MySQL 8.0 中统计信息直方图的尝试
直方图是表上某个字段在按照一定百分比和规律采样后的数据分布的一种描述,最重要的作用之一就是根据查询条件,预估符合条件的数据量,为sql执行计划的生成提供重要的依据
在MySQL 8.0之前的版本中,MySQL仅有一个简单的统计信息却没有直方图,没有直方图的统计信息可以说是没有任何意义的。
MySQL 8.0新特性之一就是开始支持统计信息的直方图,这个概念很早就提出来了,抽空具体尝试了一下使用方法。
之前写过MSSQL相关统计信息的一点东西,在原理上都是一致的,https://www.cnblogs.com/wy123/p/5875237.html
照旧,直接上例子,造数据,创建一个测试环境
create table test
(
id int auto_increment primary key,
name varchar(100),
create_date datetime ,
index (create_date desc)
); USE `db01`$$ DROP PROCEDURE IF EXISTS `insert_test_data`$$ CREATE DEFINER=`root`@`%` PROCEDURE `insert_test_data`()
BEGIN
DECLARE v_loop INT;
SET v_loop = 100000;
WHILE v_loop>0 DO
INSERT INTO test(NAME,create_date)VALUES (UUID(),DATE_ADD(NOW(),INTERVAL -RAND()*100000 MINUTE) );
SET v_loop = v_loop - 1;
END WHILE;
END$$ DELIMITER ;
MySQL中统计信息的创建,不同于MSSQL,MySQL统计信息不依赖于索引,需要单独创建,语法如下
--创建字段上的统计直方图信息
ANALYZE TABLE test UPDATE HISTOGRAM ON create_date,name WITH 16 BUCKETS;
--删除字段上的统计直方图信息
ANALYZE TABLE test DROP HISTOGRAM ON create_date
1,可以一次性创建多个字段的统计信息,系统会逐个创建列出的字段上的统计信息,统计信息不依赖于索引,这一点与MSSQL不同(当然MSSQL也可以抛开索引独立创建统计信息)
2,BUCKETS值是一个必须提供的参数,默认值为100,范围是1-1024,这一点也不同与MSSQL也不一样,MSSQL是有一个类似的最大值为200的步长(step)字段
3,一般来说,数据量较大的情况下,对于不重复或者重复性不高的数据,BUCKETS值越大,描述出来的统计信息越详细
4,统计信息的具体内容在 information_schema.column_statistics中,但是可读性并不好,可以根据需求自行解析(出来一种自己喜欢的格式)
与sqlserver中的统计信息一样,理论上,在准确性与取样百分比(BUCKETS)是成正比的,当然生成统计信息的代价也就越大,
至于BUCKETS与统计信息的取样百分比,以及综合代价,笔者暂时没有找到相关的资料。
如下是通过ANALYZE TABLE test UPDATE HISTOGRAM ON create_date WITH 4 BUCKETS;创建的统计信息直方图
可以发现直方图的HISTOGRAM字段是一个JSON格式的字符串,可读性并不好。
