『Scrapy』爬虫框架入门
框架结构
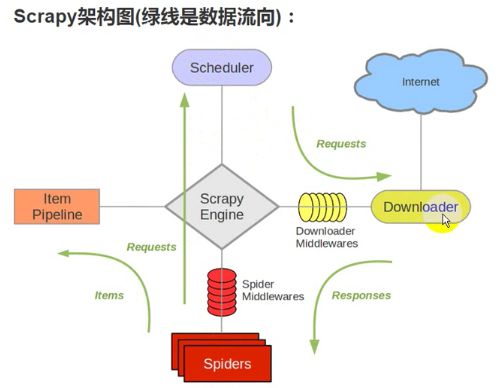
引擎:处于中央位置协调工作的模块
spiders:生成需求url直接处理响应的单元
调度器:生成url队列(包括去重等)
下载器:直接和互联网打交道的单元
管道:持久化存储的单元


框架安装
一般都会推荐pip,但实际上我是用pip就是没安装成功,推荐anaconda,使用conda install scarpy来安装。
scarpy需要使用命令行,由于我是使用win,所以还需要把scarpy添加到path中,下载好的scarpy放在anaconda的包目录下,找到并添加。
框架入门

创建项目
在开始爬取之前,您必须创建一个新的Scrapy项目。 进入您打算存储代码的目录中,运行下列命令:
scrapy startproject tutorial
该命令将会创建包含下列内容的 tutorial 目录,这个目录会创建在当前cmd的工作目录下:
tutorial/
scrapy.cfg
tutorial/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
这些文件分别是:
scrapy.cfg: 项目的配置文件tutorial/: 该项目的python模块。之后您将在此加入代码。tutorial/items.py: 项目中的item文件.tutorial/pipelines.py: 项目中的pipelines文件.tutorial/settings.py: 项目的设置文件.tutorial/spiders/: 放置spider代码的目录.
实际上这算也是一个项目,可以使用pycharm加载。
编写爬虫
Spider是用户编写用于从单个网站(或者一些网站)爬取数据的类。
为了创建一个Spider,您必须继承 scrapy.Spider 类, 且定义以下三个属性:
name: 用于区别Spider。 该名字必须是唯一的,您不可以为不同的Spider设定相同的名字。start_urls: 包含了Spider在启动时进行爬取的url列表。 因此,第一个被获取到的页面将是其中之一。 后续的URL则从初始的URL获取到的数据中提取parse()是spider的一个方法。 被调用时,每个初始URL完成下载后生成的Response对象将会作为唯一的参数传递给该函数。 该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的Request对象。allowed_domains:域范围,非此域内url不予爬取。
spider文件要保存在Spider目录下,文件名和类名都可以随便取,但是name属性是唯一的,调用时用的也是name属性。
import scrapy class DmozSpider(scrapy.Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"
] def parse(self, response):
filename = response.url.split("/")[-2]
with open(filename, 'wb') as f:
f.write(response.body)
开始爬取
scrapy crawl dmoz
输出类似下面:
2014-01-23 18:13:07-0400 [scrapy] INFO: Scrapy started (bot: tutorial)
2014-01-23 18:13:07-0400 [scrapy] INFO: Optional features available: ...
2014-01-23 18:13:07-0400 [scrapy] INFO: Overridden settings: {}
2014-01-23 18:13:07-0400 [scrapy] INFO: Enabled extensions: ...
2014-01-23 18:13:07-0400 [scrapy] INFO: Enabled downloader middlewares: ...
2014-01-23 18:13:07-0400 [scrapy] INFO: Enabled spider middlewares: ...
2014-01-23 18:13:07-0400 [scrapy] INFO: Enabled item pipelines: ...
2014-01-23 18:13:07-0400 [dmoz] INFO: Spider opened
2014-01-23 18:13:08-0400 [dmoz] DEBUG: Crawled (200) <GET http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/> (referer: None)
2014-01-23 18:13:09-0400 [dmoz] DEBUG: Crawled (200) <GET http://www.dmoz.org/Computers/Programming/Languages/Python/Books/> (referer: None)
2014-01-23 18:13:09-0400 [dmoz] INFO: Closing spider (finished)
查看包含 [dmoz] 的输出,可以看到输出的log中包含定义在 start_urls 的初始URL,并且与spider中是一一对应的。在log中可以看到其没有指向其他页面( (referer:None) )。
回顾一下过程
Scrapy为Spider的 start_urls 属性中的每个URL创建了 scrapy.Request 对象,并将 parse 方法作为回调函数(callback)赋值给了Request。
Request对象经过调度,执行生成 scrapy.http.Response 对象并送回给spider parse() 方法。
『Scrapy』爬虫框架入门的更多相关文章
- 『Golang』Martini框架入门
本文介绍golang中的优秀web开发框架martini! 序 Martini框架是使用Go语言作为开发语言的一个强力的快速构建模块化web应用与服务的开发框架.Martini是一个专门用来处理Web ...
