python爬取酷我音乐
我去!!!我之后一定按照搜索方式下载歌曲~~~~~~~~~
1、首先打开我们本次主讲链接:http://www.kuwo.cn/
2、刚开始我就随便点了一个地方,然后开始在后台找歌曲的链接地址。但是这也使我分析页面分析的很复杂。因为像在酷我音乐,这样的模块都有一个pid,分析参数的时候找了半天还要找pid,,,结果发现这是一个固定值,那就没有意义了,因为pid是一个固定值我总不能只去下载这个模块里面的歌曲,,,想下载其他歌曲还要改代码,这样子就不行了。。。。所以还是从搜索框开始,搜索到哪首歌曲,然后去看看下载哪个歌手唱的

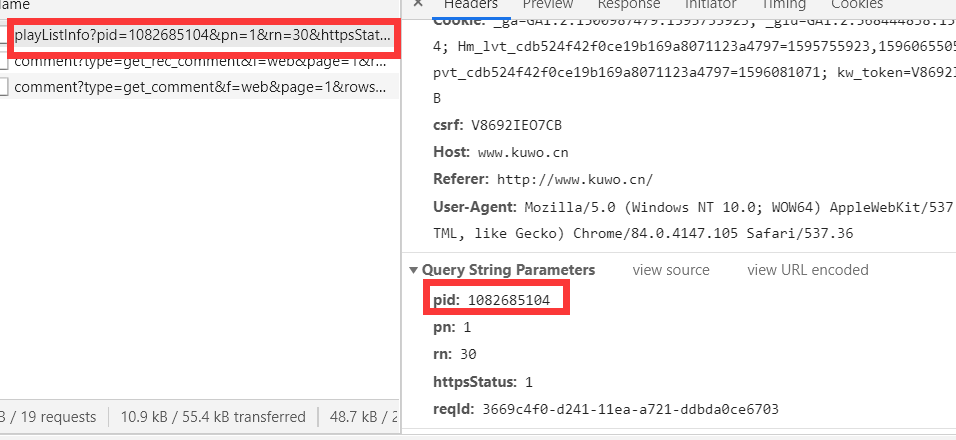
3、酷我很狡猾,当我随便搜索一首歌,然后找这首歌的数据包的时候,如果你用这个数据包的请求头直接在你的浏览器上访问会出现403等错误,反正就是访问不到。我找了半天也找不到,突然觉得酷我很牛掰。我去分析网易云/QQ音乐的时候都没有这个问题。
之后弄了半天才搞清楚,你只要加上一些请求头信息就可以访问成功了。。。。
看来是我太。。。了
