python爬西刺代理
爬IP代码
import requests
import re
import dauk
from bs4 import BeautifulSoup
import time
def daili():
print('[+]极速爬取代理IP,默认为99页')
for b in range(1,99):
url="http://www.xicidaili.com/nt/{}".format(b)
header={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:58.0) Gecko/20100101 Firefox/48.0'}
r=requests.get(url,headers=header)
gsx=BeautifulSoup(r.content,'html.parser')
for line in gsx.find_all('td'):
sf=line.get_text()
dailix=re.findall('(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)',str(sf))
for g in dailix:
po=".".join(g)
print(po)
with open ('采集到的IP.txt','a') as l:
l.write(po+'\n') daili() def dailigaoni():
print('[+]极速爬取代理IP,默认为99页')
for i in range(1,99):
url="http://www.xicidaili.com/nn/{}".format(i)
header={'User-Agent':'Mozilla/5.0 (Windows NT 6.1 Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
r=requests.get(url,headers=header)
bks=r.content
luk=re.findall('(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)',str(bks))
for g in luk:
vks=".".join(g)
print(vks)
with open('采集到的IP.txt','a') as b:
b.write(vks+'\n')
dailigaoni() def dailihtp():
print('[+]极速爬取代理IP,默认为99页')
for x in range(1,99):
header="{'User-Agent':'Mozilla/5.0 (Windows NT 6.1 Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}"
url="http://www.xicidaili.com/wn/{}".format(x)
r=requests.get(url,headers=header)
gs=r.content
bs=re.findall('(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)',gs)
for kl in bs:
kgf=".".join(kl)
print(kgf)
with open ('采集到的IP.txt','a') as h:
h.write(kgf)
dailihtp() def dailihttps():
print('[+]极速爬代理IP,默认为99页')
for s in range(1,99):
url="http://www.xicidaili.com/wt/{}".format(s)
header={'User-Agent':'Mozilla/5.0 (Windows NT 6.1 Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
r=requests.get(url,headers=header)
kl=r.content
lox=re.findall('(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)',kl)
for lk in lox:
los=".".join(lk)
print(los)
with open('采集到的IP.txt','a') as lp:
lp.write(los)
dailihttps()
端口代码
import requests
import re
from bs4 import BeautifulSoup def daili():
print('[+]极速爬取代理IP端口,默认为99页')
for b in range(1, 99):
url = "http://www.xicidaili.com/nt/{}".format(b)
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:58.0) Gecko/20100101 Firefox/48.0'}
r = requests.get(url, headers=header)
gsx = BeautifulSoup(r.content, 'html.parser')
for line in gsx.find_all('td'):
sf = line.get_text()
dailix = re.findall(
'<td>([0-9]|[1-9]\d{1,3}|[1-5]\d{4}|6[0-5]{2}[0-3][0-5])</td>',
str(sf))
for g in dailix:
po = ".".join(g)
print(po )
with open('采集到的端口.txt.txt', 'a') as l:
l.write(po + '\n') daili() def dailigaoni():
