pyhanlp文本分类与情感分析
语料库
本文语料库特指文本分类语料库,对应IDataSet接口。而文本分类语料库包含两个概念:文档和类目。一个文档只属于一个类目,一个类目可能含有多个文档。比如搜狗文本分类语料库迷你版.zip,下载前请先阅读搜狗实验室数据使用许可协议。
用Map描述
这种关系可以用Java的Map<String, String[]>来描述,其key代表类目,value代表该类目下的所有文档。用户可以利用自己的文本读取模块构造一个Map<String, String[]>形式的中间语料库,然后利用IDataSet#add(java.util.Map<java.lang.String,java.lang.String[]>)接口将其加入到训练语料库中。
用文件夹描述
这种树形结构也很适合用文件夹描述,即:
/**
* 加载数据集
*
* @param folderPath 分类语料的根目录.目录必须满足如下结构:<br>
* 根目录<br>
* ├── 分类A<br>
* │ └── 1.txt<br>
* │ └── 2.txt<br>
* │ └── 3.txt<br>
* ├── 分类B<br>
* │ └── 1.txt<br>
* │ └── ...<br>
* └── ...<br>
* 文件不一定需要用数字命名,也不需要以txt作为后缀名,但一定需要是文本文件.
* @param charsetName 文件编码
* @return
* @throws IllegalArgumentException
* @throws IOException
*/
IDataSet load(String folderPath, String charsetName) throws IllegalArgumentException, IOException;
例如:
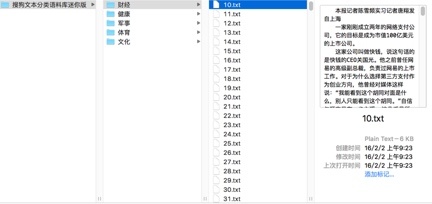
每个分类里面都是一些文本文档。任何满足此格式的语料库都可以直接加载。
数据集实现
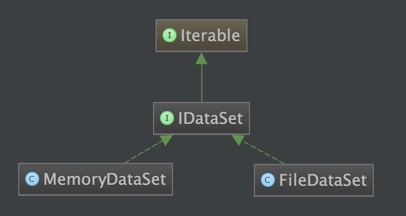
考虑到大规模训练的时候,文本数量达到千万级,无法全部加载到内存中,所以本系统实现了基于文件系统的FileDataSet。同时,在服务器资源许可的情况下,可以使用基于内存的MemoryDataSet,提高加载速度。两者的继承关系如下:
训练
训练指的是,利用给定训练集寻找一个能描述这种语言现象的模型的过程。开发者只需调用train接口即可,但在实现中,有许多细节。
分词
目前,本系统中的分词器接口一共有两种实现:
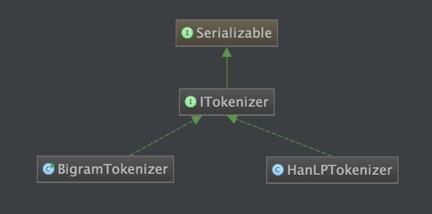
但文本分类是否一定需要分词?答案是否定的。 我们可以顺序选取文中相邻的两个字,作为一个“词”(术语叫bigram)。这两个字在数量很多的时候可以反映文章的主题(参考清华大学2016年的一篇论文《Zhipeng Guo, Yu Zhao, Yabin Zheng, Xiance Si, Zhiyuan Liu, Maosong Sun. THUCTC: An Efficient Chinese Text Classifier. 2016》)。这在代码中对应BigramTokenizer. 当然,也可以采用传统的分词器,如HanLPTokenizer。 另外,用户也可以通过实现ITokenizer来实现自己的分词器,并通过IDataSet#setTokenizer来使其生效。
特征提取
特征提取指的是从所有词中,选取最有助于分类决策的词语。理想状态下所有词语都有助于分类决策,但现实情况是,如果将所有词语都纳入计算,则训练速度将非常慢,内存开销非常大且最终模型的体积非常大。
本系统采取的是卡方检测,通过卡方检测去掉卡方值低于一个阈值的特征,并且限定最终特征数不超过100万。
调参
对于贝叶斯模型,没有超参数需要调节。
训练
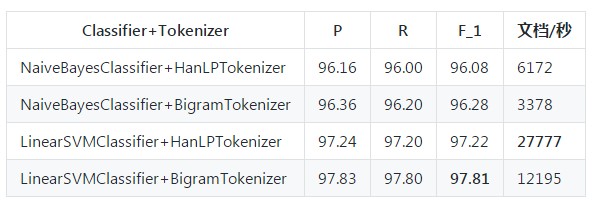
本系统实现的训练算法是朴素贝叶斯法,无需用户关心内部细节。另有一个子项目实现了支持向量机文本分类器,可供参考。由于依赖了第三方库,所以没有集成在本项目中。相关性能指标如下表所示:
模型
训练之后,我们就得到了一个模型,可以通过IClassifier#getModel获取到模型的引用。该接口返回一个AbstractModel对象,该对象实现了Serializable接口,可以序列化到任何地方以供部署。 反序列化后的模型可以通过如下方式加载并构造分类器:
NaiveBayesModel model = (NaiveBayesModel) IOUtil.readObjectFrom(MODEL_PATH);
NaiveBayesClassifier naiveBayesClassifier = new NaiveBayesClassifier(model);
分类
通过加载模型,我们可以得到一个分类器,利用该分类器,我们就可以进行文本分类了。