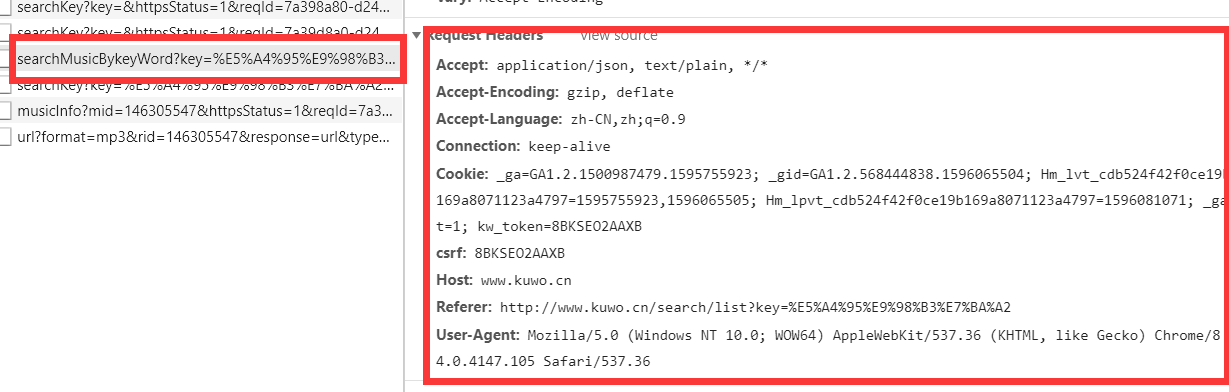
在pycharm上加上请求头,在访问就会成功。不只这个链接是这样,酷我的好多链接访问都要加上请求头(我giao~~~),搞懂这个之后下面就不是问题了
4、因为这个数据包内包含了你搜索歌曲的这一页所有的信息,所以我们要把它爬下来,以便到时候选择
5、之后我们播放歌曲,然后分析一下歌曲的播放链接,下面图片上所显示数据包的url字段就是歌曲的url地址
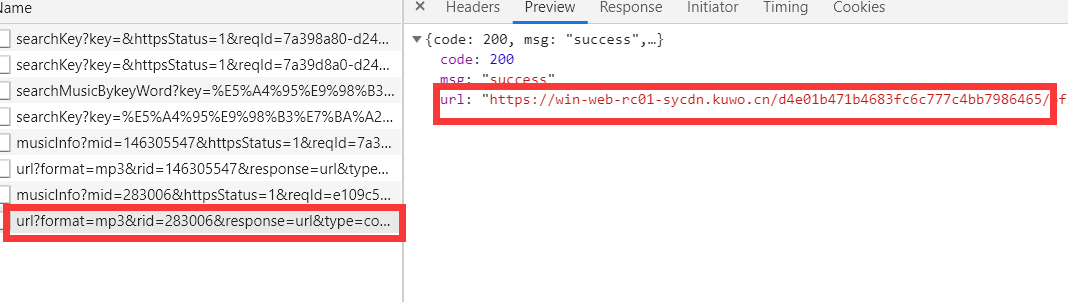
6、之后我们就要分析一下它的请求头
http://www.kuwo.cn/url?format=mp3&rid=283006&response=url&type=convert_url3&br=128kmp3&from=web&t=1596099527340&httpsStatus=1&reqId=e109c5d1-d242-11ea-84b1-4bd35f78cc6c
我giao,发现有好多参数,多播放几首歌曲,发现rid,t,reqId字段的值都不是固定的
本能以为就是在js文件里面生成的(可能爬取网易云爬多了。。。),我找呀找,,,找呀找,,还是没有找到(呜呜呜~~~~~)
