Hadoop之计数器与自定义计数器及Combiner的使用
1,计数器:
显示的计数器中分为四个组,分别为:File Output Format Counters、FileSystemCounters、File Input Format Counters和Map-Reduce Framkework。
分组File Input Format Counters包括一个计数器Bytes Read,表示job执行结束后输出文件的内容包括的字节数(空格、换行都是字符)
关于以上这段计数器日志中详细的说明请见下面的注释:

1 Counters: 19 // Counter表示计数器,19表示有19个计数器(下面一共4计数器组)
2 File Output Format Counters // 文件输出格式化计数器组
3 Bytes Written=19 // reduce输出到hdfs的字节数,一共19个字节
4 FileSystemCounters// 文件系统计数器组
5 FILE_BYTES_READ=481
6 HDFS_BYTES_READ=38
7 FILE_BYTES_WRITTEN=81316
8 HDFS_BYTES_WRITTEN=19
9 File Input Format Counters // 文件输入格式化计数器组
10 Bytes Read=19 // map从hdfs读取的字节数
11 Map-Reduce Framework // MapReduce框架
12 Map output materialized bytes=49
13 Map input records=2 // map读入的记录行数,读取两行记录,”hello you”,”hello me”
14 Reduce shuffle bytes=0 // 规约分区的字节数
15 Spilled Records=8
16 Map output bytes=35
17 Total committed heap usage (bytes)=266469376
18 SPLIT_RAW_BYTES=105
19 Combine input records=0 // 合并输入的记录数
20 Reduce input records=4 // reduce从map端接收的记录行数
21 Reduce input groups=3 // reduce函数接收的key数量,即归并后的k2数量
22 Combine output records=0 // 合并输出的记录数
23 Reduce output records=3 // reduce输出的记录行数。<helllo,{1,1}>,<you,{1}>,<me,{1}>
24 Map output records=4 // map输出的记录行数,输出4行记录
2,自定义计数器:
由于不同的场景有不同的计数器应用需求,我们可以自定义不同的计数器:
一:敏感词准备:
将文件中的hello设为敏感词,自定义计数器的目的是将文件中出现的计数器的次数给记录出来
二:代码部分:
仅需要修改之前博客中WordClass中的map的代码部分:
public class WordClass {
public static class MyMapper extends org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, Text, LongWritable> {
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException {
//动态申明
Counter sensitiveCounter = context.getCounter("Sensitive Words", "hello");
String line = value.toString();
//假设hello是一个敏感词
if (line.contains("hello")){
sensitiveCounter.increment(1L);
}
String[] split = line.split("\t");
for (String word :
split) {
context.write(new Text(word), new LongWritable(1));
}
}
}
计数器声明
1.通过枚举声明 context.getCounter(Enum enum)
2.动态声明 context.getCounter(String groupName,String counterName)
计数器操作
counter.setValue(long value);//设置初始值
counter.increment(long incr);//增加计数
三:结果
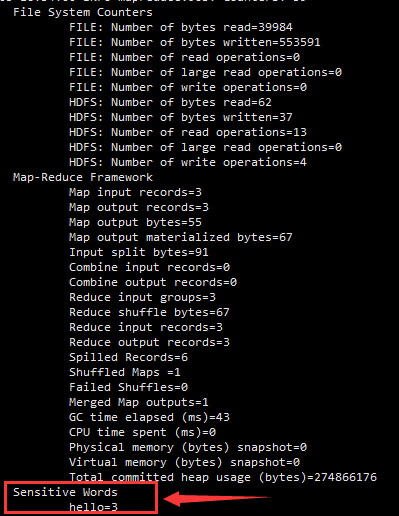
在日志信息中可以看到文件中的敏感词信息
3,Combiner的使用
Combiner的作用就是在map端对数据进行合并,从而提高网络的通讯速率,减少map到reduce的网络带宽
我们可以本地把Map的输出做一个合并计算,把具有相同key的数据做一个计算,然后再把此输出作为reduce的输入,这样传给reduce的数据就少了很多。Combiner是用reducer来定义的,多数的情况下Combiner和reduce处理的是同一种逻辑,所以job.setCombinerClass()的参数可以直接使用定义的reduce,括号中可以直接传入类似于MyReducer.Class,当然也可以单独去定义一个有别于reduce的Combiner,继承Reducer,写法基本上定义reduce一样。
----那么,既然Combiner这么有用为什么不能将它作为默认设置呢?
