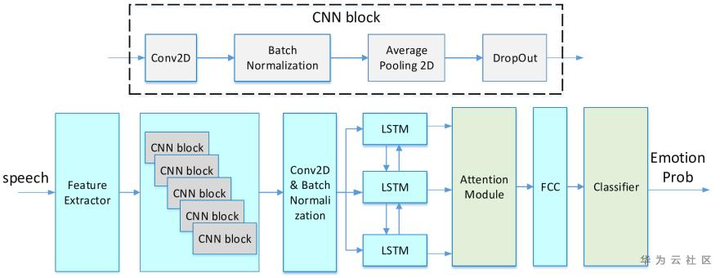
(2)模型方法:输入语谱图,六个CNN block重头到尾进行卷积,提取特征;之后出入到LSTM序列建模,Attention模块对LSTM的输入进行选择权重,最后全连接层再softmax分类。
(3)实验:UA达到62.3%,比baseline的效果低(67.4%),但论文重点在于模型轻(参数量小于360K),计算快。另一个验证Additive margin softmax loss, Focal loss跟attention pooling效果相当,都能达到66%左右。
(4)总结:论文的创新不在网络结构,而是采用不同loss的效果。
5. Using Speech Enhancement Preprocessing for Speech Emotion Recognition in Realistic Noisy Conditions
(1)数据处理:IEMOCAP数据人工加入噪音,CHEAVD数据本生存在噪音,因此不用加噪音。
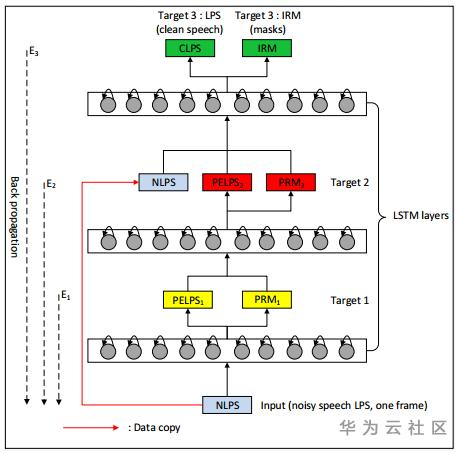
(2)模型方法:本文章是一个语音增强模型。输入带噪频谱,目标是生成纯净语音的频谱以及ideal ratio mask,中间有三层的LSTM层,每层会生成一些频谱特征以及相应的mask。最后一层输出生成的纯净语音频谱和IRM。
(3)实验:前者IEMOCAP数据和WSJ0数据一起用于训练语音增强模型,然后对IEMOCAP的测试集(加噪音后)进行情绪预测。后者语音增强模型首先在1000小时语料上训练好,然后对CHEAVD数据进行增强,增强后的语音用于语音情感识别。
(4)总结:语音增强模型在含语音情感的数据上训练后,对于带噪的语音情感识别任务效果显著;在一些低信噪比、低能量和笑声的片段中,语音增强后往往会被扭曲(distorted),SER效果可能会下降。
6. Comparison of glottal source parameter values in emotional vowels
(1)数据处理:日本JAIST录制的语音数据,四个人(两男两女),每人表达4种情绪(生气、愉悦、中性、悲伤)。发音为元音a。
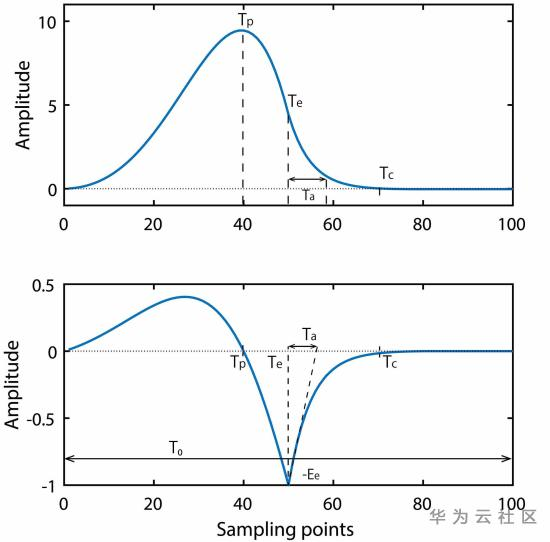
(2)模型方法:ARX-LF模型,the ARX-LF model has been widely used for representing glottal source waves and vocal tract filter。
(3)实验:对声门音(glottal source)的波形(waveform)分析,发现悲伤的元音更圆滑而愉悦和生气的更陡峭。统计参数(parameters)Tp, Te, Ta, Ee, F0(1/T0)发现,基频F0对不同情绪差异显著。
(4)总结:偏传统语言情感研究的方向,研究声门音对情绪的表达情况,具有探索性,在全面DL的趋势下,难能可贵。后续可对这些数据进行DL建模,也许是一个方向。但是难度在于声门音的收集与标注,目前的实验数据较为稀少且人工录制,成本高,数据量少。
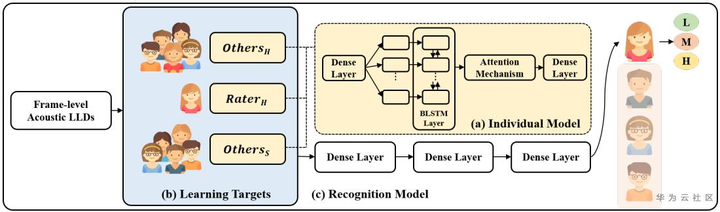
