scrapy异步的爬虫框架简单的使用
scrapy异步的爬虫框架
异步的爬虫框架
高性能的数据解析,持久化存储,全栈数据的爬取,中间件,分布式
框架:就是一个集成好了各种功能且具有很强通用性的一个项目模板。
环境安装:
Linux:
pip3 install scrapy
Windows:
1. pip3 install wheel
2. 下载twisted http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
3. 进入下载目录,执行 pip3 install Twisted‑17.1.0‑cp35‑cp35m‑win_amd64.whl
4. pip3 install pywin32
5. pip3 install scrapy
基本使用
新建一个工程:
前提需要将
Twisted‑17.1.0‑cp35‑cp35m‑win_amd64.whl这个文件放在项目目录下# 在终端中执行下面这个命令
scrapy startporject + “项目名”
- settings.py:当前工程的配置文件
- spiders:爬虫包,必须要存放一个或者多个爬虫文件(.py)
进入项目
# 在终端中执行
cd + 项目名
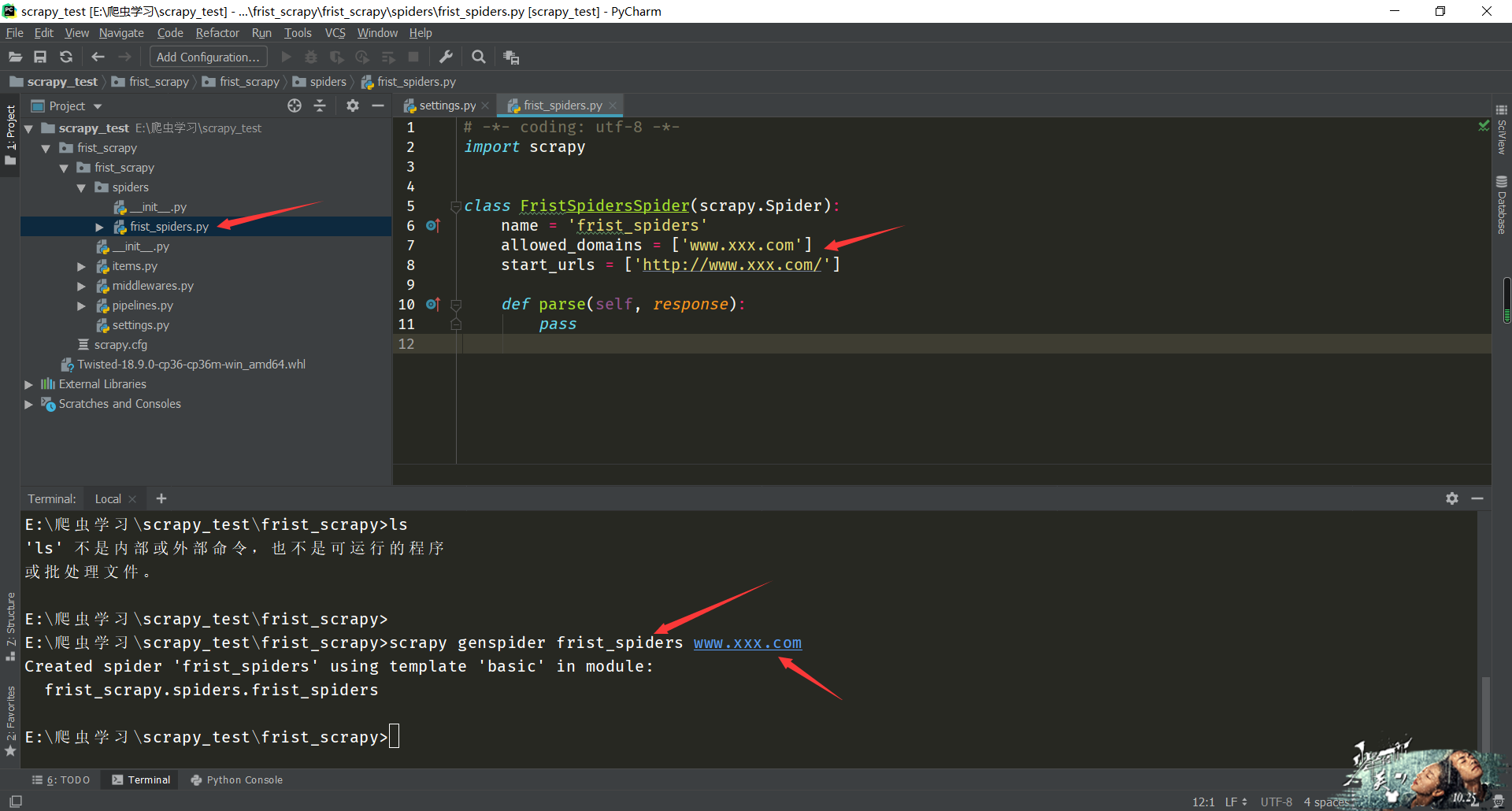
创建一个爬虫文件:
# 在终端中执行:
scrapy genspider spiderName www.xxx.com # 命令解析:
scrapy genspider 爬虫文件名 url
# 这个url是必写的,不写无法创建文件,可以随意些,最后在文件中修改
执行工程:
# 在终端中执行下面的命令:
scrapy crawl spiderName # 执行命令scrapy crawl 加爬虫文件名
在
sttings文件中需要配置的:settings.py: - 不遵从robots协议
如果选择不遵循robots协议的就修改文件中的
ROBOTSTXT_OBEY = False # 将True改为False - UA伪装
将UA伪装的数据加载文件中 - 指定日志输出的类型:
将 LOG_LEVEL = 'ERROR' 添加到配置文件中
爬虫文件中:
# -*- coding: utf-8 -*-
import scrapy class SecondSpidersSpider(scrapy.Spider):
name = 'second_spiders'
#允许的域名
allowed_domains = ['www.123.com'] #起始的url列表:列表元素只可以是url
#作用:列表元素表示的url就会被进行请求发送
