基于Centos7xELK+Kafka集群部署方案
本次集群部署使用ELK版本统一为6.8.10,kafka为2.12-2.51 均可在官网下载
elasticsearch下载地址:https://www.elastic.co/cn/downloads/elasticsearch
logstash下载地址:https://www.elastic.co/cn/downloads/logstash
kibana下载地址:https://www.elastic.co/cn/downloads/kibana
kafka下载地址:http://kafka.apache.org/downloads
整体流程如下图 仅供参考 可根据需求调整
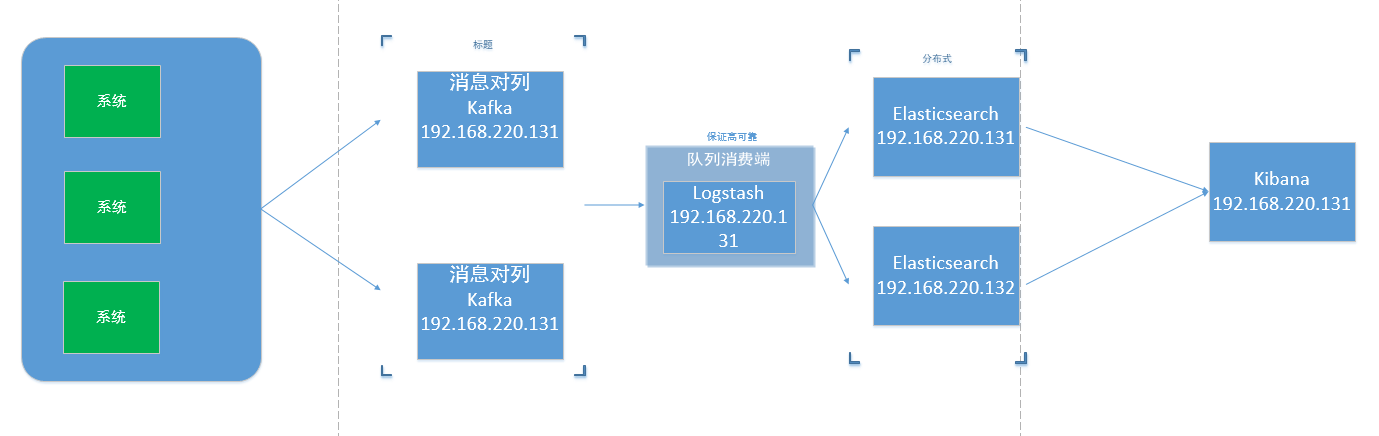
一、elasticsearch安装
(1) 准备部署包并解压到/usr/local 下并解压
• tar -zxf elasticsearch-6.8.10.tar.gz
• tar -zxf kibana-6.8.10-linux-x86_64.tar.gz
• tar -zxf logstash-6.8.10.tar.gz
(2) 由于elasticsearch启动的时候不能直接用root用户启动,所以需要创建普通用户
useradd elk
chown -R elk:elk elasticsearch-6.8.10
chown -R elk:elk kibana-6.8.10-linux-x86_64
chown -R elk:elk logstash-6.8.10
(3)启动前的配置工作防止启动报错
修改操作系统的内核配置文件:vim /etc/sysctl.conf
新增:vm.max_map_count=655360
vim /etc/security/limits.conf
新增:* soft nofile 65536
* hard nofile 65536
* soft nproc 4096
* hard nproc 4096
执行 sysctl -p 使配置生效
(4) 配置elasticsearch 配置文件elasticsearch.yml
network.host: 0.0.0.0
http.port: 9200
node.name: node-1
transport.tcp.port: 9300
discovery.zen.ping.unicast.hosts: ["192.168.220.131:9300","192.168.220.132:9300"]
discovery.zen.minimum_master_nodes: 1
bootstrap.memory_lock: false
node.master: true
node.data: true
http.cors.enabled: true
http.cors.allow-origin: "*"
(5) 启动
./bin/elasticsearch
#后台启动
./bin/elasticsearch -d
(6)查看是否启动成功
ps aux|grep elasticsearch
# 关闭es(kill + 进程号)
kill 99089
(7) 如上操作复制到192.168.220.131将配置文件elasticsearch.yml中 node.name: node-1改为
node.name: node-2
二、kibana安装
(1) 配置kibana配置文件kibana.yml
vi kibana.yml
修改
elasticsearch.hosts: ["http://192.168.220.131:9200"]
server.host: "0.0.0.0"
i18n.locale: "zh-CN"
(2) 启动Kibana
# 查看kibana是否启动成功
fuser -n tcp 5601
# 关闭kibana
kill 线程号
# 启动kibana
./bin/kibana
# 后台启动
nohup ./bin/kibana &
三、logstash安装
(1) 配置logstash配置文件logstash.yml
vi logstash.yml
(2) /config目录下新增文件logstash.conf
cp logstash-sample.conf logstash.conf
input {
kafka {
bootstrap_servers => "192.168.220.131:9092,192.168.220.132:9092"
topics => ["qlz-test","qlz-test1"]
group_id => "logstash-file"
codec => "json"
}
}
output {
elasticsearch {
hosts => ["http://192.168.220.131:9200"]
index => "elasticsearch-test"
}
}
(3)启动logstash
bin/logstash -f config/logstash.conf
#后台启动
nohup bin/logstash -f config/logstash.conf &
#查看后台启动日志
tail -f nohup.out
#查看是否启动成功
ps aux|grep logstash
四、kafka集群安装
准备kafka_2.12-2.5.1.tgz安装包并解压到/usr/local下
tar -zxf kafka_2.12-2.5.1.tgz
在搭建kafka集群之前需要提前安装zookeeper集群,kafka压缩包只带zookeeper程序,只需要解压配置即可使用
(1) 修改配置文件zookeeper配置文件
vi zookeeper.properties
#数据路径
dataDir=/data/zookeeper
# the port at which the clients will connect
clientPort=2181
# disable the per-ip limit on the number of connections since this is a non-production config
maxClientCnxns=0
#tickTime : 这个时间是作为 Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。
tickTime=2000