7. Learning to Recognize Per-rater’s Emotion Perception Using Co-rater Training Strategy with Soft and Hard Labels
(1)数据处理:IEMOCAP数据和NNIME数据,对valence、activation的评分1-5分别划成low/middle/high三个离散类别。特征源自openSMILE的45维特征,含MFCC、F0和响度等。
(2)模型方法:对于每一段音频,每人对它的情绪感知不一样,传统采用投票机制,选择众数作为唯一标签。本文采用不同的策略,对每个人的情感标签进行预测。基本模型是BLSTM-DNN模型,下图中的(a)部分。训练数据的标签分成三部分,一个是每个人的硬标签(唯一),另外两个是除了该目标人的其他人的软标签和硬标签。三类标签数据分别用BLSTM-DNN模型单独训练。然后冻结BLSTM-DNN参数,将各BLSTM-DNN的dense layer层的输出拼接,再叠加三个Dense layers,最后softmax到个人的硬标签。因此预测阶段,每个人有对应的情绪感知,当存在N个人的话,将有N个模型。
(3)硬标签与软标签:对于一段音频,如果三个标注人员的标注结果是[L, L, M],那硬标签就是L,即[1, 0, 0];软标签则是[0.67, 0.33, 0],即三个类别的占比数。
(4)实验:比单独个人的标签建模提升1-4个百分点,软硬标签的设计有助于提升SER效果。只需标注目标人物50%的数据,就能取得标注100%的效果。意思是对于新来一个用户,他只需标注IEMOCAP 50%的数据,该模型就能取得他标注100%数据效果。
(5)总结:原理上确实众包的标注有利于推测个人的标签,但是没有跟其他模型进行对比,不过这也不是本文的重点。
8. Empirical Interpretation of Speech Emotion Perception with Attention Based Model for Speech Emotion Recognition
(1)数据处理:IEMOCAP数据四分类,Session1-4训练,Session5测试。特征提取23维的log-Mel filterbank。
(2)模型方法:一个utterance分成多帧,一份输入BLSTM+Attention模型,另一个输入CNN+Attention模型。然后将两个模型的结果融合。
(3)实验:采用WA,UA作为评价指标,但是文章定义UA错误,UA的定义实际为WA。而WA的定义也存疑。实验效果UA达80.1%,实为segment-level的Accuracy。并没有通用的句子级的Accuracy,也是评价的一个trick。
(4)总结:论文就是两个主流模型的结果级融合,创新性不高。提升只体现在segment-level的准确率,参考意义不大。
INTERSPEECH2020 语音情感分析论文之我见的更多相关文章
- 论文笔记:语音情感识别(四)语音特征之声谱图,log梅尔谱,MFCC,deltas
一:原始信号 从音频文件中读取出来的原始语音信号通常称为raw waveform,是一个一维数组,长度是由音频长度和采样率决定,比如采样率Fs为16KHz,表示一秒钟内采样16000个点,这个时候如果 ...
