Ceph S3 基于NGINX的集群复制方案
前言
ceph的s3数据的同步可以通过radosgw-agent进行同步,同region可以同步data和metadata,不同region只能同步metadata,这个地方可以参考下秦牧羊梳理的 ceph radosgw 多集群同步部署流程,本篇讲述的方案与radosgw-agent的复制方案不同在于,这个属于前端复制,后端相当于透明的两个相同集群,在入口层面就将数据进行了复制分流
在某些场景下,需求可能比较简单:
- 需要数据能同时存储在两个集群当中
- 数据写一次,读多次
- 两个集群都能写
一方面两个集群可以增加数据的可靠性,另一方面可以提高读带宽,两个集群同时可以提供读的服务
radosgw-agent是从底层做的同步,正好看到秦牧羊有提到nginx新加入了ngx_http_mirror_module 这个模块,那么本篇就尝试用这个模块来做几个简单的配置来实现上面的需求,这里纯架构的尝试,真正上生产还需要做大量的验证和修改的测试的
结构设想
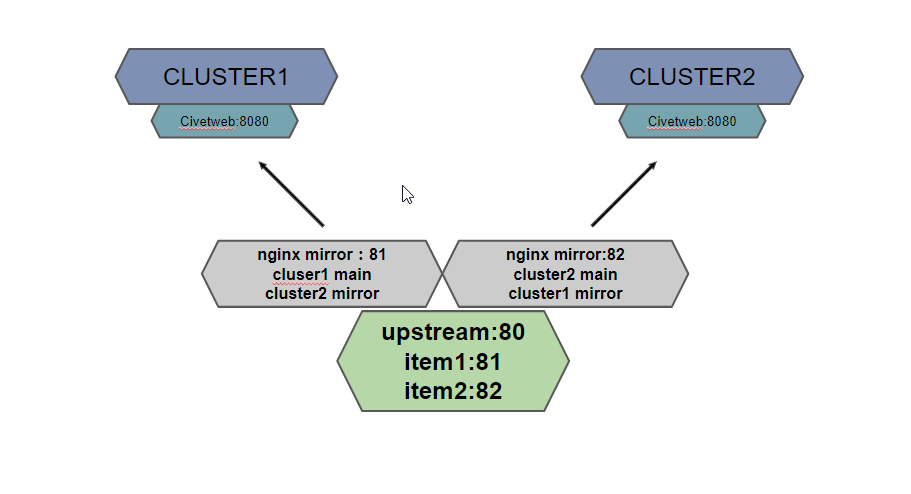
当数据传到nginx的server的时候,nginx本地进行负载均衡到两个本地端口上面,本地的两个端口对应到两个集群上面,一个主写集群1,一个主写集群2,这个是最简结构,集群的civetweb可以是很多机器,nginx这个也可以是多台的机器,在一台上面之所以做个均衡是可以让两个集群是对等关系,而不是一个只用nginx写,另一个只mirror写
环境准备
准备两个完全独立的集群,分别配置一个s3的网关,我的环境为:
192.168.19.101:8080
192.168.19.102:8080
在每个机器上都创建一个管理员的账号,这个用于后面的通过restapi来进行管理的,其他的后面的操作都通过http来做能保证两个集群的数据是一致的
nginx的机器在192.168.19.104
在两个集群当中都创建相同的管理用户
radosgw-admin user create --uid=admin --display-name=admin --access_key=admin --secret=123456
这里为了测试方便使用了简单密码
此时admin还仅仅是普通的权限,需要通过--cap添加user的capabilities,例如:
radosgw-admin caps add --uid=admin --caps="users=read, write"
radosgw-admin caps add --uid=admin --caps="usage=read, write"
下面就用到了nginx的最新的模块了
Nginx 1.13.4 发布,新增 ngx_http_mirror_module 模块
软件下载:
wget https://nginx.org/packages/mainline/centos/7/x86_64/RPMS/nginx-1.13.4-1.el7.ngx.x86_64.rpm
下载rpm包然后安装
安装:
rpm -ivh nginx-1.13.4-1.el7.ngx.x86_64.rpm
修改nginx配置文件:
upstream s3 {
server 127.0.0.1:81;
server 127.0.0.1:82;
}
server {
listen 81;
server_name localhost;
location / {
mirror /mirror;
proxy_pass http://192.168.19.101:8080;
}
location /mirror {
internal;