# 集群模式下,follower机器启动,需要从Leader上同步最新数据,来确定自身服务新状态,同步需要在initLimit内完成。即同步时间为10*2000=20s(initLimit*tickTime)
initLimit=20
# 集群模式下,Leader需要与集群中的其他机器Follower进行通信,则通过心跳机制来检测Follower状态,如果超过心跳间隔syncLimit,则表示Follower下线。心跳时间间隔为5*2000=10s(syncLimit*tickTime)
syncLimit=10
#2888 端口:表示的是这个服务器与集群中的 Leader 服务器交换信息的端口;
#3888 端口:表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader ,而这个端口就是用来执行选举时服务器相互通信的端口
server.1=192.168.220.131:2888:3888
server.2=192.168.220.132:2888:3888
创建数据目录并创建myid文件,文件为数字,用于标识唯一主机,必须有这个文件否则zookeeper无法启动
mkdir /data/zookeeper -p
echo 1 >/data/zookeeper/myid
(2) 修改kafka配置文件
vi server.properties
#唯一数字分别为1,2
broker.id=1
#这个broker监听的端口
prot=9092
#唯一填服务器IP
host.name=192.168.220.131
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
#kafka日志路径,不需要提前创建,启动kafka时创建
log.dirs=/data/kafka-logs
#分片数,需要配置较大,分片影响读写速度
num.partitions=16
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
#zookpeer集群
zookeeper.connect=192.168.220.131:2181,192.168.220.132:2181
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
把配置拷贝至其他kafka主机,zookeeper.properties配置一样 ,server.properties配置一下两处不一样,myid也不一样
broker.id=2
host.name=192.168.220.132
(3) 启动zookeeper顺序为服务器1 2
/usr/local/kafka_2.12-2.5.1/bin/zookeeper-server-start.sh /usr/local/kafka_2.12-2.5.1/config/zookeeper.properties
#后台启动
/usr/local/kafka_2.12-2.5.1/bin/zookeeper-server-start.sh -daemon /usr/local/kafka_2.12-2.5.1/config/zookeeper.properties
启动过程中提示拒绝连接不用理会,由于zookeeper集群在启动的时候,每个结点都试图去连接集群中的其它结点,先启动的肯定连不上后面还没启动的,所以上面日志前面部分的异常是可以忽略的。通过后面部分可以看到,集群在选出一个Leader后,最后稳定了。其他节点也可能会出现类似的情况,属于正常
检测是否启动
netstat -ntalp|grep -E "2181|2888|3888"
(4) 启动kafka
/usr/local/kafka_2.12-2.5.1/bin/kafka-server-start.sh /usr/local/kafka_2.12-2.5.1/config/server.properties
#后台启动
/usr/local/kafka_2.12-2.5.1/bin/kafka-server-start.sh -daemon /usr/local/kafka_2.12-2.5.1/config/server.properties
(5) 测试
在kafka01创建一个主题,主题名为qlz-test
./kafka-topics.sh --create --zookeeper 192.168.220.131:2181 --replication-factor 3 --partitions 1 --topic qlz-test
查看主题
# 查看所有主题
./kafka-topics.sh --list --zookeeper 192.168.220.131:2181
# 查看qlz-test主题详情
./kafka-topics.sh --describe --zookeeper 192.168.220.131:2181 --topic qlz-test
Topic: qlz-test PartitionCount: 1 ReplicationFactor: 2 Configs:
Topic: qlz-test Partition: 0 Leader: 1 Replicas: 1,2 Isr: 1,2
#主题名称:qlz-test
#Partition:只有一个从0开始
#leader:id为1的broker
#Replicas: 副本存在id为 1 2的上面
#Isr:活跃状态的broker
删除主题
./kafka-topics.sh --delete --zookeeper 192.168.220.131:2181 --topic qlz-test
使用kafka01发送消息,这里是生产者角色
./kafka-console-producer.sh --broker-list 192.168.220.131:9092 --topic qlz-test
出现命令行需要手动输入消息
使用kafka02接收消息,这里是消费者角色
./kafka-console-consumer.sh --bootstrap-server 192.168.220.131:9092 --topic qlz-test --from-beginning
在kafka01输入消息然后会在kafka02接收到该消息
基于Centos7xELK+Kafka集群部署方案的更多相关文章
- Apache Kafka 集群部署指南
公众号关注 「开源Linux」 回复「学习」,有我为您特别筛选的学习资料~ Kafka基础 消息系统的作用 应该大部分小伙伴都清楚,用机油装箱举个例子. 所以消息系统就是如上图我们所说的仓库,能在中间 ...