start_urls = ['http://duanziwang.com/category/%E7%BB%8F%E5%85%B8%E6%AE%B5%E5%AD%90/'] def parse(self, response):
all_data = []
article_list = response.xpath('/html/body/section/div/div/main/article')
for article in article_list:
# xpath在进行数据提取时,返回的不再是字符串而是一个Selector对象,想要的数据被包含在了该对象的data参数中 title = article.xpath('./div[1]/h1/a/text()').extract_first()
content = article.xpath('./div[2]//text()').extract()
content = ''.join(content)
dic = {
'title': title,
'content': content
}
all_data.append(dic)
return all_data # 将解析到的数据进行了返回
数据解析:
- 1.response.xpath('xpath表达式')
- 2.scrapy中的xpath解析,在进行数据提取的时候,xpath方法返回的列表中存储的不再是字符串,
而是存储的Selector对象,相关的字符串数据是存储在Selector对象的data参数中,我们必须使用
extract()/extract_first()进行字符串数据的提取 - extract():可以作用到列表中的每一个列表元素中,返回的依然是一个列表
- extract_first():只可以作用到列表中的第一个列表元素中,返回的是字符串
持久化存储
- 基于终端指令的持久化存储
- 只可以将parse方法的返回值存储到指定后缀的文本文件中。
- scrapy crawl spiderName -o ./duanzi.csv
- 基于管道的持久化存储
- 基于终端指令的持久化存储
scrapy异步的爬虫框架简单的使用的更多相关文章
- 使用Scrapy爬虫框架简单爬取图片并保存本地(妹子图)
初学Scrapy,实现爬取网络图片并保存本地功能 一.先看最终效果 保存在F:\pics文件夹下 二.安装scrapy 1.python的安装就不说了,我用的python2.7,执行命令pip ins ...
- 一篇文章教会你理解Scrapy网络爬虫框架的工作原理和数据采集过程
今天小编给大家详细的讲解一下Scrapy爬虫框架,希望对大家的学习有帮助. 1.Scrapy爬虫框架 Scrapy是一个使用Python编程语言编写的爬虫框架,任何人都可以根据自己的需求进行修改,并且 ...
