从Oracle到Elasticsearch
自己写的数据交换工具——从Oracle到Elasticsearch
自己写的数据交换工具——从Oracle到Elasticsearch
先说说需求的背景,由于业务数据都在Oracle数据库中,想要对它进行数据的分析会非常非常慢,用传统的数据仓库-->数据集市这种方式,集市层表会非常大,查询的时候如果再做一些group的操作,一个访问需要一分钟甚至更久才能响应。
为了解决这个问题,就想把业务库的数据迁移到Elasticsearch中,然后针对es再去做聚合查询。
问题来了,数据库中的数据量很大,如何导入到ES中呢?
Logstash JDBC
Logstash提供了一款JDBC的插件,可以在里面写sql语句,自动查询然后导入到ES中。这种方式比较简单,需要注意的就是需要用户自己下载jdbc的驱动jar包。
input {
jdbc {
jdbc_driver_library => "ojdbc14-10.2.0.3.0.jar"
jdbc_driver_class => "Java::oracle.jdbc.driver.OracleDriver"
jdbc_connection_string => "jdbc:oracle:thin:@localhost:1521:test"
jdbc_user => "test"
jdbc_password => "test123"
schedule => "* * * * *"
statement => "select * from TARGET_TABLE"
add_field => ["type","a"]
}
}
output{
elasticsearch {
hosts =>["10.10.1.205:9200"]
index => "product"
document_type => "%{type}"
}
}不过,它的性能实在是太差了!我导了一天,才导了两百多万的数据。
因此,就考虑自己来导。
自己的数据交换工具
思路:
- 1 采用JDBC的方式,通过分页读取数据库的全部数据。
- 2 数据库读取的数据存储成bulk形式的数据,关于bulk需要的文件格式,可以参考这里
- 3 利用bulk命令分批导入到es中
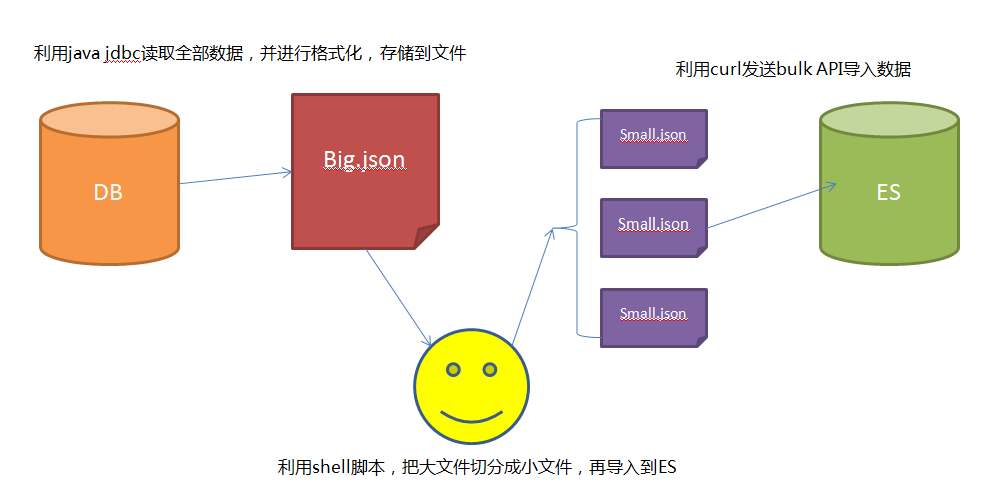
最后使用发现,自己写的导入程序,比Logstash jdbc快5-6倍~~~~~~ 嗨皮!!!!