于是我特别迷茫,,特特特特别别别迷茫~~~~~~~~
最后才发现,t和reqId字段虽然不是固定的,但是你可以把它当作固定的,,,,啊啊啊啊啊啊啊,服了,恶心人
于是就只需要找rid字段的值就行了

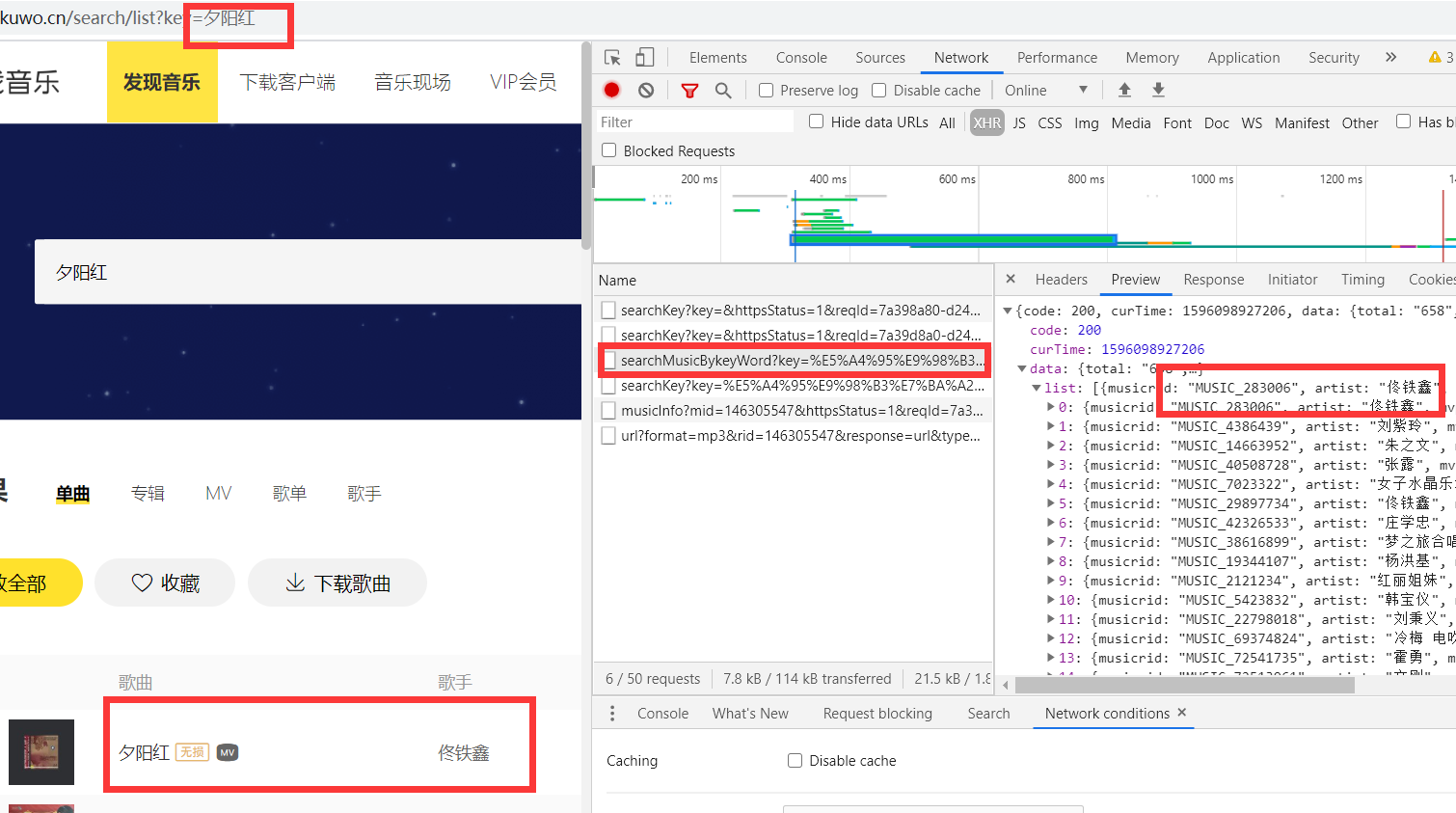
我在搜索框里面找它,给我显示没有(???从此世界上又少了一个单纯的人)rid都找到了,我们就分析一下这个数据包的请求头
http://www.kuwo.cn/api/www/search/searchMusicBykeyWord?key=%E5%A4%95%E9%98%B3%E7%BA%A2&pn=1&rn=30&httpsStatus=1&reqId=7a39ffb0-d241-11ea-84b1-4bd35f78cc6c
很明显key就是你要搜索的内容,pn就是页数,其他值还是当成固定值就行
我真的无语了,既然reqId可以当成固定值,那他还每次都变变变,不管哪个链接都有reqId,它还一直值都不一样,,我真想说zang话
代码(代码也没有整理,将就将就吧!)
