Spark SQL解析查询parquet格式Hive表获取分区字段和查询条件
首先说一下,这里解决的问题应用场景:
sparksql处理Hive表数据时,判断加载的是否是分区表,以及分区表的字段有哪些?再进一步限制查询分区表必须指定分区?
这里涉及到两种情况:select SQL查询和加载Hive表路径的方式。这里仅就"加载Hive表路径的方式"解析分区表字段,在处理时出现的一些问题及解决作出详细说明。
如果大家有类似的需求,笔者建议通过解析Spark SQL logical plan和下面说的这种方式解决方案结合,封装成一个通用的工具。
问题现象
sparksql加载指定Hive分区表路径,生成的DataSet没有分区字段。
如,
sparkSession.read.format("parquet").load(s"${hive_path}"),hive_path为Hive分区表在HDFS上的存储路径。
hive_path的几种指定方式会导致这种情况的发生(test_partition是一个Hive外部分区表,dt是它的分区字段,分区数据有dt为20200101和20200102):
1. hive_path为"/spark/dw/test.db/test_partition/dt=20200101"
2. hive_path为"/spark/dw/test.db/test_partition/*"
因为牵涉到的源码比较多,这里仅以示例的程序中涉及到的源码中的class、object和方法,绘制成xmind图如下,想细心研究的可以参考该图到spark源码中进行分析。
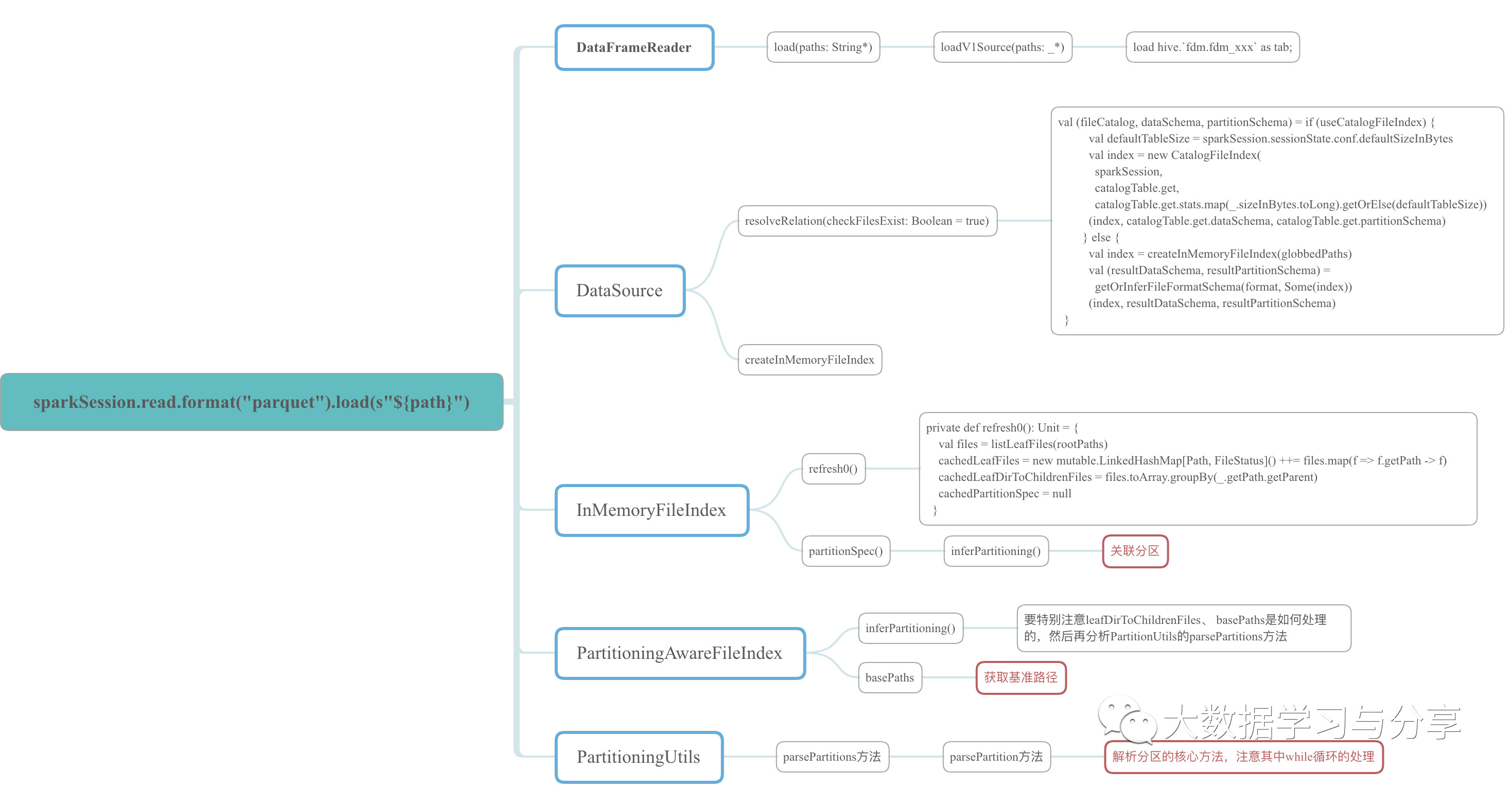
问题分析
我这里主要给出几个源码段,结合上述xmind图理解:
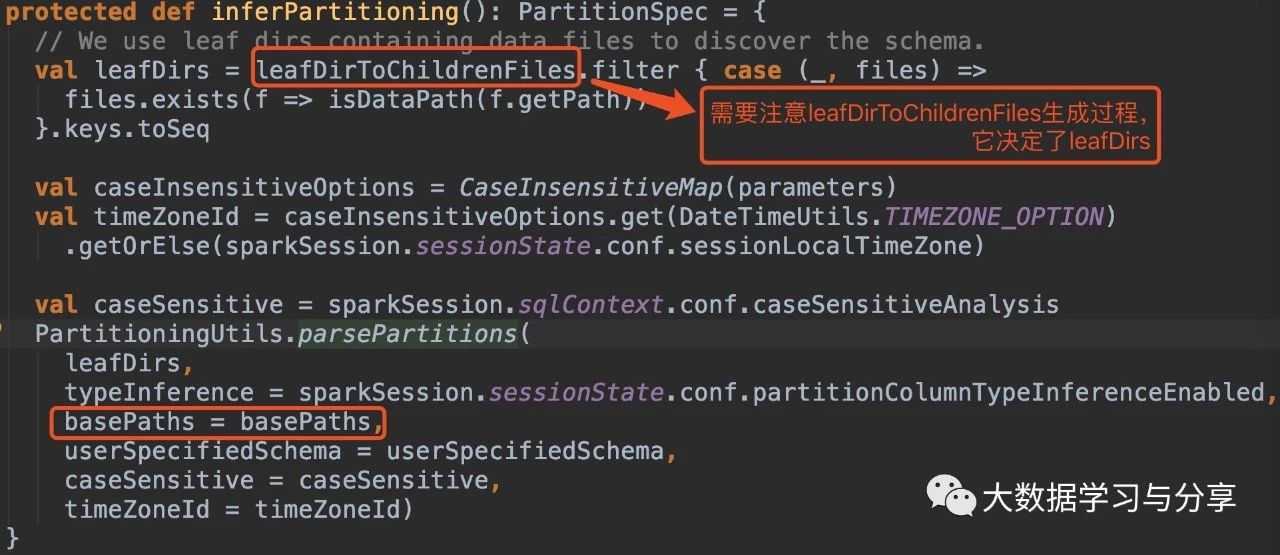
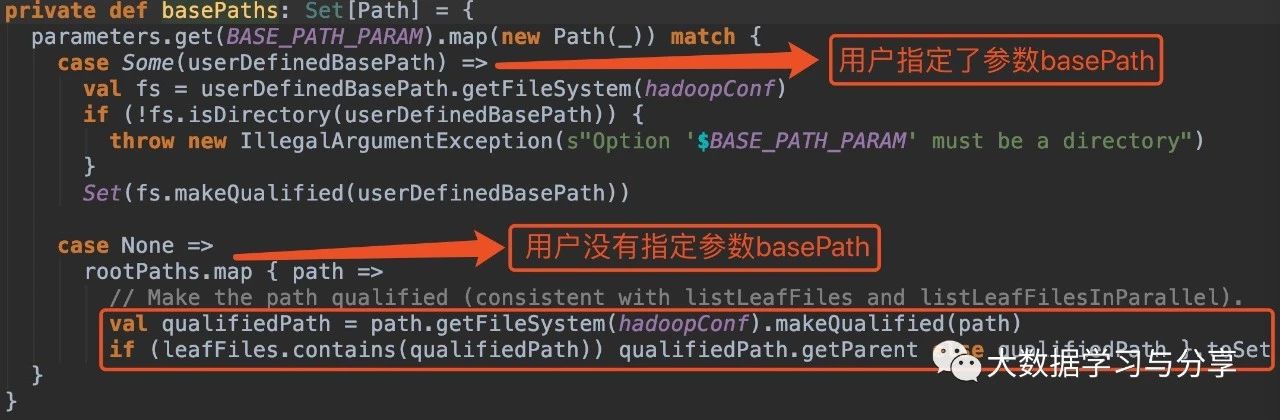
在没有指定参数basePath的情况下:
1. hive_path为/spark/dw/test.db/test_partition/dt=20200101
sparksql底层处理后得到的basePaths: Set(new Path(“/spark/dw/test.db/test_partition/dt=20200101”))【伪代码】
leafDirs: Seq(new Path(“/spark/dw/test.db/test_partition/dt=20200101”))【伪代码】2. hive_path为/spark/dw/test.db/test_partition/*
