sql工作问题总结
1. sql排序:
1、 order by ……
2、 row_number() over(partition by …… order by ……)
使用说明:此函数适合做分组、排序,而不能在使用它分组的同时使用聚合函数
3、 嵌套查询,保持内层查询的排列顺序,可以使用rownum记录内层记录的行号,外层查询按rownum进行排序即可。(与oracle的分页查询类似)
2. 处理除数为0的情况:
1、 使用decode()函数。例:略
2、 使用nullif()函数。(推荐使用)例:min(nvl(p.vm_total_price_member / nullif(p.vm_total_price_origin, 0), 0)) as vmMinTotalPriceDiscount
说明:nullif(a,b)函数是在a==b时将a转为了null。当一个数去除以null时,得到的结果就是null。然后再用nvl()函数将null值转为0。
3. group by
在使用group by时,select能够查询出来的信息量只能是group by的字段和聚合函数中的内容。
所以有个使用小技巧:如果要查多个字段信息,但这些字段没有必要使用聚合函数来算它的值,则我们可以变相的使用 max(字段名) 来取。
注意:此种方式仅适用于一对多的情况中,取“一”方字段时,因为此时分组内“一”方的分组内的所有记录的字段都是一样的,故通过这种方法取出来的也就是我们要的数据。
4. oracle 中根据一张表快速创建另外一张表:
create table account_file_import_2 as select * from account_file_import where 1<> 1;
5. 将查询结果批量插入一张表:
insert into account_file_import_2 select * from account_file_import
6. 用一条SQL去定点批量更新多条记录
例:将coupon_order中的数据统计好后,更新到coupon表,更新的记录为coupon_order中所有的id_coupon

update coupon c
set (c.give_num, c.average_price) = (select count(1),
sum(co.average_price)
from coupon_order co
where co.status in
('未兑换', '兑换中', '已兑换')
and c.id_coupon = co.id_coupon
group by co.id_coupon) where c.id_coupon in (select id_coupon from coupon_order);
7. oracle & mysql
http://lib.csdn.net/base/oracle/structure
http://lib.csdn.net/base/mysql/structure
user_event :用户事件表
create_time :表中存储时间的字段
#获取当月数据
SELECT * FROM user_event WHERE DATE_FORMAT(create_time,'%Y-%m') = DATE_FORMAT(NOW(),'%Y-%m') #获取3月份数据
SELECT * FROM user_event WHERE DATE_FORMAT(create_time,'%Y-%m') = DATE_FORMAT('2016-03-01','%Y-%m') #获取三月份数据
SELECT * FROM user_event WHERE YEAR(create_time)='' AND MONTH(create_time)='' #获取本周数据
SELECT * FROM user_event WHERE YEARWEEK(DATE_FORMAT(create_time,'%Y-%m-%d')) = YEARWEEK(NOW()); #查询上周的数据
SELECT * FROM user_event WHERE YEARWEEK(DATE_FORMAT(create_time,'%Y-%m-%d')) = YEARWEEK(NOW())-1; #查询距离当前现在6个月的数据
SELECT * FROM user_event WHERE create_time BETWEEN DATE_SUB(NOW(),interval 6 month) and NOW(); #查询上个月的数据
SELECT * FROM user_event WHERE DATE_FORMAT(create_time,'%Y-%m')=DATE_FORMAT(DATE_SUB(CURDATE(), INTERVAL 1 MONTH),'%Y-%m')
#查询今天的信息记录:
SELECT * FROM user_event WHERE TO_DAYS(`create_time`) = TO_DAYS(NOW()); #查询昨天的信息记录:
SELECT * FROM user_event WHERE TO_DAYS(now()) - TO_DAYS(create_time) <= 1; #查询近7天的信息记录:
SELECT * FROM user_event WHERE DATE_SUB(curdate(), INTERVAL 7 DAY) <= DATE(create_time); #查询近30天的信息记录:
SELECT * FROM user_event WHERE DATE_SUB(curdate(), INTERVAL 30 DAY) <= DATE(create_time); #查询上一月的信息记录:
SELECT * FROM user_event WHERE PERIOD_DIFF(DATE_FORMAT(NOW(), '%Y%m'), DATE_FORMAT(create_time, '%Y%m')) =1;
SELECT * from (Select car_log.*,(@rowNum:=@rowNum+1) as rowNo From car_log, (Select (@rowNum :=0) ) b order by id asc) as a where mod(a.rowNo, 20) = 1
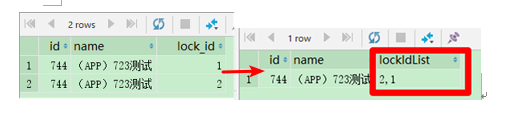
10. mysql将多条数据合并成一行
select
c.id,
c.name,
GROUP_CONCAT(bl.lock_id SEPARATOR ',') as lockIdList
from car c, box b, box_lock bl
where c.id = b.car_id
and b.id = bl.box_id
GROUP BY c.id
11. mysql中指定数据排序
SELECT * FROM user ORDER BY user_id<>7,score DESC;
主要是“user_id<>7”,就会把用户id为7的排在前面。
如果是多条数据行:
SELECT * FROM user ORDER BY user_id NOT IN(7,8,9),score DESC;
sql工作问题总结的更多相关文章
- 46、Spark SQL工作原理剖析以及性能优化
一.工作原理剖析 1.图解 二.性能优化 1.设置Shuffle过程中的并行度:spark.sql.shuffle.partitions(SQLContext.setConf()) 2.在Hive数据 ...