- 易车网实战+【保姆级】:Feapder爬虫框架入门教程
今天辰哥带大家来看看一个爬虫框架:Feapder,看完本文之后,别再说你不会Feapder了.本文辰哥将带你了解什么是Feapder?.如何去创建一个Feapder入门项目(实战:采集易车网轿车数据) ...
- scrapy异步的爬虫框架简单的使用
scrapy异步的爬虫框架 异步的爬虫框架 高性能的数据解析,持久化存储,全栈数据的爬取,中间件,分布式 框架:就是一个集成好了各种功能且具有很强通用性的一个项目模板. 环境安装: Linux: pi ...
- 【python】Scrapy爬虫框架入门
说明: 本文主要学习Scrapy框架入门,介绍如何使用Scrapy框架爬取页面信息. 项目案例:爬取腾讯招聘页面 https://hr.tencent.com/position.php?&st ...
- [Python] Scrapy爬虫框架入门
说明: 本文主要学习Scrapy框架入门,介绍如何使用Scrapy框架爬取页面信息. 项目案例:爬取腾讯招聘页面 https://hr.tencent.com/position.php?&st ...
- scrapy爬虫框架入门教程
scrapy安装请参考:安装指南. 我们将使用开放目录项目(dmoz)作为抓取的例子. 这篇入门教程将引导你完成如下任务: 创建一个新的Scrapy项目 定义提取的Item 写一个Spider用来爬行 ...
- 一篇文章教会你理解Scrapy网络爬虫框架的工作原理和数据采集过程
今天小编给大家详细的讲解一下Scrapy爬虫框架,希望对大家的学习有帮助. 1.Scrapy爬虫框架 Scrapy是一个使用Python编程语言编写的爬虫框架,任何人都可以根据自己的需求进行修改,并且 ...
- python网络爬虫(14)使用Scrapy搭建爬虫框架
目的意义 爬虫框架也许能简化工作量,提高效率等.scrapy是一款方便好用,拓展方便的框架. 本文将使用scrapy框架,示例爬取自己博客中的文章内容. 说明 学习和模仿来源:https://book ...
- scrapy爬虫框架入门实例(一)
流程分析 抓取内容(百度贴吧:网络爬虫吧) 页面: http://tieba.baidu.com/f?kw=%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB&ie=ut ...
随机推荐
- jboos下载地址记录
JBoss在2006年被 RedHat 收购.在各种 J2EE 应用服务器中,JBoss 是最受欢迎而且功能最为强大的应用服务器.不过JBoss从8.0开始改名为WildFly,这个新名称在我看来似乎 ...
- python进程编程
多进程multiprocess模块 multiprocessing is a package that supports spawning processes using an API similar ...
- CSS3 转换
CSS3 转换 版权声明:未经博主授权,内容严禁转载 什么是转换 转换时使元素改变形状.尺寸和位置的一种效果. 可以对元素应用 2D 或 3D 转换,从而对元素进行旋转.缩放.移动或倾斜. 2D 转换 ...
- 20145302张薇 《网络对抗》MSF应用基础
20145302张薇 <网络对抗>MSF应用基础 实验内容 掌握metasploit的基本应用方式 1.主动攻击--ms08_067 2.针对浏览器的攻击--ms11_050 3.针对客户 ...
- MBR记录
mbr version: 1.6 boot code size: primary data size: extended data size: debug version: no bpb status ...
- 螺旋折线|2018年蓝桥杯B组题解析第七题-fishers
标题:螺旋折线 如图p1.png所示的螺旋折线经过平面上所有整点恰好一次. 对于整点(X, Y),我们定义它到原点的距离dis(X, Y)是从原点到(X, Y)的螺旋折线段的长度. 例如dis(0, ...
- hdu 3874(树状数组)题解
Problem Description Mery has a beautiful necklace. The necklace is made up of N magic balls. Each ba ...
- 第五章 消息摘要算法--MAC
注意:本节内容主要参考自<Java加密与解密的艺术(第2版)>第6章“验证数据完整性--消息摘要算法” 5.1.mac(又称为Hmac) 原理:在md与sha系列算法的基础上加入了密钥,是 ...
- Unity3D学习笔记(十):Physics类和射线
物理系统:碰撞器.触发器等 力:有大小有方向的矢量,有受力点位置(和向量的区别) ----F = ma(m质量,a加速度,质量越大,加速度越小,停下来越慢) ----m1v1 = m2v2(冲量守恒定 ...
- SPOJ - HIGH Highways(矩阵树定理)
https://vjudge.net/problem/SPOJ-HIGH 题意: 给n个点m条边,求生成树个数. 思路: 矩阵树裸题. 具体的话可以看一下周冬的论文<生成树的计数及其应用> ...