sparksql底层处理后得到的basePaths: Set(new Path(“/spark/dw/test.db/test_partition/dt=20200101”),new Path(“/spark/dw/test.db/test_partition/dt=20200102”))【伪代码】
leafDirs: Seq(new Path(“/spark/dw/test.db/test_partition/dt=20200101”),new Path(“/spark/dw/test.db/test_partition/dt=20200102”))【伪代码】这两种情况导致源码if(basePaths.contains(currentPath))为true,还没有解析分区就重置变量finished为true跳出循环,因此最终生成的结果也就没有分区字段:
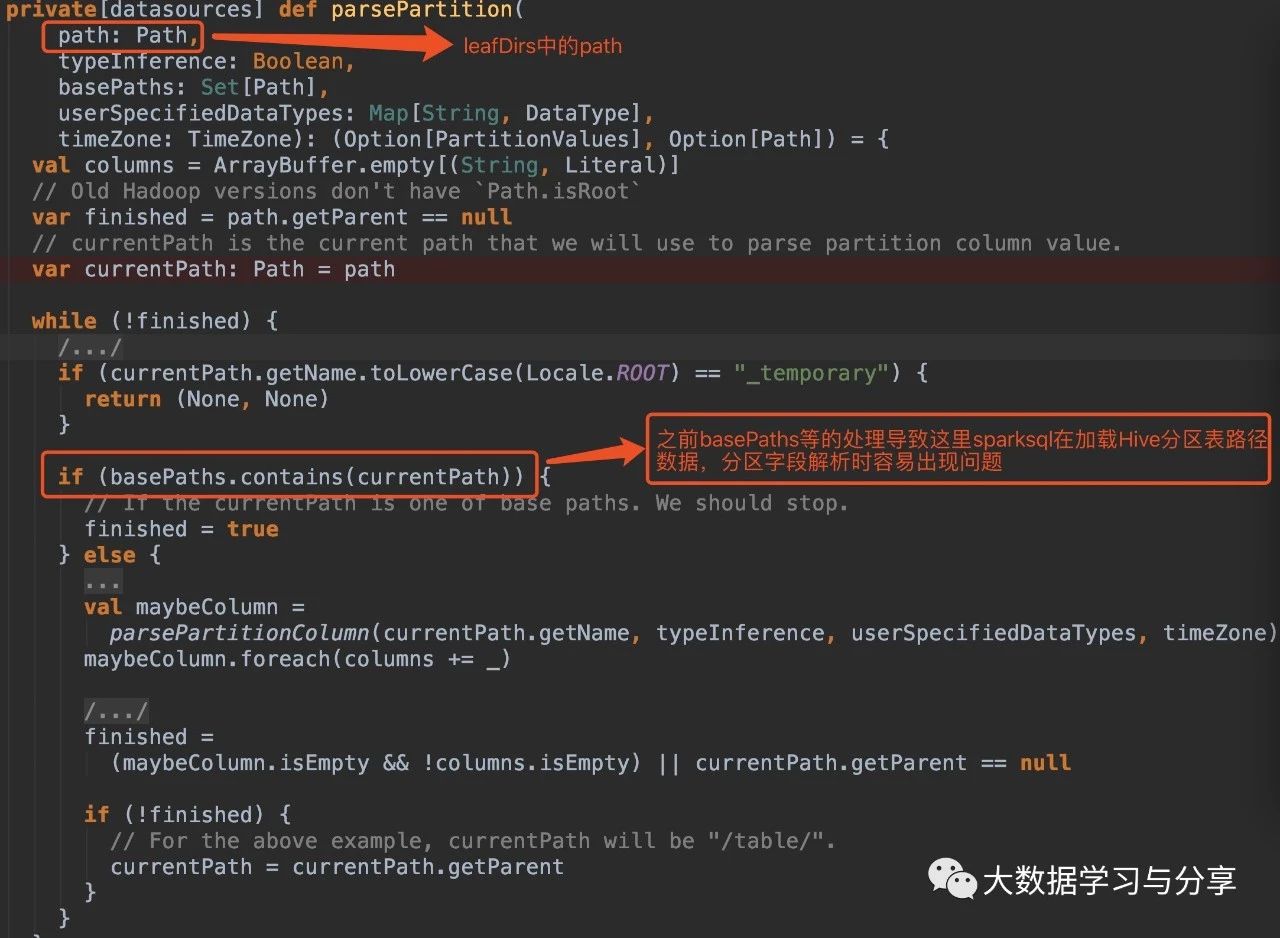
解决方案(亲测有效)
1. 在Spark SQL加载Hive表数据路径时,指定参数basePath,如
sparkSession.read.option("basePath","/spark/dw/test.db/test_partition")
2. 主要重写basePaths方法和parsePartition方法中的处理逻辑,同时需要修改其他涉及的代码。由于涉及需要改写的代码比较多,可以封装成工具
关联文章:
Spark SQL解析查询parquet格式Hive表获取分区字段和查询条件的更多相关文章
- Hive表种map字段的查询取用
建表可以用 map<string,string> 查询时可以按照 aaa[bbb], aaa 是map字段名,bbb是其中的参数名,就可以取到这个参数的值了 当参数名bbb是string时 ...
- Spark访问与HBase关联的Hive表
知识点1:创建关联Hbase的Hive表 知识点2:Spark访问Hive 知识点3:Spark访问与Hbase关联的Hive表 知识点1:创建关联Hbase的Hive表 两种方式创建,内部表和外部表 ...
- 3. Spark SQL解析
3.1 新的起始点SparkSession 在老的版本中,SparkSQL提供两种SQL查询起始点,一个叫SQLContext,用于Spark自己提供的SQL查询,一个叫HiveContext,用于连 ...