proxy_pass http://192.168.19.102:8080$request_uri;
}
}
server {
listen 82;
server_name localhost;
location / {
mirror /mirror;
proxy_pass http://192.168.19.102:8080;
}
location /mirror {
internal;
proxy_pass http://192.168.19.101:8080$request_uri;
}
}
server{
listen 80;
location / {
proxy_pass http://s3;
}
}
负载均衡的设置有很多种,这里用最简单的轮训的模式,想配置其他负载均衡模式可以参考我的《关于nginx-upstream的几种配置方式》
重启进程并检查服务
[root@node04 ~]# systemctl restart nginx
[root@node04 ~]# netstat -tunlp|grep nginx
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 1582973/nginx: mast
tcp 0 0 0.0.0.0:81 0.0.0.0:* LISTEN 1582973/nginx: mast
tcp 0 0 0.0.0.0:82 0.0.0.0:* LISTEN 1582973/nginx: mast
整个环境就配置完成了,下面我们就来验证下这个配置的效果是什么样的,下面会提供几个s3用户的相关的脚本
s3用户相关脚本
创建用户的脚本
#!/bin/bash
###
#S3 USER ADMIN
###
###==============WRITE BEGIN=============###
ACCESS_KEY=admin ## ADMIN_USER_TOKEN
SECRET_KEY=123456 ## ADMIN_USER_SECRET
HOST=192.168.19.104:80
USER_ACCESS_KEY="&access-key=user1"
USER_SECRET_KEY="&secret-key=123456"
###==============WRITE FINAL=======FINAL=====###
query2=admin/user
userid=$1
name=$2
uid="&uid="
date=`TZ=GMT LANG=en_US date "+%a, %d %b %Y %H:%M:%S GMT"`
header="PUT\n\n\n${date}\n/${query2}"
sig=$(echo -en ${header} | openssl sha1 -hmac ${SECRET_KEY} -binary | base64)
curl -v -H "Date: ${date}" -H "Authorization: AWS ${ACCESS_KEY}:${sig}" -L -X PUT "http://${HOST}/${query2}?format=json${uid}${userid}&display-name=${name}${USER_ACCESS_KEY}${USER_SECRET_KEY}" -H "Host: ${HOST}"
echo ""
运行脚本:
[root@node01 ~]# sh addusernew.sh user1 USER1
* About to connect() to 192.168.19.104 port 80 (#0)
* Trying 192.168.19.104...