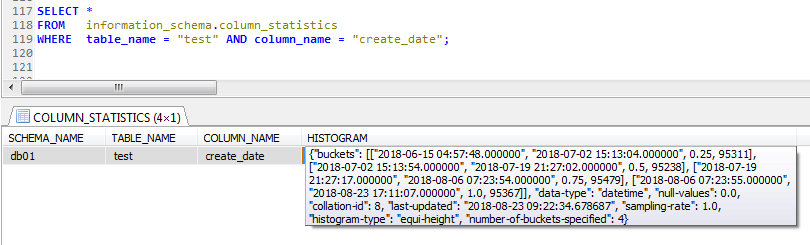
想到了sqlserver中DBCC SHOW_STATISTICS的直方图信息,如下的格式,直方图中的数据分布情况看起来非常清晰直观
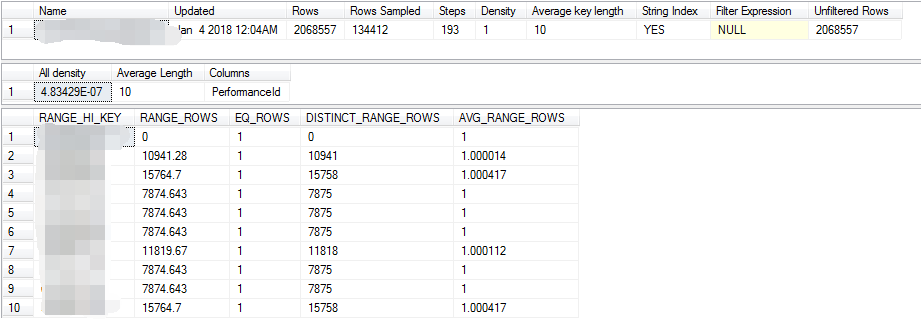
于是就做了一个MySQL直方图的格式转换,说白了就是解析information_schema.column_statistics表中的HISTOGRAM 字段中的JSON内容
如下,一个简单的解析直方图统计信息json数据的存储过程,参数分别是库名,表名,字段名
DELIMITER $$ USE `db01`$$ DROP PROCEDURE IF EXISTS `parse_column_statistics`$$ CREATE DEFINER=`root`@`%` PROCEDURE `parse_column_statistics`(
IN `p_schema_name` VARCHAR(200),
IN `p_table_name` VARCHAR(200),
IN `p_column_name` VARCHAR(200)
)
BEGIN DECLARE v_histogram TEXT;
-- get the special HISTOGRAM
SELECT HISTOGRAM->>'$."buckets"' INTO v_HISTOGRAM
FROM information_schema.column_statistics
WHERE schema_name = p_schema_name
AND table_name = p_table_name
AND column_name = p_column_name; -- remove the first and last [ and ] char
SET v_histogram = SUBSTRING(v_HISTOGRAM,2,LENGTH(v_HISTOGRAM)-2);
DROP TABLE IF EXISTS t_buckets ;
CREATE TEMPORARY TABLE t_buckets
(
id INT AUTO_INCREMENT PRIMARY KEY,
buckets_content VARCHAR(500)
); -- split by "]," and get single bucket content
WHILE (INSTR(v_histogram,'],')>0) DO
INSERT INTO t_buckets(buckets_content)
SELECT SUBSTRING(v_histogram,1,INSTR(v_histogram,'],'));
SET v_HISTOGRAM = SUBSTRING(v_histogram,INSTR(v_histogram,'],')+2,LENGTH(v_histogram));
END WHILE;
INSERT INTO t_buckets(buckets_content)
SELECT v_histogram; -- get the basic statistics data
WITH cte AS
(
SELECT
HISTOGRAM->>'$."last-updated"' AS last_updated,
HISTOGRAM->>'$."number-of-buckets-specified"' AS number_of_buckets_specified
FROM INFORMATION_SCHEMA.COLUMN_STATISTICS
