Anatomy of a Database System学习笔记 - 概论、并发控制
《Anatomy of a Database System》这篇发表于87年、一共48页的论文据说是DBA入门必看,但是找了全网没有找到中文翻译。这篇文章对关系型数据库确实有提纲挈领的作用,看完能带来融会贯通的感觉,值得抄写一遍,如有任何抄写不当的地方请诸位看官留言。
1. 文章结构
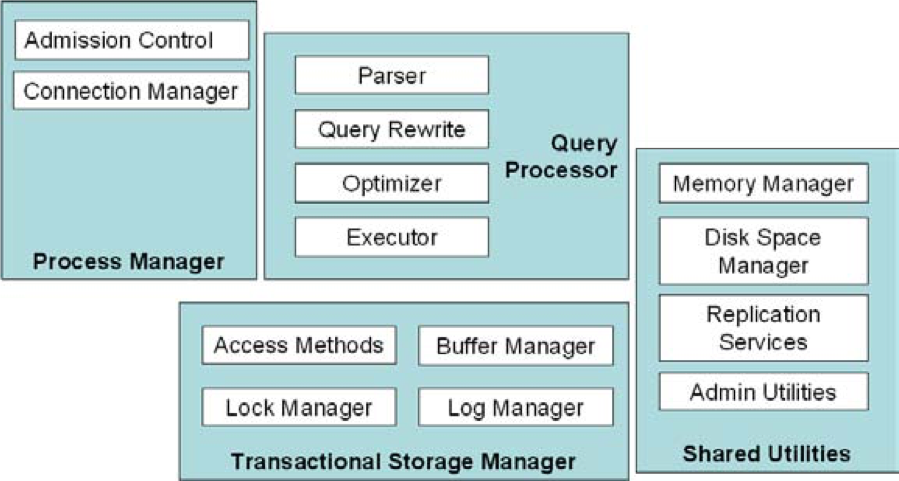
2. Process Manager
这一章讲数据库的并发模型,稍微翻下chap2的图片就能明白,下面只简要贴出自己感兴趣的部分:
2.1 各并发模型对比

2.2 线程间传递数据
理想的服务器处理架构有非阻塞异步I/O、有dispatcher threads将客户端连接分发给worker threads,这就引来一个问题:数据如何在进程货线程间传递?答案通常是:使用buffer。
| buffer类型 | 描述 | |
| Disk I/Obuffer |
1. 来自DB的I/O请求:缓冲池 |
|
| Client communication buffer |
适用于pull模型,客户端主动拉取。一笔查询的worker thread包含指向结果队列的指针: |
2.3 数据库线程与OS处理器的映射
大多数DB起源于70年代,商业化于80年代,很多OS特性在当时是不支持的,例如文件系统缓冲控制、异步I/O;还有就是以前的OS线程包并不高效。出于这些历史遗留、移植性、性能等考虑,很多DB自己做了操作系统应该做的事情,例如非阻塞的异步接口(用来处理慢任务如I/O)、事件流编程、任务切换、线程状态管理、调度等。然而,使用DB级的线程包引出一些设计问题:给定的DB线程组,应该有多少个OS处理器?那些DB任务需要有单独的线程?如何给线程分配处理器?