* Connected to 192.168.19.104 (192.168.19.104) port 80 (#0)
> PUT /admin/user?format=json&uid=user1&display-name=USER1&access-key=user1&secret-key=123456 HTTP/1.1
> User-Agent: curl/7.29.0
> Accept: */*
> Date: Wed, 09 Aug 2017 07:51:58 GMT
> Authorization: AWS admin:wuqQUUXhhar5nQS5D5B14Dpx+Rw=
> Host: 192.168.19.104:80
>
< HTTP/1.1 200 OK
< Server: nginx/1.13.4
< Date: Wed, 09 Aug 2017 07:51:58 GMT
< Content-Type: application/json
< Content-Length: 195
< Connection: keep-alive
<
* Connection #0 to host 192.168.19.104 left intact
{"user_id":"user1","display_name":"USER1","email":"","suspended":0,"max_buckets":1000,"subusers":[],"keys":[{"user":"user1","access_key":"user1","secret_key":"123456"}],"swift_keys":[],"caps":[]}
在两个集群中检查:
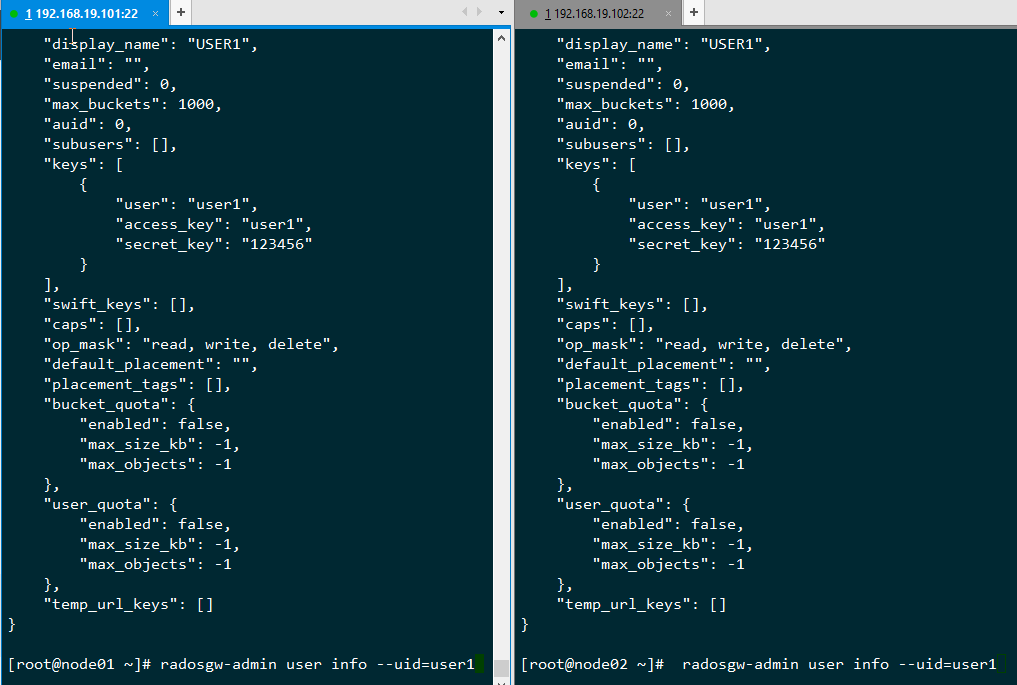
可以看到两个集群当中都产生了相同的用户信息
修改用户
直接把上面的创建脚本里面的PUT改成POST就是修改用户的脚本
删除用户脚本
#!/bin/bash
###
#S3 USER ADMIN
###
###==============WRITE BEGIN=============###
ACCESS_KEY=admin ## ADMIN_USER_TOKEN
SECRET_KEY=123456 ## ADMIN_USER_SECRET
HOST=192.168.19.104:80
###==============WRITE FINAL=======FINAL=====###
query2=admin/user
userid=$1
uid="&uid="
date=`TZ=GMT LANG=en_US date "+%a, %d %b %Y %H:%M:%S GMT"`
header="DELETE\n\n\n${date}\n/${query2}"
sig=$(echo -en ${header} | openssl sha1 -hmac ${SECRET_KEY} -binary | base64)
curl -v -H "Date: ${date}" -H "Authorization: AWS ${ACCESS_KEY}:${sig}" -L -X DELETE "http://${HOST}/${query2}?format=json${uid}${userid}" -H "Host: ${HOST}"
echo ""
执行删除用户:
[root@node01 ~]# sh deluser.sh user1

可以看到两边都删除了
获取用户的信息脚本
#! /bin/sh