WHERE schema_name = p_schema_name
AND table_name = p_table_name
AND column_name = p_column_name
)
SELECT
CASE WHEN id = 1 THEN p_schema_name ELSE '' END AS schema_name,
CASE WHEN id = 1 THEN p_table_name ELSE '' END AS table_name,
CASE WHEN id = 1 THEN p_column_name ELSE '' END AS column_name,
CASE WHEN id = 1 THEN last_updated ELSE '' END AS last_updated,
CASE WHEN id = 1 THEN number_of_buckets_specified ELSE '' END AS 'number_of_buckets_specified' ,
id AS buckets_specified_index,
buckets_content
FROM
(
SELECT * FROM cte,t_buckets
)t; END$$ DELIMITER ;
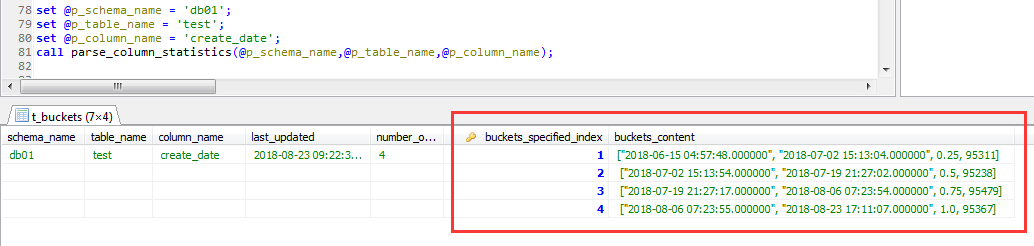
于是,第一个截图中的结果就转换为了如下的格式
这里刻意按照4个buckets生成的直方图,应该来说足够简单了,熟悉MSSQL直方图同学,应该一眼就可以看明白这个直方图的含义(测试数据量是400,000)
以第一个bucket为例:["2018-06-15 04:57:48.000000", "2018-07-02 15:13:04.000000", 0.25, 95311]
很明显,
1,"2018-06-15 04:57:48.000000"和"2018-07-02 15:13:04.000000"是类似于sqlserver中直方图中的下限值与上限值
2,0.25小于bucket的值的比例(也就小于这个区间上限制值的比例)
3,95311是这个区间的字段值不重复的行数。
到最后一个bucket,采样率必然是1,也就是100%
需要注意的是,直方图的更新时间是标准时间(UTC value),而不是服务器当前时间。
MySQL 8.0中的直方图基本上与sqlserver的直方图一致,都是基于单列的抽样预估,但是MySQL直方图中没有类似于sqlserver中的字段选择性,
不过这个字段选择性本身意义也不大 ,sqlserver中对于复合索引,两个字段合计在一块统计,除非两个字段的同时分布的都很均匀,否则多字段索引的字段选择性参考意义不大。
这也是复合索引无法做到较为精确预估的原因。
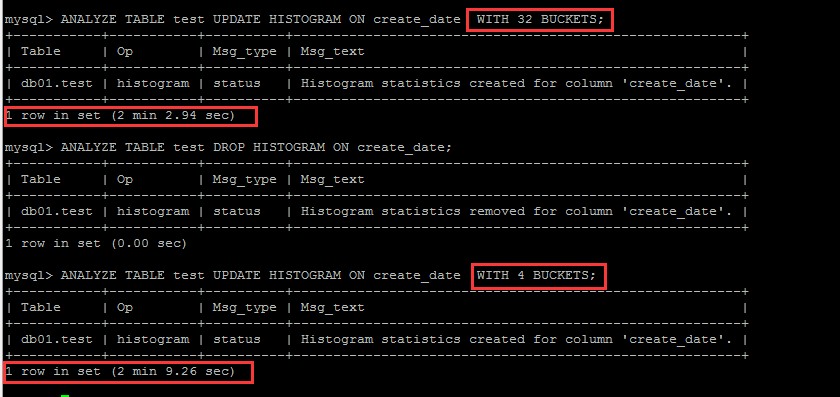
ANALYZE TABLE t1 UPDATE HISTOGRAM ON create_date WITH 1024 BUCKETS;
ANALYZE TABLE t1 DROP HISTOGRAM ON create_date; SET @p_schema_name = 'db01';
SET @p_table_name = 't1';
SET @p_column_name = 'create_date'; CALL parse_column_statistics(@p_schema_name,@p_table_name,@p_column_name)
存在的疑问?
