Spark DataFrame vector 类型存储到Hive表
1. 软件版本
| 软件 | 版本 |
|---|---|
| Spark | 1.6.0 |
| Hive | 1.2.1 |
2. 场景描述
在使用Spark时,有时需要存储DataFrame数据到Hive表中,一般的存储方式如下:
// 注册临时表
myDf.registerTempTable("t1")
// 使用SQLContext从临时表创建Hive表
sqlContext.sql("create table h1 as select * from t1")
在DataFrame中存储一般的数据类型,比如Double、Float、String等到Hive表是没有问题的,但是在DataFrame中还有一个数据类型:vector , 如果存储这种类型到Hive表那么会报错,类似:
org.apache.spark.sql.AnalysisException: cannot resolve 'cast(norF as struct<type:tinyint,size:int,indices:array<int>,values:array<double>>)'
due to data type mismatch: cannot cast org.apache.spark.mllib.linalg.VectorUDT@f71b0bce to StructType(StructField(type,ByteType,true), StructField(size,IntegerType,true), StructField(indices,ArrayType(IntegerType,true),true), StructField(values,ArrayType(DoubleType,true),true));
这个错误如果搜索的话,可以找到类似这种结果: Failed to insert VectorUDT to hive table with DataFrameWriter.insertInto(tableName: String)
也即是说暂时使用Spark是不能够直接存储vector类型的DataFrame到Hive表的,那么有没有一种方法可以存储呢?
想到这里,那么在Spark中是有一个工具类VectorAssembler 可以达到相反的目的,即把多个列(也需要要求这些列的类型是一致的)合并成一个vector列。但是并没有相反的工具类,也就是我们的需求。
3. 问题的迂回解决方法
这里提出一个解决方法如下:
假设:
1. DataFrame中数据类型是vector的列中的数据类型都是已知的,比如Double,数值类型;
2. vector列中的具体子列个数也是已知的;
有了上面两个假设就可以通过构造RDD[Row]以及schema的方式来生成新的DataFrame,并且这个新的DataFrame的类型是基本类型,如Double。这样就可以保存到Hive中了。
4. 示例
本例流程如下:
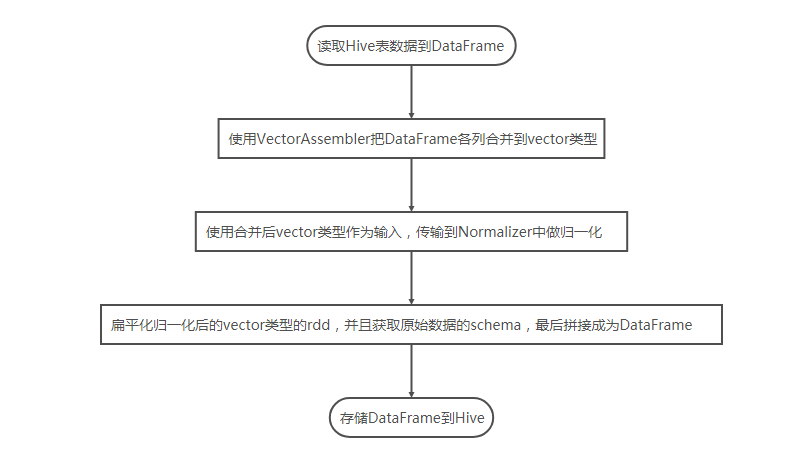
代码如下:
// 1.读取数据
val data = sqlContext.sql("select * from normalize")
读取数据如下:

// 2.构造vector数据
import org.apache.spark.ml.feature.VectorAssembler
val cols = data.schema.fieldNames
val newFeature = "fea"
val asb = new VectorAssembler().setInputCols(cols).setOutputCol(newFeature)
val newDf = asb.transform(data)
newDf.show()

// 3.做归一化
import org.apache.spark.ml.feature.Normalizer
val norFeature ="norF"
val normalizer = new Normalizer().setInputCol(newFeature).setOutputCol(norFeature).setP(1.0)
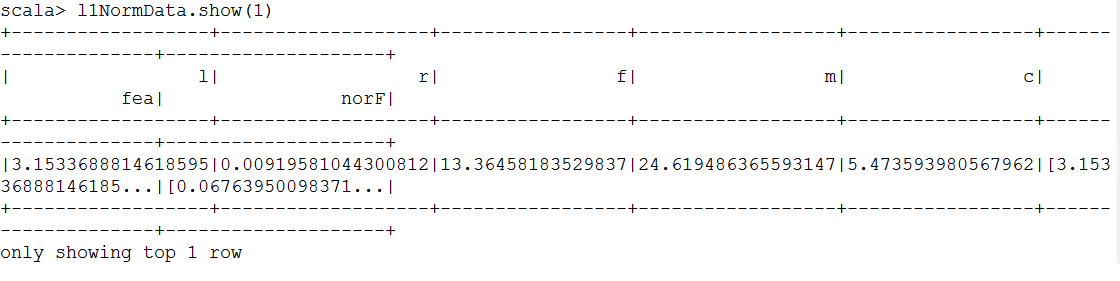
val l1NormData = normalizer.transform(newDf)
l1NormData.show()
// 存储DataFrame vector类型报错
// l1NormData.select(norFeature).registerTempTable("t1")
// sqlContext.sql("create table h2 as select * from t1")
// 4.扁平转换vector到row
import org.apache.spark.sql.Row
val finalRdd= l1NormData.select(norFeature).rdd.map(row => Row.fromSeq(row.getAs[org.apache.spark.mllib.linalg.DenseVector]().toArray))
val finalDf = sqlContext.createDataFrame(finalRdd,data.schema)
finalDf.show()