###
#S3 USER ADMIN
###
###==============WRITE BEGIN=============###
ACCESS_KEY=admin ## ADMIN_USER_TOKEN
SECRET_KEY=123456 ## ADMIN_USER_SECRET
HOST=192.168.19.101:8080
###==============WRITE FINAL=======FINAL=====###
query2=admin/user
userid=$1
uid="&uid="
date=`TZ=GMT LANG=en_US date "+%a, %d %b %Y %H:%M:%S GMT"`
header="GET\n\n\n${date}\n/${query2}"
sig=$(echo -en ${header} | openssl sha1 -hmac ${SECRET_KEY} -binary | base64)
curl -v -H "Date: ${date}" -H "Authorization: AWS ${ACCESS_KEY}:${sig}" -L -X GET "http://${HOST}/${query2}?format=json${uid}${userid}&display-name=${name}" -H "Host: ${HOST}"
测试上传一个文件
通过192.168.19.104:80端口上传一个文件,然后通过nginx的端口,以及两个集群的端口进行查看
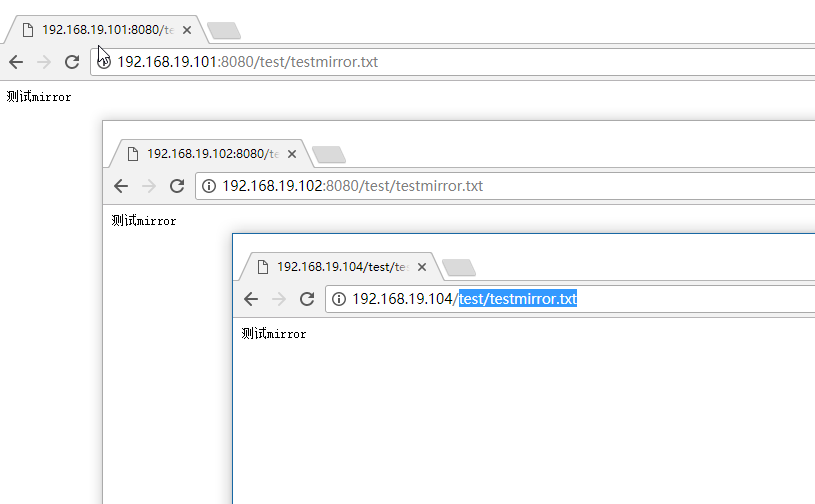
可以看到在上传一次的情况下,两个集群里面同时拥有了这个文件
总结
真正将方案运用到生产还需要做大量的验证测试,中间的失效处理,以及是否可以将写镜像,读取的时候不镜像,这些都需要进一步做相关的验证工作
本篇中的S3用户的管理接口操作参考了网上的其他资料
变更记录
| Why | Who | When |
|---|---|---|
| 创建 | 武汉-运维-磨渣 | 2017-08-10 |
Ceph S3 基于NGINX的集群复制方案的更多相关文章
- 基于Centos7xELK+Kafka集群部署方案
本次集群部署使用ELK版本统一为6.8.10,kafka为2.12-2.51 均可在官网下载 elasticsearch下载地址:https://www.elastic.co/cn/downloads ...
- 基于Nginx实现集群原理
1)安装Nginx 2)配置多个Tomcat,并修改端口号(两个端口号不一样即可) 3)在Nginx的Nginx.conf添加如下配置:
- Linux+.NetCore+Nginx搭建集群
本篇和大家分享的是Linux+NetCore+Nginx搭建负载集群,对于netcore2.0发布后,我一直在看官网的文档并学习,关注有哪些新增的东西,我,一个从1.0到2.0的跟随者这里只总结一句话 ...
- Centos7+nginx+keepalived集群及双主架构案例
目录简介 一.简介 二.部署nginx+keepalived 集群 三.部署nginx+keepalived双主架构 四.高可用之调用辅助脚本进行资源监控,并根据监控的结果状态实现动态调整 一.简介 ...
- nginx实现集群高可用
大家知道NGINX作为反向代理服务器可以实现负载均衡,同时也可以作为静态文件服务器,它的特点就是并发支持大,单机可同时支持3万并发,现在很多网站都把NGINX作为网关入口来统一调度分配后端资源.但是如 ...