print('[+]极速爬取代理IP的端口,默认为99页')
for i in range(1, 99):
url = "http://www.xicidaili.com/nn/{}".format(i)
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1 Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
r = requests.get(url, headers=header)
bks = r.content
luk = re.findall(
'<td>([0-9]|[1-9]\d{1,3}|[1-5]\d{4}|6[0-5]{2}[0-3][0-5])</td>',
str(bks))
for g in luk:
vks = ".".join(g)
print(vks)
with open('采集到的端口.txt.txt', 'a') as b:
b.write(vks + '\n') dailigaoni() def dailihtp():
print('[+]极速爬取代理IP,默认为99页')
for x in range(1, 99):
header = "{'User-Agent':'Mozilla/5.0 (Windows NT 6.1 Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}"
url = "http://www.xicidaili.com/wn/{}".format(x)
r = requests.get(url, headers=header)
gs = r.content
bs = re.findall(
'<td>([0-9]|[1-9]\d{1,3}|[1-5]\d{4}|6[0-5]{2}[0-3][0-5])</td>',
gs)
for kl in bs:
kgf = ".".join(kl)
print(kgf)
with open('采集到的端口.txt.txt', 'a') as h:
h.write(kgf) dailihtp() def dailihttps():
print('[+]极速爬代理IP的端口,默认为99页')
for s in range(1, 99):
url = "http://www.xicidaili.com/wt/{}".format(s)
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1 Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
r = requests.get(url, headers=header)
kl = r.content
lox = re.findall(
'<td>([0-9]|[1-9]\d{1,3}|[1-5]\d{4}|6[0-5]{2}[0-3][0-5])</td>',
kl)
for lk in lox:
los = ".".join(lk)
print(los)
with open('采集到的端口.txt', 'a') as lp:
lp.write(los) dailihttps()
调用代码
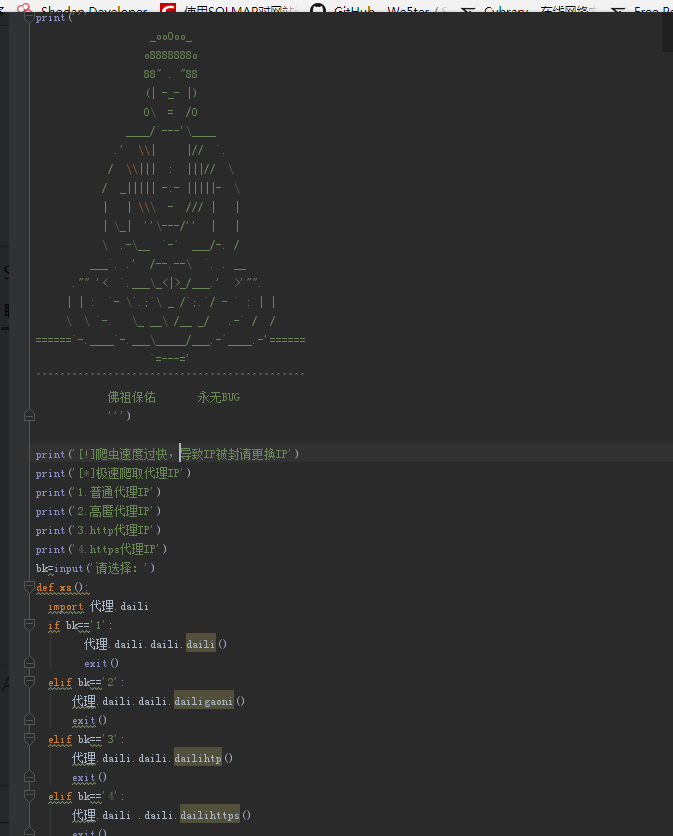
print('''
_ooOoo_
o8888888o
88" . "88
(| -_- |)
O\ = /O
____/`---'\____
.' \\| |// `.
/ \\||| : |||// \
/ _||||| -:- |||||- \
| | \\\ - /// | |
| \_| ''\---/'' | |
\ .-\__ `-` ___/-. /
___`. .' /--.--\ `. . __
."" '< `.___\_<|>_/___.' >'"".
| | : `- \`.;`\ _ /`;.`/ - ` : | |
\ \ `-. \_ __\ /__ _/ .-` / /
======`-.____`-.___\_____/___.-`____.-'======
`=---='
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
佛祖保佑 永无BUG
''')
print('[!]爬虫速度过快,导致IP被封请更换IP')
print('[*]极速爬取代理IP')
print('1.普通代理IP')
print('2.高匿代理IP')
print('3.http代理IP')
print('4.https代理IP')
bk=input('请选择:')
def xs():
import 代理.daili
import 代理.dauk
if bk=='1':
代理.daili.daili.daili()
代理.dauk.daili()
exit()
elif bk=='2':
代理.daili.daili.dailigaoni()
代理.dauk.dailigaoni()
exit()
elif bk=='3':
代理.daili.daili.dailihtp()
代理.dauk.dailihtp()
exit()
elif bk=='4':
代理.daili .daili.dailihttps()
代理.dauk.dailihttps()
exit()
elif bk=='q':
exit()
else:
print('[-]没有找到你要的选项')
xs()
2018-02-17
python爬西刺代理的更多相关文章
- 代理IP爬取和验证(快代理&西刺代理)
前言 仅仅伪装网页agent是不够的,你还需要一点新东西 今天主要讲解两个比较知名的国内免费IP代理网站:西刺代理&快代理,我们主要的目标是爬取其免费的高匿代理,这些IP有两大特点:免费,不稳 ...
