Tensorflow学习笔记No.9
模型的保存与恢复
介绍一些常见的模型保存与恢复方法,以及如何使用回调函数保存模型。
1.保存完整模型
model.save()方法可以保存完整的模型,包括模型的架构、模型的权重以及优化器。
model.save()的参数为保存路径以及文件名。
首先我们构建一个简单的Sequential模型,使用fishion_mnist数据集进行训练,得到一个训练后的模型。
1 import tensorflow as tf
2 import numpy as np
3
4 (train_image, train_label), (test_image, test_label) = tf.keras.datasets.fashion_mnist.load_data()
5
6 train_image = np.expand_dims(train_image, -1)
7 test_image = np.expand_dims(test_image, -1)
8
9 model = tf.keras.Sequential()
10 model.add(tf.keras.layers.Conv2D(32, [3, 3], input_shape = (28, 28, 1), activation = 'relu'))
11 model.add(tf.keras.layers.Conv2D(64, [3, 3], activation = 'relu'))
12 model.add(tf.keras.layers.GlobalAveragePooling2D())
13 model.add(tf.keras.layers.Dense(64, activation = 'relu'))
14 model.add(tf.keras.layers.Dense(10, activation = 'softmax'))
15
16 model.compile(optimizer = 'adam',
17 loss = 'sparse_categorical_crossentropy',
18 metrics = ['acc'])
19
20 history = model.fit(train_image, train_label,
21 epochs = 10,
22 validation_data = (test_image, test_label))
使用model.summary()查看当前模型结构:
1 model.summary()
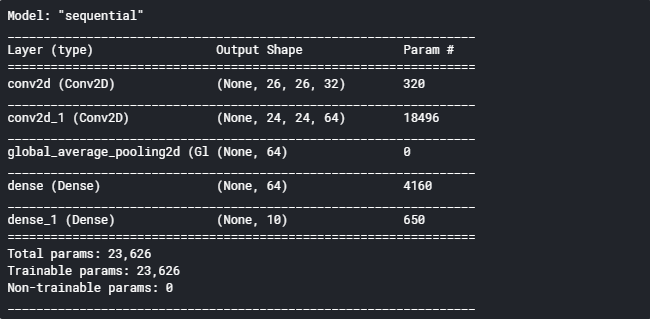
训练完成后我们使用model.evaluate()方法对测试集进行评估。
1 model.evaluate(test_image, test_label)
正确率如下图所示:

然后我们使用model.save()方法保存完整模型。
1 model.save('model_1.h5')
保存后我们会得到一个名为model_1.h5的文件,这个文件就是保存好的模型。
保存好的模型会放到指定位置。

我们可以使用tf.keras.models.load_model()方法来导入我们保存好的模型,参数为已保存模型的储存位置以及文件名。
1 new_model = tf.keras.models.load_model('model_1.h5')
我们使用.summary()方法查看一下模型结构是否与之前相同。
1 new_model.summary()
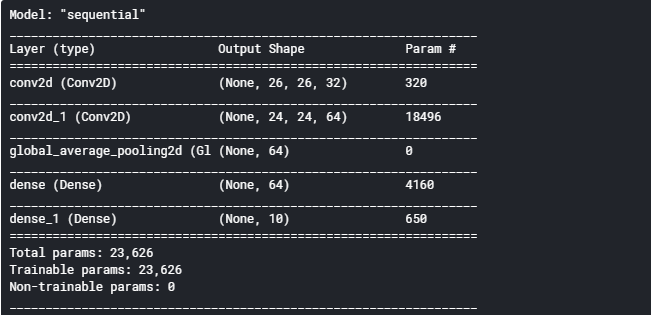
可以发现模型结构是完全一致的。
然后我们使用.evaluate()方法对测试集进行评估,看一下模型权重是否被保存。
1 new_model.evaluate(test_image, test_label)

可以发现,loss值与之前完全相同。
注意:这里acc值发生了很严重的变化,目前不知道我还是什么原因导致的,但这不代表我们保存的模型或者是权重出现了问题,使用.predict()方法依然可以正常对数据进行分类预测,这是我使用.predict()方法预测后与原数据一一比对后确认过的,可能是出现了一个小bug,知道原因的小伙伴可以评论区回复我。
重申:模型是已经正常保存了的,是可以正常使用的,大家无需担心,loss值足够证明我们的模型是正常保存的。
2.仅保存模型结构
有时候我们可能不需要保存模型的权重,而只想保存模型的架构。
这时可以使用model.to_jison()来获取模型架构。
1 json = model.to_json()
json中保存了模型架构的完整信息。
我们可以使用python的文件操作方法将它写入到磁盘上,使用时再从磁盘上读入即可,这里不详细说明了,大家自行百度即可。
使用tf.keras.models.model_from_jsom()来恢复模型,参数为我们之前保存模型信息的变量json。
1 new_model = tf.keras.models.model_from_json(json)
同样,我们查看模型结构并对模型进行评估。
1 new_model.summary()