import requests
import json headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'
} headers1 = {
'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Cookie': '_ga=GA1.2.1500987479.1595755923; _gid=GA1.2.568444838.1596065504; Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1595755923,1596065505; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1596076178; kw_token=P5XA2TZXG9',
'csrf': 'P5XA2TZXG9',
'Host': 'www.kuwo.cn',
'Referer': 'http://www.kuwo.cn/search/list?key=%E5%A4%95%E9%98%B3%E7%BA%A2',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'
} headers2 = {
'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Cookie': '_ga=GA1.2.1500987479.1595755923; _gid=GA1.2.568444838.1596065504; Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1595755923,1596065505; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1596078189; _gat=1; kw_token=IJATWHHGI8',
'csrf': 'IJATWHHGI8',
'Host': 'www.kuwo.cn',
'Referer': 'http://www.kuwo.cn/search/list?key=%E6%A2%A6%E7%9A%84%E5%9C%B0%E6%96%B9',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36', } key_name = input('请输入你要查找的歌曲名称:')
num = input('请输入你要查看歌曲列表第几页:') url2 = 'http://www.kuwo.cn/api/www/search/searchMusicBykeyWord?key={}&pn={}&rn=30&httpsStatus=1&reqId=da11ad51-d211-11ea-b197-8bff3b9f83d2e'.format(key_name,num) response = requests.get(url2,headers=headers2) #访问歌曲列表
print(response.text)
response.encoding = response.apparent_encoding #这个apparent_encoding就是让系统根据页面来判断用何种编码
response = response.json() # 得到josn字典dict
music_list = response["data"]["list"] #得到歌曲列表
print("共计" + str(len(music_list)) + "结果: ")
all_singers = [] #放置所有歌手人名
names = [] #放置歌曲名字
all_rid = [] #放置所有rid,rid是网页所需参数
a = 0
for music in music_list:
#print(music)
singer = music["artist"] # 歌手名
name = str(a) + " " + music["name"] # 歌曲名 rid = music["musicrid"] #取出rid,之后要对这个字符串进行切割
index = rid.find('_')
rid = rid[index + 1:len(rid)] all_singers.append(singer) #将对应信息放到列表中
names.append(name)
all_rid.append(rid)
a = a + 1
infs = dict(zip(names, all_singers))
infs = json.dumps(infs, ensure_ascii=False, indent=4, separators=(',', ':'))
infs = infs.replace('"', ' ')
infs = infs.replace(':', '——————')
print(infs) order = input("请输入歌曲前的序号:") musicrid = all_rid[int(order)]
url1 = 'http://www.kuwo.cn/url?format=mp3&rid={}&response=url&type=convert_url3&br=128kmp3&from=web&t=1596078536164&httpsStatus=1&reqId=01528151-d212-11ea-b197-8bff3b9f83d2'.format(musicrid) res = requests.get(url1,headers=headers1) #访问歌曲列表
res.encoding = res.apparent_encoding
res = res.json() # dict
res_url = res["url"] #取出歌曲下载url地址 music = requests.get(res_url,headers=headers).content
with open(names[int(order)]+'.mp3','wb') as f:
f.write(music)
python爬取酷我音乐的更多相关文章
- python爬取酷我音乐(收费也可)
第一次创作,请多指教 环境:Python3.8,开发工具:Pycharm 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经做案例的 ...
- 如何使用 python 爬取酷我在线音乐
前言 写这篇博客的初衷是加深自己对网络请求发送和响应的理解,仅供学习使用,请勿用于非法用途!文明爬虫,从我做起.下面进入正题. 获取歌曲信息列表 在酷我的搜索框中输入关键词 aiko,回车之后可以看到 ...
- Python爬取豆瓣音乐存储MongoDB数据库(Python爬虫实战1)
1. 爬虫设计的技术 1)数据获取,通过http获取网站的数据,如urllib,urllib2,requests等模块: 2)数据提取,将web站点所获取的数据进行处理,获取所需要的数据,常使用的技 ...
- python爬取QQVIP音乐
QQ音乐相比于网易云音乐加密部分基本上没有,但是就是QQ音乐的页面与页面之间的联系太强了,,导致下载一个音乐需要分析前面多个页面,找数据..太繁琐了 1.爬取链接:https://y.qq.com/ ...
- Python 爬取qqmusic音乐url并批量下载
qqmusic上的音乐还是不少的,有些时候想要下载好听的音乐,但有每次在网页下载都是烦人的登录什么的.于是,来了个qqmusic的爬虫. 至少我觉得for循环爬虫,最核心的应该就是找到待爬元素所在ur ...