遇到的问题
- 1 JDBC需要采用分页的方式读取全量数据
- 2 要模仿bulk文件进行存储
- 3 由于bulk文件过大,导致curl内存溢出
程序开源
下面的代码需要注意的就是
public class JDBCUtil {
private static Connection conn = null;
private static PreparedStatement sta=null;
static{
try {
Class.forName("oracle.jdbc.driver.OracleDriver");
conn = DriverManager.getConnection("jdbc:oracle:thin:@localhost:1521:test", "test", "test123");
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}
System.out.println("Database connection established");
}
/**
* 把查到的数据格式化写入到文件
*
* @param list 需要存储的数据
* @param index 索引的名称
* @param type 类型的名称
* @param path 文件存储的路径
**/
public static void writeTable(List<Map> list,String index,String type,String path) throws SQLException, IOException {
System.out.println("开始写文件");
File file = new File(path);
int count = 0;
int size = list.size();
for(Map map : list){
FileUtils.write(file, "{ \"index\" : { \"_index\" : \""+index+"\", \"_type\" : \""+type+"\" } }\n","UTF-8",true);
FileUtils.write(file, JSON.toJSONString(map)+"\n","UTF-8",true);
// System.out.println("写入了" + ((count++)+1) + "[" + size + "]");
}
System.out.println("写入完成");
}
/**
* 读取数据
* @param sql
* @return
* @throws SQLException
*/
public static List<Map> readTable(String tablename,int start,int end) throws SQLException {
System.out.println("开始读数据库");
//执行查询
sta = conn.prepareStatement("select * from(select rownum as rn,t.* from "+tablename+" t )where rn >="+start+" and rn <"+end);
ResultSet rs = sta.executeQuery();
//获取数据列表
List<Map> data = new ArrayList();
List<String> columnLabels = getColumnLabels(rs);
Map<String, Object> map = null;
while(rs.next()){
map = new HashMap<String, Object>();
for (String columnLabel : columnLabels) {
Object value = rs.getObject(columnLabel);
map.put(columnLabel.toLowerCase(), value);
}
data.add(map);
}
sta.close();
System.out.println("数据读取完毕");
return data;
}
/**
* 获得列名
* @param resultSet
* @return
* @throws SQLException
*/
private static List<String> getColumnLabels(ResultSet resultSet)
throws SQLException {
List<String> labels = new ArrayList<String>();
ResultSetMetaData rsmd = (ResultSetMetaData) resultSet.getMetaData();
for (int i = 0; i < rsmd.getColumnCount(); i++) {
labels.add(rsmd.getColumnLabel(i + 1));
}
return labels;
}
/**
* 获得数据库表的总数,方便进行分页
*
* @param tablename 表名
*/
public static int count(String tablename) throws SQLException {
int count = 0;
Statement stmt = conn.createStatement(ResultSet.TYPE_SCROLL_INSENSITIVE, ResultSet.CONCUR_UPDATABLE);
ResultSet rs = stmt.executeQuery("select count(1) from "+tablename);
while (rs.next()) {
count = rs.getInt(1);
}
System.out.println("Total Size = " + count);
rs.close();
stmt.close();
return count;
}
/**
* 执行查询,并持久化文件
*
* @param tablename 导出的表明
* @param page 分页的大小
* @param path 文件的路径
* @param index 索引的名称
* @param type 类型的名称
* @return
* @throws SQLException
*/
public static void readDataByPage(String tablename,int page,String path,String index,String type) throws SQLException, IOException {
int count = count(tablename);
int i =0;
for(i =0;i<count;){
List<Map> map = JDBCUtil.readTable(tablename,i,i+page);
JDBCUtil.writeTable(map,index,type,path);
i+=page;
}
}
}在main方法中传入必要的参数即可:
public class Main {
public static void main(String[] args) {
try {
JDBCUtil.readDataByPage("TABLE_NAME",1000,"D://data.json","index","type");
} catch (SQLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}这样得到bulk的数据后,就可以运行脚本分批导入了。
下面脚本的思路,就是每100000行左右的数据导入到一个目标文件,使用bulk命令导入到es中。注意一个细节就是不能随意的切分文件,因为bulk的文件是两行为一条数据的。
#!/bin/bash
count=0
rm target.json
touch target.json
while read line;do
((count++))
{
echo $line >> target.json
if [ $count -gt 100000 ] && [ $((count%2)) -eq 0 ];then
count=0
curl -XPOST localhost:9200/_bulk --data-binary @target.json > /dev/null
rm target.json
touch target.json
fi
}
done < $1
echo 'last submit'
curl -XPOST localhost:9200/_bulk --data-binary @target.json > /dev/null最后执行脚本:
sh auto_bulk.sh data.json自己测试最后要比logstasj jdbc快5-6倍。
从Oracle到Elasticsearch的更多相关文章
- Oracle和Elasticsearch数据同步
Python编写Oracle和Elasticsearch数据同步脚本 标签: elasticsearchoraclecx_Oraclepython数据同步 Python知识库 一.版本 Pyth ...