1 new_model.compile(optimizer = 'adam',
2 loss = 'sparse_categorical_crossentropy',
3 metrics = ['acc'])
4
5 new_model.evaluate(test_image, test_label)
注意,由于我们没有保存优化器,所以要先对模型添加一个优化器再进行评估。

可以发现loss值非常的大,也就说明的模型没有被训练过,模型中的参数都是随机产生的。
3.仅保存模型权重
同样的,我们也可以仅保存模型权重。
权重的保存有两种方法,可以像上面保存模型结构一样使用model.get_weights()把模型结构读入到变量中再进行保存,也可以使用keras提供的方法直接保存到磁盘上。
这里主要介绍第二种(主要是第一种用处不大)。
使用model.save_weights()方法进行保存,参数为保存路径以及文件名。
1 model.save_weights('weights_1.h5')
同样,我们会得到一个对应的文件。
然后使用.load_weigths()方法可以载入权重,参数为路径及文件名。
1 new_model.load_weights('weights_1.h5')
对测试集进行评估查看是否被正常载入。
1 new_model.evaluate(test_image, test_label)

loss值与之前相同,说明权重被正常载入了。
注意,保存权重也不会保存优化器,这里不用重定义优化器是因为上面已经给new_model这个对象定义过优化器了。
4.使用回调函数保存模型
我觉得这是最实用也是最好的模型保存方法。
首先定义一个回调函数监测训练过程并保存模型。
使用tf.keras.callbacks.ModelCheckpoint()来定义这样一个回调函数。
它的主要参数为:
filepath:储存位置。
moinitor = 'val_loss':监视的变量。
verboss = 0:是否显示详细信息。
save_best_only = False:为True则会保存loss最低的或者acc最高的。
save_weihts_only = False:是否只保存权重,为False会保存整个模型。
1 checkpoint = tf.keras.callbacks.ModelCheckpoint('modelcp',
2 save_weights_only = True,
3 save_best_only = True,
4 verbose = 1)
然后我们构建模型训练一下试试。
1 new_model = tf.keras.models.model_from_json(json)
2
3 new_model.compile(optimizer = 'adam',
4 loss = 'sparse_categorical_crossentropy',
5 metrics = ['acc'])
6
7 history = new_model.fit(train_image, train_label,
8 epochs = 5,
9 validation_data = (test_image, test_label),
10 callbacks = [checkpoint])
要在.fit()中加入callbacks参数调用回调函数。
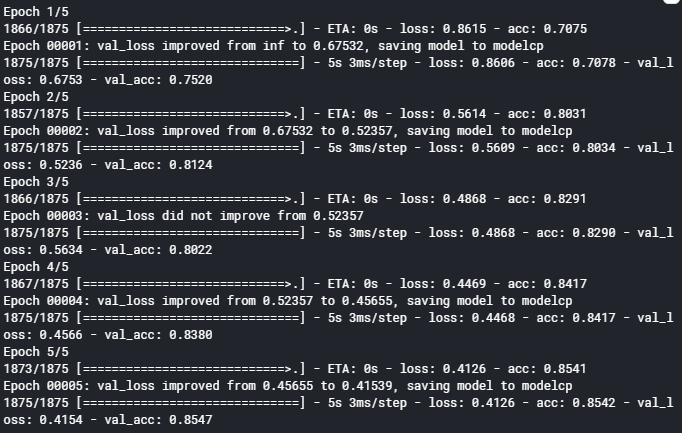
可以发现我们的模型信息被保存了,同时多出来三个保存好的文件。
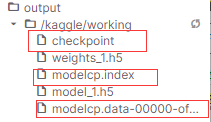
同样使用.load_weights()来载入权重,并进行评估。
1 new_model = tf.keras.models.model_from_json(json)
2
3 new_model.compile(optimizer = 'adam',
4 loss = 'sparse_categorical_crossentropy',
5 metrics = ['acc'])
6
7 new_model.load_weights('modelcp')
8
9 new_model.evaluate(test_image, test_label)
得到结果:

与训练时最后保存的结果相同。
关于模型的保存方法就介绍到这里了,后续会更新更多内容哦!o(* ̄▽ ̄*)o
Tensorflow学习笔记No.9的更多相关文章
- Tensorflow学习笔记2:About Session, Graph, Operation and Tensor
简介 上一篇笔记:Tensorflow学习笔记1:Get Started 我们谈到Tensorflow是基于图(Graph)的计算系统.而图的节点则是由操作(Operation)来构成的,而图的各个节 ...
- Tensorflow学习笔记2019.01.22
tensorflow学习笔记2 edit by Strangewx 2019.01.04 4.1 机器学习基础 4.1.1 一般结构: 初始化模型参数:通常随机赋值,简单模型赋值0 训练数据:一般打乱 ...
- Tensorflow学习笔记2019.01.03
tensorflow学习笔记: 3.2 Tensorflow中定义数据流图 张量知识矩阵的一个超集. 超集:如果一个集合S2中的每一个元素都在集合S1中,且集合S1中可能包含S2中没有的元素,则集合S ...
- TensorFlow学习笔记之--[compute_gradients和apply_gradients原理浅析]
I optimizer.minimize(loss, var_list) 我们都知道,TensorFlow为我们提供了丰富的优化函数,例如GradientDescentOptimizer.这个方法会自 ...
- 深度学习-tensorflow学习笔记(1)-MNIST手写字体识别预备知识
深度学习-tensorflow学习笔记(1)-MNIST手写字体识别预备知识 在tf第一个例子的时候需要很多预备知识. tf基本知识 香农熵 交叉熵代价函数cross-entropy 卷积神经网络 s ...
- 深度学习-tensorflow学习笔记(2)-MNIST手写字体识别
深度学习-tensorflow学习笔记(2)-MNIST手写字体识别超级详细版 这是tf入门的第一个例子.minst应该是内置的数据集. 前置知识在学习笔记(1)里面讲过了 这里直接上代码 # -*- ...
- tensorflow学习笔记(4)-学习率
tensorflow学习笔记(4)-学习率 首先学习率如下图 所以在实际运用中我们会使用指数衰减的学习率 在tf中有这样一个函数 tf.train.exponential_decay(learning ...
- tensorflow学习笔记(3)前置数学知识
tensorflow学习笔记(3)前置数学知识 首先是神经元的模型 接下来是激励函数 神经网络的复杂度计算 层数:隐藏层+输出层 总参数=总的w+b 下图为2层 如下图 w为3*4+4个 b为4* ...
- tensorflow学习笔记(2)-反向传播
tensorflow学习笔记(2)-反向传播 反向传播是为了训练模型参数,在所有参数上使用梯度下降,让NN模型在的损失函数最小 损失函数:学过机器学习logistic回归都知道损失函数-就是预测值和真 ...
- tensorflow学习笔记(1)-基本语法和前向传播
tensorflow学习笔记(1) (1)tf中的图 图中就是一个计算图,一个计算过程. 图中的constant是个常量 计 ...
随机推荐
- IDEA 2020.2 最新激活教程,有效期到2089年!
这段时间众多粉丝私信说需要IDEA 2020.2 最新激活教程,于是!他来了他带着最新激活教程来了. 注意: 本教程适用于 JetBrains 全系列产品 IDEA 2020.2 以下所有版本,请放心 ...
- 微信小程序 A~Z城市选择器js文件
微信小程序城市选择 [a~z] 的所有城市选择 city.js a~z排序的城市数据 addressChoose.js 其他js文件可引用 city.js /** * Created by yvded ...
- HTTP 的前世今生,那些不为人知的秘密
每个时代,都不会亏待会学习的人. 大家好,我是 yes. HTTP 协议在当今的互联网可谓是随处可见,一直默默的在背后支持着网络世界的运行,对于我们程序员来说 HTTP 更是熟悉不过. 平日里我们都说 ...
- ViewBinding的简单使用
Android自家的,又可以省去findviewbyid(),而且Butterknife上大神都已经推荐使用的,还有什么理由不去改写呢 build.gradle 开启viewBinding功能 and ...
- centos7卸载mariadb安装mysql
卸载mariadb 1. 当前安装列表 rpm -qa | grep mariadb 2.卸载 rpm -e --nodeps mariadb-libs-5.5.56-2.el7.x86_64 3 ...
- JavaScript判断字符串中出现次数最多的字符,并统计其次数
要求: 输出一个给定字符串``中出现次数最多的字符,并统计其次数. 实现思路: 利用charA()遍历这个字符串 把每个字符都存储给对象,如果对象没有该属性,就先幅值为1,如果存在了就+1 遍历对象, ...
- Centos7安装MySQL8.0(RPM方式)
人生处处皆学问,工作也是如此!过去不止一次在Linux上安装MySQL,可以说轻车熟路,但是写篇文章总结一下,发现有很多细节值得学习! 安装包选择 为什么用rpm? 在Linux系列上安装软件一般有源 ...
- Axure实现vcg官网首页原型图
W240第二天第三天 Axure的简单使用: 作业实现:vcg官网首页原型图 帮助文档基础篇:原型图基础之axure线框图设计 导航栏设计: 添加通用母版header 导航栏设计注意: 鼠标移动到下面 ...
- shell-变量的字串应用技术
1. 变量子串的常用操作 常用操作如下表: 依次举例说明: 定义aa变量,内容为"I am scajy" [root@1-241 script]# aa="I am sc ...
- C#数据结构-静态链表
对于双向链表中的节点,都包括一个向前.向后的属性器用于指向前后两个节点,对于引用类型,对象存储的是指向内存片段的内存指针,那么我们可以将其简化看作向前向后的两个指针. 现在我们将引用类型替换为值类型i ...