IClassifier classifier = new NaiveBayesClassifier(model);
目前分类器接口中与文本分类有关的接口有如下三种:
/**
* 预测分类
*
* @param text 文本
* @return 所有分类对应的分值(或概率, 需要enableProbability)
* @throws IllegalArgumentException 参数错误
* @throws IllegalStateException 未训练模型
*/
Map<String, Double> predict(String text) throws IllegalArgumentException, IllegalStateException;
/**
* 预测分类
* @param document
* @return
*/
Map<String, Double> predict(Document document) throws IllegalArgumentException, IllegalStateException;
/**
* 预测分类
* @param document
* @return
* @throws IllegalArgumentException
* @throws IllegalStateException
*/
double[] categorize(Document document) throws IllegalArgumentException, IllegalStateException;
/**
* 预测最可能的分类
* @param document
* @return
* @throws IllegalArgumentException
* @throws IllegalStateException
*/
int label(Document document) throws IllegalArgumentException, IllegalStateException;
/**
* 预测最可能的分类
* @param text 文本
* @return 最可能的分类
* @throws IllegalArgumentException
* @throws IllegalStateException
*/
String classify(String text) throws IllegalArgumentException, IllegalStateException;
/**
* 预测最可能的分类
* @param document 一个结构化的文档(注意!这是一个底层数据结构,请谨慎操作)
* @return 最可能的分类
* @throws IllegalArgumentException
* @throws IllegalStateException
*/
String classify(Document document) throws IllegalArgumentException, IllegalStateException;
classify方法直接返回最可能的类别的String形式,而predict方法返回所有类别的得分(是一个Map形式,键是类目,值是分数或概率),categorize方法返回所有类目的得分(是一个double数组,分类得分按照分类名称的字典序排列),label方法返回最可能类目的字典序。
线程安全性
类似于HanLP的设计,以效率至上,本系统内部实现没有使用任何线程锁,但任何预测接口都是线程安全的(被设计为不储存中间结果,将所有中间结果放入参数栈中)。
情感分析
可以利用文本分类在情感极性语料上训练的模型做浅层情感分析。目前公开的情感分析语料库有:中文情感挖掘语料-ChnSentiCorp,语料发布者为谭松波。
接口与文本分类完全一致,请参考com.hankcs.demo.DemoSentimentAnalysis。
性能指标
一般来讲,受到语料库质量的约束(部分语料库的分类标注模糊或有重叠),我们评测一个分类器时,必须严谨地注明在哪个语料库以何种比例分割数据集下得到这样的测试结果。
版本库中有一个在搜狗语料库上的测试com.hankcs.demo.DemoTextClassificationFMeasure,含有完整的参数,请自行运行评估。
pyhanlp文本分类与情感分析的更多相关文章
- TensorFlow实现文本情感分析详解
http://c.biancheng.net/view/1938.html 前面我们介绍了如何将卷积网络应用于图像.本节将把相似的想法应用于文本. 文本和图像有什么共同之处?乍一看很少.但是,如果将句 ...
- TensorFlow文本情感分析实现
TensorFlow文本情感分析实现 前面介绍了如何将卷积网络应用于图像.本文将把相似的想法应用于文本. 文本和图像有什么共同之处?乍一看很少.但是,如果将句子或文档表示为矩阵,则该矩阵与其中每个单元 ...