之前写过一点MySQL统计信息的,不过是在MySQL5.7下面,还没有直方图的概念https://www.cnblogs.com/wy123/p/6561517.html
触发统计信息更新的变量还是set global innodb_stats_on_metadata = 1;但是经测试,统计信息的直方图并没有因此而更新。
innodb_stats_on_metadata在MySQL5.7中影响到的是MySQL的索引上的统计信息,而这里纯粹是统计信息的直方图(MySQL 8.0中直方图跟索引没有必然的关系)。
另外,这里经过反复测试发现,buckets的数据量,与生成直方图的效率并没有非常明显的关系,如下截图,也并不清楚,buckets数量跟取样百分比有什么关系。
又仔细看了一下参考链接的内容,发现这么一段话:
- Maintaining an index has a cost. If you have an index, every INSERT/UPDATE/DELETE causes the index to be updated. This is not free, and will have an impact on your performance. A histogram on the other hand is created once and never updated unless you explicitly ask for it. It will thus not hurt your INSERT/UPDATE/DELETE-performance.
它本身是说明索引与直方图之间的关系的,提到直方图创建之后并不会自动更新,除非主动更新。
不得不吐槽的就是,如果我在某个字段上创建了一个索引,还需要顺便在创建一个统计信息直方图?并且这个直方图并不会随着数据的变化自动更新,还需要手动更新。
MySQL 8.0中会不会把统计信息和索引关联起来,或者根据需要自动创建统计信息,如果统计信息做不到自动更新,基本上可以认为是残废的统计信息了。
关于生成直方图中时的资源的消耗
直方图的生成是一个比较消耗资源的过程的,如下是在反复测试创建直方图的过程中,zabbix监控到的服务器的CPU使用情况,当然,这里仅仅观察了一下CPU使用率的问题。
因此,直方图再好,真要大规模应用的使用,还是要综合考量的,在什么时候执行更新,以及怎么去触发它的更新。

这里仅仅是粗浅尝试,难免有很多认识不足的地方。
一些有意思的东西
本文最后给出的参考链接中发现一些有意思的东西
MySQL 8.0中一些有意思的预估算法,看来看去,跟sqlserver中的差别不大,都是类似大概这几种算法,算是没有办法的办法了。
对于两个谓词结合在一起时候的预估,或者是没有统计信息覆盖的预估,基本上可以认为是瞎蒙的,因此上文中也提到,多个谓词结合起来的选择性,没有什么意义。
------------------------------------
AND : P(A and B) = P(A) * P(B)
OR : P(A or B) = P(A) + P(B) - P(A and B)
= : 1/10
<,> : 1/3
BETWEEN : 1/4
IN (list) : MIN(#items_in_list * SEL(=), 1/2)
IN subq : [1]
NOT OP : 1-SEL(OP)
与此类似的,sqlserver中的预估算法:
https://www.cnblogs.com/wy123/p/5790855.html
https://www.cnblogs.com/wy123/p/6770258.html
https://www.cnblogs.com/wy123/p/6008477.html
参考:
https://mysqlserverteam.com/histogram-statistics-in-mysql/
https://dev.mysql.com/doc/refman/8.0/en/optimizer-statistics.html
https://dev.mysql.com/doc/refman/8.0/en/analyze-table.html#analyze-table-histogram-statistics-analysis
MySQL 8.0 中统计信息直方图的尝试的更多相关文章
- SQL Server 中统计信息直方图中对于没有覆盖到谓词预估以及预估策略的变化(SQL2012-->SQL2014-->SQL2016)
本位出处:http://www.cnblogs.com/wy123/p/6770258.html 统计信息写过几篇了相关的文章了,感觉还是不过瘾,关于统计信息的问题,最近又踩坑了,该问题虽然不算很常见 ...
- 10-SQLServer中统计信息的使用
一.总结 1.网址https://docs.microsoft.com/en-us/sql/relational-databases/system-catalog-views/sys-stats-tr ...
- MySQL 并行复制演进及 MySQL 8.0 中基于 WriteSet 的优化
MySQL 8.0 可以说是MySQL发展历史上里程碑式的一个版本,包括了多个重大更新,目前 Generally Available 版本已经已经发布,正式版本即将发布,在此将介绍8.0版本中引入的一 ...