----因为当有类似于求平均数的任务时,在map端执行Combiner会影响最终的结果,所以有些操作并不适合用Combiner,在工作使用中我们应该先选取小部分的数据进行测试,如果结果无误的话,则可以使用Combiner进行map端的数据合并
Hadoop之计数器与自定义计数器及Combiner的使用的更多相关文章
- Hadoop学习笔记—7.计数器与自定义计数器
一.Hadoop中的计数器 计数器:计数器是用来记录job的执行进度和状态的.它的作用可以理解为日志.我们通常可以在程序的某个位置插入计数器,用来记录数据或者进度的变化情况,它比日志更便利进行分析. ...
- 9.1hadoop 内置计数器、自定义枚举计数器、Streaming计数器
1.1 计数器 计数器的作用是用来统计数量的,用于记录特定事件的次数,分为内置计数器.自定义java枚举计数器.自定义Stream计数器三大类.用于质量分析,或应用级统计.分析计数器的值比分析一堆日 ...
- ionic3.x angular4.x ng4.x 自定义组件component双向绑定之自定义计数器
本文主要示例在ionic3.x环境下实现一个自定义计数器,实现后最终效果如图: 1.使用命令创建一个component ionic g component CounterInput 类似的命令还有: ...
- CSS计数器(自定义列表)
概念 CSS3计数器(CSS Counters)可以允许我们使用css对页面中的任意元素进行计数,实现类似于有序列表的功能(自定义有序列表) 与有序列表相比,它的突出特性在于可以对任意元素计数,同时实 ...
- CSS计数器(自定义列表)Demo
html <!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <ti ...
- Hadoop学习笔记—5.自定义类型处理手机上网日志
转载自http://www.cnblogs.com/edisonchou/p/4288737.html Hadoop学习笔记—5.自定义类型处理手机上网日志 一.测试数据:手机上网日志 1.1 关于这 ...
- Hadoop生态圈-hive编写自定义函数
Hadoop生态圈-hive编写自定义函数 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- Hadoop生态圈-Hive的自定义函数之UDTF(User-Defined Table-Generating Functions)
Hadoop生态圈-Hive的自定义函数之UDTF(User-Defined Table-Generating Functions) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- Hadoop生态圈-Hive的自定义函数之UDAF(User-Defined Aggregation Function)
Hadoop生态圈-Hive的自定义函数之UDAF(User-Defined Aggregation Function) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
随机推荐
- 1698-Just a Hook 线段树(区间替换)
Just a Hook Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total ...
- Hadoop:WordCount分析
相关代码: package com.hadoop; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.P ...
- MediaTypeListWidget->insertItem 添加的label没有填充单元格
label没有填充满当前的item,但是主界面拉伸或者大小变化之后会填充当前的item 类似相关的问题我猜测都是因为子控件或者需要参考的控件的参考对象的大小在初始化的时候还没有完成最终的初始化,导致大 ...
- iOS-合成图片(长图)
合成图片 直接合成图片还是比较简单的,现在的难点是要把,通过文本输入的一些基本数据也合成到一张图片中,如果有多长图片就合成长图. 现在的实现方法是,把所有的文本消息格式化,然后绘制到一个UILable ...
- iOS-读写plist文件
读写plist文件 问题,我有一个plist文件,表示56个民族的,但是里面保存的字典,我想转换成一个数组 好的,那么就先遍历这个plist,然后将结果保存到一个数组中,这里出现的一个问题就是C语言字 ...
- Linux下的调试工具
Linux下的调试工具 随着XP的流行,人们越来越注重软件的前期设计.后期的实现,以及贯穿于其中的测试工作,经过这个过程出来的自然是高质量的软件.甚至有人声称XP会淘汰调试器!这当然是有一定道理的,然 ...
- Qt 使用irrlicht(鬼火)3D引擎
项目中需要加载简单的3D场景.资深老前辈推荐使用开源小巧的引擎irrlicht. 关于irrlicht,来之百度百科 Irrlicht引擎是一个用C++书写的高性能实时的3D引擎,可以应用于C++程序 ...
- Spring实战第九章学习笔记————保护Web应用
保护Web应用 在这一章我们将使用切面技术来探索保护应用程序的方式.不过我们不必自己开发这些切面----我们将使用Spring Security,一种基于Spring AOP和Servlet规范的Fi ...
- highcharts图表插件初探
转载请注明出处:http://www.cnblogs.com/liubei/p/highchartsOption.html HighCharts简介 Highcharts 是一个用纯JavaScrip ...
- JavaScript五种继承方式详解
本文抄袭仅供学习http://www.ruanyifeng.com/blog/2010/05/object-oriented_javascript_inheritance.html 一. 构造函数绑定 ...