- 自己写的数据交换工具——从Oracle到Elasticsearch
先说说需求的背景,由于业务数据都在Oracle数据库中,想要对它进行数据的分析会非常非常慢,用传统的数据仓库-->数据集市这种方式,集市层表会非常大,查询的时候如果再做一些group的操作,一个 ...
- 《死磕 Elasticsearch 方法论》:普通程序员高效精进的 10 大狠招!(完整版)
原文:<死磕 Elasticsearch 方法论>:普通程序员高效精进的 10 大狠招!(完整版) 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链 ...
- ElasticSearch基础学习(SpringBoot集成ES)
一.概述 什么是ElasticSearch? ElasticSearch,简称为ES, ES是一个开源的高扩展的分布式全文搜索引擎. 它可以近乎实时的存储.检索数据:本身扩展性很好,可以扩展到上百台服 ...
- Open Source
资源来源于http://www.cnblogs.com/Leo_wl/category/246424.html RabbitMQ 安装与使用 摘要: RabbitMQ 安装与使用 前言 吃多了拉就是队 ...
- Logstash同步Oracle数据到ElasticSearch
最近在项目上应用到了ElasticSearch和Logstash,在此主要记录了Logstash-input-jdbc同步Oracle数据库到ElasticSearch的主要步骤,本文是对环境进行简单 ...
- oracle或mysql定时增量更新索引数据到Elasticsearch
利用kettle Spoon从oracle或mysql定时增量更新数据到Elasticsearch https://blog.csdn.net/jin110502116/article/details ...
- 将Oracle中的数据放入elasticsearch
package com.c4c.test; import java.sql.Connection; import java.sql.DriverManager; import java.sql.Res ...
- Elasticsearch 2.3.2 从oracle中同步数据
Elasticsearch 2.3.2 从oracle中同步数据 1 数据批量导入-oracle 采用 elasticsearch-jdbc 插件 安装.版本需要ES版本一致 最新 ...
随机推荐
- oracle 12.1.0.2中对象锁对系统的较大影响
环境:oracle 12.1.0.2 rac ,4节点 一.概述 通常来说,如果是oltp应用,那么部署在rac上,是不错的注意. 但实现情况中,往往是混合类型,既有OLTP也有OLAP. 如果没有 ...
- MySQL数据库常见报错原因
1.启动数据库时报错 启动 # /etc/init.d/mysqld start Starting MySQL.Logging to '/application/mysql-5.6.36/data/m ...
- Lavavel5.5源代码 - Pipeline
<?php class Pipeline { protected $passable; protected $pipes = []; protected $method = 'handle'; ...
- 误删 EhCache 中的数据?
最近遇到一个问题:在使用ehcache时,通过CacheManager.getCache(chachename).get(key),获取相应的缓存内对象(当时这个对象是个list), 有个同事写个方法 ...
- ecshop漏洞修复 以及如何加固ecshop网站安全?
由于8月份的ECSHOP通杀漏洞被国内安全厂商爆出后,众多使用ecshop程序源码的用户大面积的受到了网站被篡改,最明显的就是外贸站点被跳转到一些仿冒的网站上去,导致在谷歌的用户订单量迅速下降,从百度 ...
- C++代码理解 (强制指针转换)
#include<iostream> using namespace std; class A { public: A() { a=; b=; c=; f=; } private: int ...
- 016---Django的ModelForm
对于forms组件虽然可以帮我们渲染html页面,也可以做校验,但是,保存到数据库要取各字段的值,还要手动保存.所以引入了一个新的组件 这是一个神奇的组件,通过名字我们可以看出来,这个组件的功能就是把 ...
- 【NOIP-2017PJ】图书管理员
图书管理员 题目描述 图书馆中每本书都有一个图书编码,可以用于快速检索图书,这个图书编码是一个 正整数. 每位借书的读者手中有一个需求码,这个需求码也是一个正整数.如果一本书的图 书编码恰好以读者的需 ...
- SELECT(データ取得)
WHERE 句は.満たすべき条件を指定することにより選択される行数を制限します. WHERE 句は.SELECT 命令と同様に OPEN CURSOR.UPDATE.および DELETE 命令でも使用 ...
- react ant-design自定义图标
ant-design给我们提供的图标不够怎么办呢?答案是我们可以自定义图标. 自定义图标也挺简单的,现在图标推荐用svg格式,那么我们就需要制作svg图片. 下面让我们看看如果制作svg图片吧. 1. ...