- 分布式消息系统之Kafka集群部署
一.kafka简介 kafka是基于发布/订阅模式的一个分布式消息队列系统,用java语言研发,是ASF旗下的一个开源项目:类似的消息队列服务还有rabbitmq.activemq.zeromq:ka ...
- zookeeper集群+kafka集群 部署
zookeeper集群 +kafka 集群部署 1.Zookeeper 概述: Zookeeper 定义 zookeeper是一个开源的分布式的,为分布式框架提供协调服务的Apache项目 Zooke ...
- kafka 集群部署 多机多broker模式
kafka 集群部署 多机多broker模式 环境IP : 172.16.1.35 zookeeper kafka 172.16.1.36 zookeeper kafka 172.16 ...
- Zookeeper+Kafka集群部署(转)
Zookeeper+Kafka集群部署 主机规划: 10.200.3.85 Kafka+ZooKeeper 10.200.3.86 Kafka+ZooKeeper 10.200.3.87 Kaf ...
- 3、Kafka集群部署
Kafka集群部署 1)解压安装包 [ip101]$ tar -zxvf kafka_2.11-0.11.0.0.tgz -C /opt/app/ 2)修改解压后的文件名称 [ip101]$ mv k ...
- Zookeeper+Kafka集群部署
Zookeeper+Kafka集群部署 主机规划: 10.200.3.85 Kafka+ZooKeeper 10.200.3.86 Kafka+ZooKeeper 10.200.3.87 Kaf ...
- Kafka集群部署 (守护进程启动)
1.Kafka集群部署 1.1集群部署的基本流程 下载安装包.解压安装包.修改配置文件.分发安装包.启动集群 1.2集群部署的基础环境准备 安装前的准备工作(zk集群已经部署完毕) 关闭防火墙 c ...
- Kafka集群部署以及使用
Kafka集群部署 部署步骤 hadoop102 hadoop103 hadoop104 zk zk zk kafka kafka kafka http://kafka.apache.org/down ...
随机推荐
- window.navigator All In One
window.navigator All In One navigator "use strict"; /** * * @author xgqfrms * @license MIT ...
- 高阶类 & HOC & anonymous class extends
高阶类 & HOC & anonymous class extends js 匿名 class extends / mix-ins / 多继承 高阶函数 HOF, 接收一个 funct ...
- CSS will-change All In One
CSS will-change All In One CSS animation effect live demo https://nextjs.org/conf/ https://nextjs.or ...
- Caddyfile 是干什么的?
Caddyfile 是干什么的? The Caddyfile is a convenient Caddy configuration format for humans. It is most peo ...
- Node.js & ES Modules & Jest
Node.js & ES Modules & Jest CJS & ESM CommonJS https://en.wikipedia.org/wiki/CommonJS ht ...
- CSS rulesets
CSS rulesets https://developer.mozilla.org/en-US/docs/Web/CSS/Syntax#CSS_rulesets https://css-tricks ...
- PBN转弯保护区作图回顾
假期的最后一天,是该小结一下的时候了. 风螺旋有了自己中式风格的Logo,大家是否喜欢? 过去的春节假期,我们从学习CAD入手,回顾了风螺旋在PBN中的多种情况,画了很多的图,写了不少的文字,或许现在 ...
- spring5学习笔记
Spring5 框架概述 1.Spring 是轻量级的开源的 JavaEE 框架 2.Spring 可以解决企业应用开发的复杂性 3.Spring 有两个核心部分:IOC 和 Aop (1)IOC:控 ...
- 与程序员相关的CPU缓存知识
本文转载自与程序员相关的CPU缓存知识 基础知识 首先,我们都知道现在的CPU多核技术,都会有几级缓存,老的CPU会有两级内存(L1和L2),新的CPU会有三级内存(L1,L2,L3 ),如下图所示: ...
- SpringBoot(八):SpringBoot中配置字符编码 Springboot中文乱码处理
SpringBoot中配置字符编码一共有两种方式 方式一: 使用传统的Spring提供的字符编码过滤器(和第二种比较,此方式复杂,由于时间原因这里先不介绍了,后续补上) 方式二(推荐使用) 在appl ...