- LSTM 文本情感分析/序列分类 Keras
LSTM 文本情感分析/序列分类 Keras 请参考 http://spaces.ac.cn/archives/3414/ neg.xls是这样的 pos.xls是这样的neg=pd.read_e ...
- 浅谈NLP 文本分类/情感分析 任务中的文本预处理工作
目录 浅谈NLP 文本分类/情感分析 任务中的文本预处理工作 前言 NLP相关的文本预处理 浅谈NLP 文本分类/情感分析 任务中的文本预处理工作 前言 之所以心血来潮想写这篇博客,是因为最近在关注N ...
- LSTM实现中文文本情感分析
1. 背景介绍 文本情感分析是在文本分析领域的典型任务,实用价值很高.本模型是第一个上手实现的深度学习模型,目的是对深度学习做一个初步的了解,并入门深度学习在文本分析领域的应用.在进行模型的上手实现之 ...
- 基于 Spark 的文本情感分析
转载自:https://www.ibm.com/developerworks/cn/cognitive/library/cc-1606-spark-seniment-analysis/index.ht ...
- 文本情感分析(一):基于词袋模型(VSM、LSA、n-gram)的文本表示
现在自然语言处理用深度学习做的比较多,我还没试过用传统的监督学习方法做分类器,比如SVM.Xgboost.随机森林,来训练模型.因此,用Kaggle上经典的电影评论情感分析题,来学习如何用传统机器学习 ...
- NLP入门(十)使用LSTM进行文本情感分析
情感分析简介 文本情感分析(Sentiment Analysis)是自然语言处理(NLP)方法中常见的应用,也是一个有趣的基本任务,尤其是以提炼文本情绪内容为目的的分类.它是对带有情感色彩的主观性 ...
- 文本情感分析(二):基于word2vec、glove和fasttext词向量的文本表示
上一篇博客用词袋模型,包括词频矩阵.Tf-Idf矩阵.LSA和n-gram构造文本特征,做了Kaggle上的电影评论情感分类题. 这篇博客还是关于文本特征工程的,用词嵌入的方法来构造文本特征,也就是用 ...
随机推荐
- HTC脚本介绍和入门示例
一.简介 HTC脚本全称是Html Companent即html组件,个人认为它是为了在开发动态HTML中实现代码重用和页面共享目的,主要是把“行为”作为组件封装,可以在很大程度上简化DHTML的开发 ...
- Delphi 10.3.1拍照遇到的问题
procedure TAddOrderCamera.CameraActionExecute(Sender: TObject); var Service: IFMXCameraService; Para ...
- 使用OpenBTS基站测试物联网模块安全性
0×00 引子 近年来,随着云计算.物联网技术的快速发展,物联网的理念和相关技术产品已经广泛渗透到社会经济民生的各个领域,越来越多的穿戴设备.家用电器通过蓝牙.Wi-Fi.Li-Fi.z-wave.L ...
- java学习笔记18(基本类型包装类,system类)
基本类型包装类 定义:程序界面用户输入的数据都是以字符串类型存储的,如果需要操作这些字符串进行运算,需要转成基本数据类型,这时就要用到基本类型包装类,例: public class Demo { pu ...
- Python 命名元组
from collections import namedtuple # 类 p = namedtuple("Point", ["x", "y&quo ...
- 微信公众号开发遇到simplexml_load_string 未定义
1.Go to /etc/php/7.0/fpm and edit php.ini 取消注释: extension=php_xmlrpc.dll 2. sudo apt-get update ...
- Oracle流程控制语句
1.选择语句 1.1 IF...THEN...END IF语句 DECLARE MY_AGE INT; IF MY_AGE IS NULL THEN DBMS_OUTPUT.put_line('AGE ...
- 机器学习: 共轭梯度算法(PCG)
今天介绍数值计算和优化方法中非常有效的一种数值解法,共轭梯度法.我们知道,在解大型线性方程组的时候,很少会有一步到位的精确解析解,一般都需要通过迭代来进行逼近,而 PCG 就是这样一种迭代逼近算法. ...
- 编译Thrift支持golang
本文已经是很久以前的文章了,也不知道新版本thrift如何 Thrift是一个跨语言的服务部署框架,Thrift通过一个中间语言(IDL, 接口定义语言)来定义RPC的接口和数据类型,然后通过一个编译 ...
- python三大框架之一(flask介绍)
Flask , Django, Tornado 是python中常用的框架,也是python的三大框架.它们的区别是:Flask: 轻量级框架: Django:重量级框架: Tornado:性能最好 ...