- Spark DataFrame vector 类型存储到Hive表
1. 软件版本 软件 版本 Spark 1.6.0 Hive 1.2.1 2. 场景描述 在使用Spark时,有时需要存储DataFrame数据到Hive表中,一般的存储方式如下: // 注册临时表 ...
- 【hive】hive表很大的时候查询报错问题
线上hive使用环境出现了一个奇怪的问题,跑一段时间就报如下错误: FAILED: SemanticException MetaException(message:Exception thrown w ...
- 查找sqlserver数据库中,查询某值所表名和字段名
有时候我们想通过一个值知道这个值来自数据库的哪个表以及哪个字段,通过一个存储过程实现的.只需要传入一个想要查找的值,即可查询出这个值所在的表和字段名. 前提是要将这个存储过程放在所查询的数据库. CR ...
- Oracle 查询库中所有表名、字段名、字段名说明,查询表的数据条数、表名、中文表名、
查询所有表名:select t.table_name from user_tables t;查询所有字段名:select t.column_name from user_col_comments t; ...
- sql server 按月对数据表进行分区
当某张数据表数据量较大时,我们就需要对该表进行分区处理,以下sql语句,会将数据表按月份,分为12个分区表存储数据,废话不多说,直接上脚本: use [SIT_L_TMS] --开启 XP_CMDSH ...
- 【转】Oracle 查询库中所有表名、字段名、表名说明、字段名说明
转自 :http://gis-conquer.blog.sohu.com/170243422.html 查询所有表名:select t.table_name from user_tables t; 查 ...
随机推荐
- twoSum问题的核心思想
Two Sum 系列问题在 LeetCode 上有好几道,这篇文章就挑出有代表性的几道,介绍一下这种问题怎么解决. TwoSum I 这个问题的最基本形式是这样:给你一个数组和一个整数 target, ...
- 什么是SPI
一.什么是SPI SPI ,全称为 Service Provider Interface,是一种服务发现机制.它通过在ClassPath路径下的META-INF/services文件夹查找文件,自动加 ...
- Polyglot Translators: Let's do i18n easier! 一款国际化插件小助手!
在做国际化文本有关的工作时, 是否厌倦了在不同应用或者网页之间频繁地切换进行中文, 繁体, 英文甚至韩文日文的文本翻译工作? 好吧, 我就是受不了频繁在进行文本字符串的转换, 还得跑到百度翻译上面搜索 ...
- maven profile filter 线上线下分开打包配置
maven自动选择不同的配置文件打包profile+filter 1. profile: [要点:] activeByDefault默认激活,不用再mvn命令时指定额外参数: [注意:] 使用非默认的 ...
- 强迫自己学习Jquery 最喜欢的hitch函数
用过dojo的人都知道hitch. 通过绑定一个函数的上下文得到一个新函数,当然还能绑定参数 Jquery里没有这个功能,实在太不方便了. 这是我不喜欢用Jquery的第一原因,第二原因是Jquery ...
- ceph unfound objects 处理
ceph Vol 45 Issue 1 1.unfound objects blocking cluster, need help! Hi, I have a production cluster o ...
- IDEA 使用的一些快捷键记录
1,ctrl+tab 导航当前编辑打开的所有文件,按住Ctrl,使用backspace 可以关闭某个文件 2,ctrl+shift+alt+s 打开项目设置,alt+shift+s 打开所有设置 3, ...
- JWT 实战
上一篇我们讲解了 JWT 的基本原理和结构 你了解JWT吗?,接下来我们具体实战一下! 1. 引入依赖 <!--引入jwt--> <dependency> <groupI ...
- sql bypass waf fuzz python
从freebuf copy过来的,先保存,有空再改 #encoding=utf-8 import requests url = "http://127.0.0.1/index.php?id= ...
- 关于Redis的一些思考
1.从Java语言考虑,已经有ConcurrentHashMap等并发集合类了,与Redis相比,区别于差异在哪? 一直有这么个疑问,今天有搜了很久,很巧,搜到个有同样想法的问答,如下: When p ...