为了讨论以上问题,首先将问题简化为:只有DB线程和OS处理器两个单元参与、没有OS线程支持的情况。这种情况下DB包含以下处理器:
- 1-n个processes给SQL处理线程,通常dba可调。
- 1-n个dispatcher processes。监听网络端口、分发连接请求给其他process的线程、为连接创建session,通常dba可调。
- 与数据库磁盘数对应的I/O proccesses。如果OS不支持异步I/O,需要数据库为每个数据库磁盘起一个process来处理I/O请求。
- 与log磁盘数对应的I/O processes。如3。
- 与client session数对应的调度器代理process。有的系统中,需要为client session分配一个处理器来维护session状态、处理客户通信;有的系统中,不需要分配处理器,有单独的数据结构供db线程访问就行了。
- 后台工具。如统计、监控、日志归档、物理结构优化,每个任务,由调度器动态的启一个专门处理器。
现代操作系统的线程切换仍然比DB希望的还有重量级,但是多处理器下效率比古典操作系统有很多提升。历史上看,DB首先是多进程单线程的,后来随着OS多线程能力的提升DB将多进程改为多线程,这样的好处是编程方便。当代DB“ are written in this manner, and can be run over either processes or threads.”,把线程视为可调度单元。那么为什么还有现代DB还坚持着多进程的并发模型呢?当前的硬件,例如x86的Linux一个进程只能支持到3GB ram,多进程可以减轻这个问题。
例举几种数据库的并发模型
| Oracle | DB2 | SQL Server | |
| Unix环境 | Process-Per-User | Process-Per-User | 不支持 |
| Window环境 | 以线程为调度单元 | 以线程为调度单元 | thread-per-session,但是thread可复用 |
2.4 并发、进程模型、内存协调
| 描述 | pros | cons | |
| shared memory | 由于OS通常支持可调度单元(线程或进程)在多处理器之间的透明调度,且共享内存可全部被读到 | 简便 | 硬件行业摇钱树 |
| shared Nothing |
由PC机(一般是刀片)组成;某CPU不能直接访问另一个CPU的内存或磁盘;由于便宜、扩展性好,这类机器常用于数据仓库; |
便宜、扩展性好 |
贵,因为license按软件包收费,例如IBM SP2、NCR WorldMark机器; |
| shared disk |
single-box数据库,分布式部署在多台服务器上。随着NAS的流行,这种数据库也流行开来。 |
1. 比起shared nothing,DBA不需要考虑数据分片; |
数据的共享需要软件去协调:所有节点都能从磁盘拷贝到自己内存,都有自己的锁、buffer pool页。因此至少需要: |
| NUMA |
在NUMA架构中,每个Node有多个Core,Node内CPU与内存通过片内总线连接,Node间通过互联网模块进行连接。每个core地位是平等的,都可以访问所有内存,访问其它节点内存耗时用node-distance衡量,一般比访问本机慢3倍。IBM这类厂商提供NUMA架构的机器。 |
所有数据库都被NUMA坑过,例如MySQL swap insanity,其原因基本上“CPU亲和策略导致内存分配不均”或者“NUMA Zone Clain内存回收” |
2.5 准入控制
“如何支持并发的请求”。为什么说准入控制是必要的?因为当负载拆过临界点后,系统就会开始抖动,从OS层面看,抖动多数情况由DBMS的buffer pool不停换入换出导致的,DBMS在执行排序、hash join,或者锁竞争、事务死锁的情况下尤其消耗内存。 准入控制可以使服务优雅降级:事务延迟会随着请求速率慢慢降低,但系统吞吐量维持在峰值。
如何做DB准入控制?
1. 限流。要求dispatcher进程保障客户连接数载某个数字以内,这样既可以保证不过度消耗网络连接资源,也可以使查询解析器和查询优化器掉用量比较小。有些DB把这个功能甩锅给其它应用,如应用服务器、事务监视器TPM、Web服务器。
2. 执行准入控制器execution admission controller,需要再DBMS查询处理器内部实现。执行控制器用于决策一个查询要立即执行还是延迟执行,是在查询被解析、优化后调用的,因为它需要优化器产生的查询计划里的信息来估算资源,这些信息包括:
2.1 有哪些磁盘访问
2.2 每块设备的随机/次序IO的预期CPU负载
2.3 查询内存占用,尤其是排序和hash表 ***
2.3是execution admission controller最重要的决策信息,因为内存压力才是抖动的主要原因。
2.6 小结
1. 当代DBMS既有Process-per-User又有“Server process”模型。前者简单;后者可支持更高性能。
2. 有些DBMS自己实现了线程包(如Oracle、Informix),因此以线程为可调度单元。
3. 不同OS上可调度单元不同,有的OS以进程为可调度单元,有的OS以单进程内的线程为可调度单元。
并发架构上,市面上有Shared-Nothing、Shared-Memory和Shared-Disk的架构。其中,Shared-nothing善于高性价比的处理海量数据的复杂查询,因此在协作决策支持系统中占据高端地位;其它两种善于处理多个小事务。将单处理器DB应用到shared-nothing架构难度较高,很多数据库公司宁愿直接开发新产品线,如Oracle直接不支持Shared-Nothing架构。


Anatomy of a Database System学习笔记 - 概论、并发控制的更多相关文章
- Anatomy of a Database System学习笔记 - 查询
查询解析 解析会生成一个查询的内部展示.格式检查包含在解析过程中. 每次解析一个SELECT,步骤如下:1. 从FROM里找到表名,转换成schema.tablename.这一步需要调用目录管理器ca ...
- Anatomy of a Database System学习笔记 - 公共模块、结语
公共模块 1. 使用基于上下文的内存分配器进行内存分配 除了教材里常提到的buffer pool,数据库还会为其他任务分配大量内存,例如,Selinger-style查询优化需要动态的规划查询:has ...