// 5. 存储到Hive中
finalDf.registerTempTable("t1")
sqlContext.sql("create table h1 as select * from t1")

Spark DataFrame vector 类型存储到Hive表的更多相关文章
- 将DataFrame数据如何写入到Hive表中
1.将DataFrame数据如何写入到Hive表中?2.通过那个API实现创建spark临时表?3.如何将DataFrame数据写入hive指定数据表的分区中? 从spark1.2 到spark1.3 ...
- Spark访问与HBase关联的Hive表
知识点1:创建关联Hbase的Hive表 知识点2:Spark访问Hive 知识点3:Spark访问与Hbase关联的Hive表 知识点1:创建关联Hbase的Hive表 两种方式创建,内部表和外部表 ...
- Spark SQL解析查询parquet格式Hive表获取分区字段和查询条件
首先说一下,这里解决的问题应用场景: sparksql处理Hive表数据时,判断加载的是否是分区表,以及分区表的字段有哪些?再进一步限制查询分区表必须指定分区? 这里涉及到两种情况:select SQ ...
- Spark访问Hive表
知识点1:Spark访问HIVE上面的数据 配置注意点:. 1.拷贝mysql-connector-java-5.1.38-bin.jar等相关的jar包到你${spark_home}/lib中(sp ...
- spark+hcatalog操作hive表及其数据
package iie.hadoop.hcatalog.spark; import iie.udps.common.hcatalog.SerHCatInputFormat; import iie.ud ...
- Spark 读写hive 表
spark 读写hive表主要是通过sparkssSession 读表的时候,很简单,直接像写sql一样sparkSession.sql("select * from xx") 就 ...
- spark相关介绍-提取hive表(一)
本文环境说明 centos服务器 jupyter的scala核spylon-kernel spark-2.4.0 scala-2.11.12 hadoop-2.6.0 本文主要内容 spark读取hi ...
- 大数据学习day25------spark08-----1. 读取数据库的形式创建DataFrame 2. Parquet格式的数据源 3. Orc格式的数据源 4.spark_sql整合hive 5.在IDEA中编写spark程序(用来操作hive) 6. SQL风格和DSL风格以及RDD的形式计算连续登陆三天的用户
1. 读取数据库的形式创建DataFrame DataFrameFromJDBC object DataFrameFromJDBC { def main(args: Array[String]): U ...
- 使用spark对hive表中的多列数据判重
本文处理的场景如下,hive表中的数据,对其中的多列进行判重deduplicate. 1.先解决依赖,spark相关的所有包,pom.xml spark-hive是我们进行hive表spark处理的关 ...
随机推荐
- OpenCV——轮廓面积及长度计算
计算轮廓面积: double contourArea(InputArray contour, bool oriented=false ) InputArray contour:输入的点,一般是图像的轮 ...
- linux禁止IPv6
1. 禁止加载IPv6模块 # echo "install ipv6 /bin/true" > /etc/modprobe.d/disable-ipv6.conf 每当系统需 ...
- liunx trac 插件使用之GanttCalendarPlugin
http://trac-hacks.org/wiki/GanttCalendarPlugin官网上的说明很清楚,处理做几点提示,以做记录. 1.我的Trac版本是1.0.1 我使用了'B' Metho ...
- shell截取字符串的一些简单方法
一.使用${} 1.${var##*/}该命令的作用是去掉变量var从左边算起的最后一个'/'字符及其左边的内容,返回从左边算起的最后一个'/'(不含该字符)的右边的内容.使用例子及结果如下:
- 【Mybatis】Mybatis元素生命周期
一.SqlSessionFactoryBuilder SqlSessionFactoryBuilder是利用XML或者Java编码获得资源来构建SqlSessionFactory的,通过它可以构建多个 ...
- 小米2s线刷出现remote: partition table doesn't exist
=================问题============ 小米2s线刷出现remote: partition table doesn't exist =================解决方案= ...
- VMware ESXI5.5 Memories limits resolved soluation.
在使用VMware ESXI5.5 的时候提示内存限制了,在网上找的了解决方案: 如下文: 1. Boot from VMware ESXi 5.5; 2. wait "Welcome to ...
- XmlSerializer的GenerateTempAssembly性能问题例外
XmlSerializer的两个构造函数不会出现每次构造都创建TempAssembly的性能问题,其内部做了缓存. public XmlSerializer(Type type) public Xml ...
- .NET中字符串split的C++实现
void CustomVersion::split(const string &s, char delim, vector<string> &elems){ istring ...
- linux系统下网络主-备份策略之网卡bond技术
操作系统:CentOS Linux release 7.1.1503 (Core) 网卡适配器: eno1.eno2 bonding类型:mode=1 (active-backup),主-备份策略 网 ...