- python网络爬虫(14)使用Scrapy搭建爬虫框架
目的意义 爬虫框架也许能简化工作量,提高效率等.scrapy是一款方便好用,拓展方便的框架. 本文将使用scrapy框架,示例爬取自己博客中的文章内容. 说明 学习和模仿来源:https://book ...
- 『Scrapy』爬虫框架入门
框架结构 引擎:处于中央位置协调工作的模块 spiders:生成需求url直接处理响应的单元 调度器:生成url队列(包括去重等) 下载器:直接和互联网打交道的单元 管道:持久化存储的单元 框架安装 ...
- Scrapy网络爬虫框架的开发使用
1.安装 2.使用scrapy startproject project_name 命令创建scrapy项目 如图: 3.根据提示使用scrapy genspider spider_name dom ...
- 网络爬虫框架Scrapy简介
作者: 黄进(QQ:7149101) 一. 网络爬虫 网络爬虫(又被称为网页蜘蛛,网络机器人),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本:它是一个自动提取网页的程序,它为搜索引擎从万维 ...
- [原创]一款基于Reactor线程模型的java网络爬虫框架
AJSprider 概述 AJSprider是笔者基于Reactor线程模式+Jsoup+HttpClient封装的一款轻量级java多线程网络爬虫框架,简单上手,小白也能玩爬虫, 使用本框架,只需要 ...
- Python之Scrapy爬虫框架安装及简单使用
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提 ...
- 教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http://www.xiaohuar.com/,让你体验爬取校花的成就感. Scr ...
随机推荐
- 工具-效率工具-XMIND8破解(99.1.3)
@ 目录 1.下载 2.修改hosts文件 3.修改配置文件 4.填入序列号 5.破解完成 关于作者 1.下载 1.点击进入官方网站下载 2.下载破解包 网址:点击进入网盘地址 密码:domd 2.修 ...
- 同一个UITextField 根据不同状态下弹出不同类型键盘遇到的坑
一,需求:有多个选项按钮,点击不同的按钮,textfield内容需求不同弹出对应需求的键盘类型. 二,问题:1.刚开始在按钮状态改变后设置 self.textField.keyboardType属性完 ...
- 使用aspnet_compiler对web程序进行预编译
前言 本例使用的是asp.net中的webform项目,使用.net框架为.net3.5 操作步骤 正常的web项目发布步骤 发布方法:文件系统 目标位置:发布后的项目文件的路径,可自定义. 打开wi ...
- MVC中Autofac的使用
参考博文 https://www.cnblogs.com/liupeng/p/4806184.html https://blog.csdn.net/qq_37214567/article/detail ...
- php + redis 实现关注功能
产品价值 1: 关注功能 2: 功能分析之"关注"功能 3: 平平无奇的「关注」功能,背后有4点重大价值 应用场景 在做PC或者APP端时,掺杂点社交概念就有关注和粉丝功能; 数据 ...
- vue-element-admin项目核心总结
1.搭建项目 按照官方文档把整个项目下载下来,安装依赖包npm install, 然后npm run dev 启动项目. 2.项目自定义优化 删除不要的文件,启动项目登录后,发现里面有很多页面,对我们 ...
- CentOS安装TensorFlow
1.升级python 系统自带的python是2.6,不能用,升级到2.7,方法见:http://www.cnblogs.com/stAr-1/p/9055980.html 2.升级python带来的 ...
- Python 爬虫系列
爬虫简介 网络爬虫 爬虫指在使用程序模拟浏览器向服务端发出网络请求,以便获取服务端返回的内容. 但这些内容可能涉及到一些机密信息,所以爬虫领域目前来讲是属于灰色领域,切勿违法犯罪. 爬虫本身作为一门技 ...
- 如何解决git创建密匙时报错Too many arguments
如题:git创建密匙时报错Too many arguments. 前几天我遇见了一个问题,git需要重新创建密匙,运行命令ssh-keygen -t rsa -b 4096 -C " you ...
- Vue利用v-for渲染时表单信息出不来
今天在写项目时,Controller的值已经传入到html,但是利用vue进行渲染的时候就是出不来, 原因如下: 注意,in 之前的空格.