- LB+nginx+tomcat7集群模式下的https请求重定向(redirect)后变成http的解决方案
0. 环境信息 Linux:Linux i-8emt1zr1 2.6.32-573.el6.x86_64 #1 SMP Wed Jul 1 18:23:37 EDT 2015 x86_64 x86_6 ...
- Tomcat之如何使用Nginx进行集群部署
目录结构: contents structure [+] 1,为什么需要集群 2,如何使用Nginx部署tomcat集群 2.1,下载Nginx 2.2,在同一台电脑上部署多个Tomcat服务器 2. ...
- FastDFS+nginx+keepalived集群搭建
安装环境 nginx-1.6.2 libfastcommon-master.zip FastDFS_v5.05.tar.gz(http://sourceforge.net/projects/fastd ...
- tomcat+nginx+redis集群试验
Nginx负载平衡 + Tomcat + 会话存储Redis配置要点 使用Nginx作为Tomcat的负载平衡器,Tomcat的会话Session数据存储在Redis,能够实现0当机的7x24 运 ...
随机推荐
- HDU-1051 Wooden Sticks--线性动归(LIS)
题目大意:有n根木棍(n<5000),每根木棍有一个长度l和重量w(l,w<10000),现在要对这些木头进行加工,加工有以下规则: 1.你需要1分钟来准备第一根木头. 2.如果下一根木头 ...
- 第十一章 LNMP架构基础介绍
一.LNMP架构 1.简介 oLNMP是一套技术的组合,L=Linux.N=Nginx.M~=MySQL.P~=PHP不仅仅包含这些,还有redis/ELK/zabbix/git/jenkins/ka ...
- docker安装部署neo4j
docker部署neo4j 环境:ubuntu16.04LTS docker安装 详见:菜鸟教程(docker安装) docker国内镜像源配置 第一步,进入阿里云,登陆后点击左侧的镜像加速,生成自己 ...
- ps命令没有显示路径找到命令真实路径
top发现某程序占用大量资源,但ps查看看不到程序真实路径,查找真实路径. ps aux |grep COMMAND 找到PID ls /proc/ 里边有很多数字文件夹,找到PID相应的文件夹进去看 ...
- win7下安装docker
为了支持老版本的windows系统,docker官方提供了docker toolbox,让用户可以在windows10以前版本的操作系统上来体验docker. 一,安装 下载msi安装文件,一路nex ...
- Java网关服务-AIO(三)
Java网关服务-AIO(三) 概述 前两节中,我们已经获取了body的总长度,剩下的就是读出body,处理请求 ChannelServerHandler ChannelServerHandler即从 ...
- 打爆你的 CPU
打爆你的 CPU Intro 今天来尝试写一段代码,把 CPU 打满,让所有处理器的 CPU 使用率达到 100% 如何提高 CPU 使用率 想要提高 CPU 的使用率就是要让 CPU 一直在工作,单 ...
- SQL SERVER迁移--更换磁盘文件夹
默认情况下SQL SERVER的安装路径与数据库的默认存放路径是在C盘的--这就很尴尬. 平时又不注意,有天发现C盘的剩余空间比较吃紧了,于是着手想办法迁移文件夹. 一.环境准备 数据库版本--SQL ...
- E. Tree Reconstruction 解析(思維)
Codeforce 1041 E. Tree Reconstruction 解析(思維) 今天我們來看看CF1041E 題目連結 題目 略,請直接看原題 前言 一開始完全搞錯題目意思,還以為每次會刪除 ...
- 彻底搞明白this
this是我们在书写代码时最常用的关键词之一,即使如此,它也是JavaScript最容易被最头疼的关键词.那么this到底是什么呢? 如果你了解执行上下文,那么你就会知道,其实this是执行上下文对象 ...