- 牛逼!MySQL 8.0 中的索引可以隐藏了…
MySQL 8.0 虽然发布很久了,但可能大家都停留在 5.7.x,甚至更老,其实 MySQL 8.0 新增了许多重磅新特性,比如栈长今天要介绍的 "隐藏索引" 或者 " ...
- 【练习】ORACLE统计信息--直方图
①创建表tSQL> create table t as select * from dba_objects; Table created. --收集直方图 SQL> exec dbms_s ...
- Mysql 碎片整理与统计信息收集
======重新收集统计信息======= 1.分析和存储表的关键字分布 analyze table table_name; analyze 用于收集优化器的统计信息.和tuning相关:对 myis ...
- MySQL数据库(4)----生成统计信息
MySQL最有用的一项功能就是,能够对大量原始数据进行归纳统计. 1.在一组值里把各个唯一的值找出来,这是一项典型的统计工作,可以使用DISTINCT 关键字清楚查询结果里重复出现的行.例如,下面的查 ...
- mysql查看表中列信息
查看所有数据库中所有表的数据库名和表名 SELECT `TABLES`.`TABLE_SCHEMA`, `TABLES`.`TABLE_NAME` FROM `information_schema`. ...
- MYSQL 提取时间中的信息的 4 方法
方法 1. year(),month(),day() 方法 2. dayofweek(),dayofmonth(),dayofyear(); 方法 3. hour(),minute(),second( ...
随机推荐
- 17.2 SourceInsight批量注释
将下面的代码保存为codecomm.em并添加到工程,在Options->Menu Assignments中就可以看到这个宏macro CodeComments,给这个宏添加热键. 执行一次Ct ...
- Win32-Application的窗口和对话框
Win32 Application,没有基于MFC的类库,而是直接调用C++接口来编程. 一.弹出消息窗口 (1)最简单的,在当前窗口中弹出新窗口.新窗口只有“YES”按钮. int APIENTRY ...
- Some elementary algorithms on discrete differential geometry(DDGSpring2016 Demos)
I studied the on-line course(http://brickisland.net/DDGSpring2016/) by myself, and here are the scre ...
- Ubuntu14.04+ROS 启动本地摄像头
STEP1安装usb_cam 创建一个工作空间,make一下 mkdir -p ~/catkin_ws/src cd ~/catkin_ws/ catkin_make STEP2下面是安装usb_c ...
- HP880G3 安装RHEL6.5
###关于读不到网卡驱动的问题 HP 880G3 在安装系统的时候会提示acpi错误 需要按F9 选择 lency开头走U盘安装系统 进入安装界面按tab 输入 acpi=off 这样就可以安装了 ...
- Python【每日一问】15
问:简述with方法打开处理文件实际上做了哪些工作 答: filename= "test.txt" with open(filename, "w", encod ...
- Java读取Excel并与SqlServer库中的数据比较
先说说需求.在SQL server数据库中的表里存在一些数据,现在整理的Excel文档中也存在一些数据,现在需要通过根据比较某个字段值(唯一)来判断出,在库中有但excel中没有的数据. 大概的思路就 ...
- MySQL 错误集-汇总
Q&A: MySQl报错之@@GLOBAL.GTID_PURGED can only be set when @@GLOBAL.GTID_MODE = ON 导入的时候加入-f参数即可 原因分 ...
- Mock测试接口
Mock使用场景: (1)创建所需的DB数据可能需要很长时间,如:调用别的接口,模拟很多数据,确保发布版本接口可用 (2)调用第三方API接口,测试很慢, (3)编写满足所有外部依赖的测试可能很复杂, ...
- RMAN-06900 RMAN-06901 ORA-19921
转自http://blog.itpub.net/12778571/viewspace-700360/ 1.连接到rman中$ rman target/Recovery Manager: Release ...