- Python爬虫实战一之爬取QQ音乐
一.前言 前段时间尝试爬取了网易云音乐的歌曲,这次打算爬取QQ音乐的歌曲信息.网易云音乐歌曲列表是通过iframe展示的,可以借助Selenium获取到iframe的页面元素, 而QQ音乐采用的是 ...
- 手把手教你使用Python抓取QQ音乐数据(第一弹)
[一.项目目标] 获取 QQ 音乐指定歌手单曲排行指定页数的歌曲的歌名.专辑名.播放链接. 由浅入深,层层递进,非常适合刚入门的同学练手. [二.需要的库] 主要涉及的库有:requests.json ...
- 手把手教你使用Python抓取QQ音乐数据(第二弹)
[一.项目目标] 通过Python爬取QQ音乐数据(一)我们实现了获取 QQ 音乐指定歌手单曲排行指定页数的歌曲的歌名.专辑名.播放链接. 此次我们在之前的基础上获取QQ音乐指定歌曲的歌词及前15个精 ...
- python定时器爬取豆瓣音乐Top榜歌名
python定时器爬取豆瓣音乐Top榜歌名 作者:vpoet mail:vpoet_sir@163.com 注:这些小demo都是前段时间为了学python写的,现在贴出来纯粹是为了和大家分享一下 # ...
随机推荐
- 【JavaWeb】JavaScript 基础
JavaScript 基础 事件 事件是指输入设备与页面之间进行交互的响应. 常用的事件: onload 加载完成事件:页面加载完成之后,常用于页面 js 代码初始化操作: onclick 单击事件: ...
- 剑指offer 面试题4:二维数组中的查找
题目描述 在一个二维数组中(每个一维数组的长度相同),每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序.请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数 ...
- Docker学习笔记之查看Docker
命令: 使用history命令查看镜像历史 使用cp命令复制容器中的文件到主机 使用commit命令把修改过的容器创建为镜像 使用diff命令检查容器文件的修改 使用inspect命令查看容器/镜像详 ...
- SDUST数据结构 - chap3 栈和队列
一.判断题: 二.选择题: 三.编程题: 7-1 一元多项式求导: 输入样例: 3 4 -5 2 6 1 -2 0 输出样例: 12 3 -10 1 6 0 代码: #include<bits/ ...
- cmd的终结工具cmder
常用快捷键 win+alt+t 打开任务设置窗口 win+alt+k 打开快捷键设置窗口 自定义屏幕分割窗口快捷键: ctl+shift+s 水平按50%比例分割 ctl+shift+v 垂直按50 ...
- 记录Js动态加载页面.append、html、appendChild、repend添加元素节点不生效以及解决办法
今天再优化blog页面的时候添加了个关注按钮和图片,但是页面上这个按钮和图片时有时无,本来是搞后端的,被这个前端的小问题搞得抓耳挠腮的! 网上各种查询解决方案,把我解决问题的艰辛历程分享出来,希望大家 ...
- 使用line_profiler对python代码性能进行评估优化
性能测试的意义 在做完一个python项目之后,我们经常要考虑对软件的性能进行优化.那么我们需要一个软件优化的思路,首先我们需要明确软件本身代码以及函数的瓶颈,最理想的情况就是有这样一个工具,能够将一 ...
- Windows10下Canvas对象获得屏幕坐标不正确的原因排查与处理
因为Canvas没有直接将画布内容保存为图片的方法,所以很多时候是通过获得Canvas画布的坐标,然后通过截图的方式来将画布内容保存为本地图片. 如何取得Canvas画布的坐标呢,比较简单实用的方式如 ...
- docker mysql 设置忽略大小写
使用docker 安装mysql时 Linux下是默认不忽略大小写,导致操作数据库的时候会报如下错误 为了解决上面的问题,我们在创建MySQL容器的时候就需要初始化配置 lower_case_ta ...
- 前端PDF文件转图片方法
第一步:先下载pdfjs,网址:PDF下载地址,再引入到项目中,我是标签直接引用的 <script src="pdfjs/build/pdf.js"></scri ...