- 利用 Oracle EM 企业管理器 进行oracle SQL的优化(自动生成索引)
利用 Oracle EM 企业管理器 进行oracle SQL的优化(自动生成索引) ##应用情景 项目中有大量的SQL,尤其是涉及到统计报表时,表关联比较多,当初开发建表时也没搞好索引关联的,上线后 ...
- PL/SQL程序设计
1 PL/SQL简介 1 什么是PL/SQL? PL/SQL是 Procedure Language & Structured Query Language 的缩写.PL/SQL是对SQL语言 ...
- [源码分析] 带你梳理 Flink SQL / Table API内部执行流程
[源码分析] 带你梳理 Flink SQL / Table API内部执行流程 目录 [源码分析] 带你梳理 Flink SQL / Table API内部执行流程 0x00 摘要 0x01 Apac ...
- Apache Hudi集成Spark SQL抢先体验
Apache Hudi集成Spark SQL抢先体验 1. 摘要 社区小伙伴一直期待的Hudi整合Spark SQL的PR正在积极Review中并已经快接近尾声,Hudi集成Spark SQL预计会在 ...
- mysql5.5手册读书日记(3)
<?php /* MySQL_5.5中文参考手册 587开始 与GROUP BY子句同时使用的函数和修改程序 12.10.1. GROUP BY(聚合)函数 12.10.2. GROUP BY修 ...
- Mysql学习笔记(十)存储过程与函数 + 知识点补充(having与where的区别)
学习内容:存储程序与函数...这一章学的我是云里雾里的... 1.存储过程... Mysql存储过程是从mysql 5.0开始增加的一个新功能.存储过程的优点其实有很多,不过我觉得存储过程最重要的 ...
- 王家林 大数据Spark超经典视频链接全集[转]
压缩过的大数据Spark蘑菇云行动前置课程视频百度云分享链接 链接:http://pan.baidu.com/s/1cFqjQu SCALA专辑 Scala深入浅出经典视频 链接:http://pan ...
- Oracle行列互换 横表和纵表
/* 在实际使用sql工作中总会碰到将某一列的值放到标题中显示.就是总说的行列转换或者互换. 比如有如下数据: ID NAME KECHENG CHENGJI -- ---------- ------ ...
随机推荐
- PHP正则匹配邮件地址、URL
匹配邮件 #^[A-Za-z0-9]+[\w\.-]*@[A-Za-z0-9]+[A-Za-z0-9\.-]*[A-Za-z0-9]$# 注意 1. \w 表示的是 [A-Za-z0-9_] 包括下划 ...
- MongoDB管理与开发精要 书摘
摘自:<MongoDB管理与开发精要> 性能优化 创建索引 限定返回结果条数 只查询使用到的字段,而不查询所有字段 采用capped collection 采用Server ...
- 使用SQL字符串反转函数REVERSE巧妙实现lastindexof功能
要实现一个简单的业务: 使用SQL脚本获取字符串'large/020700/61970b0101.jpg' 中的'61970b0101.jpg'部分. 先想到的是C#中的lastindexof,但是S ...
- android绘画折线图一
最近需要实现用android来画折线图,所以百度了一下,发现确实很多,也很乱,现在整理两种方法(第二种方法在[android绘画折线图二]中实现),仅供大家参考,一起学习研究. 第一种使用ChartF ...
- 简单实现JS Loading功能
我们经常在浏览网页的时候会看到数据在加载时,出现的LOADING提示.其实这个功能原理是很简单的,就是一个DIV遮盖当前页面,然后Loading就在遮盖DIV层上展示出来,现在我们来动手实现一下. 1 ...
- json字符串转map
<dependency> <groupId>com.google.code.gson</groupId> <artifactId>gson</ar ...
- C语言常用的小代码
圆周率Pi tan(Pi/4)=1 => Pi=4*arctan(1) 反正切函数arctan()在C语言里表示为atan(),为保证精度取圆周率的代码如下: const double Pi = ...
- js 删除DropDownList的选项
function del_DropDownList_Option() { var ddlXZ= document.getElementById("name&quo ...
- [转]Linux环境下查看线程数的几种方法
1.cat /proc/${pid}/status 2.pstree -p ${pid} 3.top -p ${pid} 再按H,或者直接输入 top -bH -d 3 -p ${pid} top ...
- 构建VIM下的C++编程环境
1.VIM配置 Vim强大的配置与功能,其来源基本上就两个地方:Vim插件以及Vim配置文件. Vim本身的系统配置文件夹是在/usr/share/vim/和/etc/vim/两个文件夹下.一般情况下 ...