- 论文笔记:语音情感识别(三)手工特征+CRNN
一:Emotion Recognition from Human Speech Using Temporal Information and Deep Learning(2018 InterSpeec ...
- 论文笔记:语音情感识别(五)语音特征集之eGeMAPS,ComParE,09IS,BoAW
一:LLDs特征和HSFs特征 (1)首先区分一下frame和utterance,frame就是一帧语音.utterance是一段语音,是比帧高一级的语音单位,通常指一句话,一个语音样本.uttera ...
- 论文笔记:语音情感识别(二)声谱图+CRNN
一:An Attention Pooling based Representation Learning Method for Speech Emotion Recognition(2018 Inte ...
- 情感分析的现代方法(包含word2vec Doc2Vec)
英文原文地址:https://districtdatalabs.silvrback.com/modern-methods-for-sentiment-analysis 转载文章地址:http://da ...
- Python爬虫和情感分析简介
摘要 这篇短文的目的是分享我这几天里从头开始学习Python爬虫技术的经验,并展示对爬取的文本进行情感分析(文本分类)的一些挖掘结果. 不同于其他专注爬虫技术的介绍,这里首先阐述爬取网络数据动机,接着 ...
- R语言做文本挖掘 Part5情感分析
Part5情感分析 这是本系列的最后一篇文章,该.事实上这种单一文本挖掘的每一个部分进行全部值获取水落石出细致的研究,0基础研究阶段.用R里面现成的算法,来实现自己的需求,当然还參考了众多网友的智慧结 ...
- python snownlp情感分析简易demo
SnowNLP是国人开发的python类库,可以方便的处理中文文本内容,是受到了TextBlob的启发而写的,由于现在大部分的自然语言处理库基本都是针对英文的,于是写了一个方便处理中文的类库,并且和T ...
- pyhanlp文本分类与情感分析
语料库 本文语料库特指文本分类语料库,对应IDataSet接口.而文本分类语料库包含两个概念:文档和类目.一个文档只属于一个类目,一个类目可能含有多个文档.比如搜狗文本分类语料库迷你版.zip,下载前 ...
随机推荐
- console.clear
console.clear Chrome console.clear && console.clear() refs xgqfrms 2012-2020 www.cnblogs.com ...
- Iterators & Generators in depth
Iterators & Generators in depth https://developer.mozilla.org/en-US/docs/Web/JavaScript/Guide/It ...
- Jupyter All In One
Jupyter All In One Jupyter Architecture https://jupyter.readthedocs.io/en/latest/projects/architectu ...
- npm published cli package's default install missing the `-g` flag
npm published cli package's default install missing the -g flag https://npm.community/t/npm-publishe ...
- [转]RoboWare Studio的使用和发布器/订阅器的编写与测试
原文地址:https://blog.csdn.net/han_l/article/details/77772352,转载主要方便随时查阅,如有版权要求,请及时联系. 开始ROS学习之前,先按照官网教程 ...
- Spring Security 实战干货:OAuth2登录获取Token的核心逻辑
1. 前言 在上一篇Spring Security 实战干货:OAuth2授权回调的核心认证流程中,我们讲了当第三方同意授权后会调用redirectUri发送回执给我们的服务器.我们的服务器拿到一个中 ...
- (十一) 数据库查询处理之连接(Join)
(十一) 数据库查询处理之连接(Join) 1. 连接操作的一个例子 把外层关系和内层关系中满足一定关系的属性值拼接成一个新的元组 一种现在仍然十分有用的优化思路Late Materializatio ...
- RabbitMQ之死信队列
1:何为死信队列 死信队列也是一个正常的队列,可以被消费. 但是,死信队列的消息来源于其他队列的转发. 2:如何触发死信队列 1:消息超时 2:队列长度达到极限 3:消息被拒绝消费,并不再重进队列,且 ...
- MySQL学习笔记(六)
好耶,七天课程的最后一天!我当然还没精通了,,,之后可能是多练习题目然后再学学其他的东西吧.mysql新的知识点也会在后面补充的. 一.杂七杂八补充 1. 当多个函数共用同样的参数时,可以转变成类进行 ...
- 记录vue springboot 跨域采坑
vue配置 域名src\main.js要与config\index.js一样 var axios = require('axios')axios.defaults.baseURL = 'http:// ...