- Anatomy of a Database System学习笔记 - 事务:并发控制与恢复
这一章看起来是讲存储引擎的.作者抱怨数据库被黑为“monolithic”.不可拆分为可复用的组件:但是实际上除了事务存储引擎管理模块,其他模块入解析器.重写引擎.优化器.执行器.访问方式都是代码相对独 ...
- Anatomy of a Database System学习笔记 - 存储管理
使用裸设备,还是使用文件系统? 描述 pros cons 裸设备 顺序读磁盘快比随机要快10-100倍,DB比OS更懂磁盘负载,因此很多DB是直接管理数据块如何存放的. DB对裸设备的管理,比文件 ...
- A.Kaw矩阵代数初步学习笔记 5. System of Equations
“矩阵代数初步”(Introduction to MATRIX ALGEBRA)课程由Prof. A.K.Kaw(University of South Florida)设计并讲授. PDF格式学习笔 ...
- Deap Learning (吴恩达) 第一章深度学习概论 学习笔记
Deap Learning(Ng) 学习笔记 author: 相忠良(Zhong-Liang Xiang) start from: Sep. 8st, 2017 1 深度学习概论 打字太麻烦了,索性在 ...
- system generator学习笔记【02】
作者:桂. 时间:2018-05-20 23:28:04 链接:https://www.cnblogs.com/xingshansi/p/9059668.html 前言 继续学习sysgen.接触s ...
- System类学习笔记
最近在学习源码的过程中发现:很多深层次的代码都用到了一个类System类,所以决定对System类一探究竟 本文先对System类进行了剖析,然后对System类做了总结 一.首先对该类的中的所有字段 ...
- 学习笔记之操作系统(Operating System)
学习笔记之多线程 - 浩然119 - 博客园 https://www.cnblogs.com/pegasus923/p/5554565.html 用三个线程按顺序循环打印ABC三个字母 - 浩然119 ...
随机推荐
- Sails -初级学习配置
新建一个命名为sails的文件夹1.安装 npm -g install sails || cnpm -g install sails 注意:安装必须是全局安装 cnpm install sails - ...
- 1.继承(extends)、超类(superClass)、子类(subClass)
注意:继承主要使用的is-a关系 在子类中用一个新的方法来覆盖超类中的方法(override),需要注意的是如果子类之中的方法或者域 被覆盖时,仍然想访问superClass中的方法和域,此时必须使 ...
- STM8L LCD配置与com使用问题
void LCD_GPIO_Config(void) { //SEG GPIO Init GPIO_Init(GPIOE, GPIO_Pin_0|GPIO_Pin_1,GPIO_Mode_Out_PP ...
- vpdn1
在使用L2TP协议构建的VPDN典型组网中,包含LAC和LNS两部分. 1.LAC LAC表示L2TP访问集中器(L2TP Access Concentrator),是附属在交换网络上的具有PPP端系 ...
- 单线拨号上网时RouterOS内网端口映射的配置
很多时候routeros 是通过单线拨号上网,假设PPP接口名为pppoe-out1 若需要添加内网ip=18.16.1.92主机的3389端口映射 ,可以在命令行键入: ip firewall na ...
- 【mysql】Mha实现高可用数据库架构
MySQL高可用平台需要达到的目标有以下几点: 1.数据一致性保证这个是最基本的同时也是前提,如果主备的数据的不一致,那么切换就无法进行,当然这里的一致性也是一个相对的,但是要做到最终一致性. 2.故 ...
- 创建一个dynamics 365 CRM online plugin (六) - Delete plugin from CRM
我们之前都学习到怎么添加,debug还有update plugin. 今天带大家过一下怎么从CRM instance当中删除plugin. 首先让我们打开Settings -> Customiz ...
- layui layui.open弹窗后按enter键不停弹窗问题的解决
问题描述:layui.open弹窗后,点击enter键会不停弹窗,背景颜色变得越来越深 解决办法:1.使用回调函数让按钮失去焦点 var info = layer.open({ type: 2 , t ...
- imp 导入以及换用户报错
数据库导入操作:SQL> create user user identified by passwd; SQL> create tablespace user datafile '/dat ...
- 如何创建 SVN 服务器,并搭建自己的 SVN 仓库 如何将代码工程添加到VisualSVN Server里面管理
如何创建 SVN 服务器,并搭建自己的 SVN 仓库,附链接: https://jingyan.baidu.com/article/6b97984dca0d9c1ca3b0bf40.html 如何将代 ...