- 使用XPath爬取西刺代理
因为在Scrapy的使用过程中,提取页面信息使用XPath比较方便,遂成此文. 在b站上看了介绍XPath的:https://www.bilibili.com/video/av30320885?fro ...
- Scrapy爬取西刺代理ip流程
西刺代理爬虫 1. 新建项目和爬虫 scrapy startproject daili_ips ...... cd daili_ips/ #爬虫名称和domains scrapy genspider ...
- python scrapy 爬取西刺代理ip(一基础篇)(ubuntu环境下) -赖大大
第一步:环境搭建 1.python2 或 python3 2.用pip安装下载scrapy框架 具体就自行百度了,主要内容不是在这. 第二步:创建scrapy(简单介绍) 1.Creating a p ...
- Python四线程爬取西刺代理
import requests from bs4 import BeautifulSoup import lxml import telnetlib #验证代理的可用性 import pymysql. ...
- python+scrapy 爬取西刺代理ip(一)
转自:https://www.cnblogs.com/lyc642983907/p/10739577.html 第一步:环境搭建 1.python2 或 python3 2.用pip安装下载scrap ...
- 手把手教你使用Python爬取西刺代理数据(下篇)
/1 前言/ 前几天小编发布了手把手教你使用Python爬取西次代理数据(上篇),木有赶上车的小伙伴,可以戳进去看看.今天小编带大家进行网页结构的分析以及网页数据的提取,具体步骤如下. /2 首页分析 ...
- python3爬虫-通过requests爬取西刺代理
import requests from fake_useragent import UserAgent from lxml import etree from urllib.parse import ...
- 极简代理IP爬取代码——Python爬取免费代理IP
这两日又捡起了许久不碰的爬虫知识,原因是亲友在朋友圈拉人投票,点进去一看发现不用登陆或注册,觉得并不复杂,就一时技痒搞一搞,看看自己的知识都忘到啥样了. 分析一看,其实就是个post请求,需要的信息都 ...
随机推荐
- AspectJ的Execution表达式
在使用spring框架配置AOP的时候,不管是通过XML配置文件还是注解的方式都需要定义pointcut"切入点" 例如定义切入点表达式 execution (* com.sam ...
- hdu 5974 A Simple Math Problem
A Simple Math Problem Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Ot ...
- listView使用小技巧P66--P76
1.设置分割线高度和颜色 android:divider="@android:color/darker_gray" android:dividerHeight="10dp ...
- 软工作业-四则运算(java实现)BY叶湖倩,叶钰羽
四则运算生成器 BY-信安1班 叶湖倩(3216005170) 信安1班 叶钰羽(3216005171) 1. 项目介绍 源代码GitHub地址:https://github.com/yeyuyu/s ...
- 四则运算生成与校检 Python实现
GitHub地址 https://github.com/little-petrol/Arithmetic.git 合作者: 郭旭 和 卢明凯 设计实现过程 代码的组织主要分为两个部分: 算法与结构体的 ...
- Flask的配置文件
Flask的配置文件 与 session 配置文件 flask中的配置文件是一个flask.config.Config对象(继承字典) 默认配置为: { 'DEBUG': get_debug_flag ...
- Android开发技巧——写一个StepView
在我们的应用开发中,有些业务流程会涉及到多个步骤,或者是多个状态的转化,因此,会需要有相关的设计来展示该业务流程.比如<停车王>应用里的添加车牌的步骤. 通常,我们会把这类控件称为&quo ...
- Bootstrap和IE何时能相亲相爱啊~
公司新项目,嘚瑟了一下,用了用Bootstrap... ... 发现了一个小坑(也许只是对我而言)... ... 使用了2.x的Jquery,在chrome等高版本浏览器一切顺利... ... 然,3 ...
- vue前端开发那些事——vue开发遇到的问题
vue web开发并不是孤立的.它需要众多插件的配合以及其它js框架的支持.本篇想把vue web开发的一些问题,拿出来讨论下. 1.web界面采用哪个UI框架?项目中引用了layui框架.引入框架 ...
- 1076. Wifi密码 (15)
下面是微博上流传的一张照片:“各位亲爱的同学们,鉴于大家有时需要使用wifi,又怕耽误亲们的学习,现将wifi密码设置为下列数学题答案:A-1:B-2:C-3:D-4:请同学们自己作答,每两日一换.谢 ...