【2022知乎爬虫】我用Python爬虫爬了2300多条知乎评论!
您好,我是 @马哥python说,一枚10年程序猿。
一、爬取目标
前些天我分享过一篇微博的爬虫:
https://www.cnblogs.com/mashukui/p/16414027.html
但是知乎平台和微博平台的不同之处在于,微博平台的数据用于分析社会舆论热点事件是极好的,毕竟是个偏娱乐化的社交平台。但知乎平台的评论更加客观、讨论内容更加有深度,更加有专业性,基于此想法,我开发出了这个知乎评论的爬虫。
二、展示爬取结果
我在知乎上搜索了5个关于”考研“的知乎回答,爬取了回答下方的评论数据,共计2300+条数据。
https://www.zhihu.com/question/291278869/answer/930193847
https://www.zhihu.com/question/291278869/answer/802226501
https://www.zhihu.com/question/291278869/answer/857896805
https://www.zhihu.com/question/291278869/answer/910489150
https://www.zhihu.com/question/291278869/answer/935352960
爬取字段,含:
回答url、页码、评论作者、作者性别、作者主页、作者头像、评论时间、评论内容、评论级别。
部分数据截图:

三、爬虫代码讲解
3.1 分析知乎页面
任意打开一个知乎回答,点开评论界面:
同时打开chrome浏览器的开发者模式,评论往下翻页,就会找到目标链接:
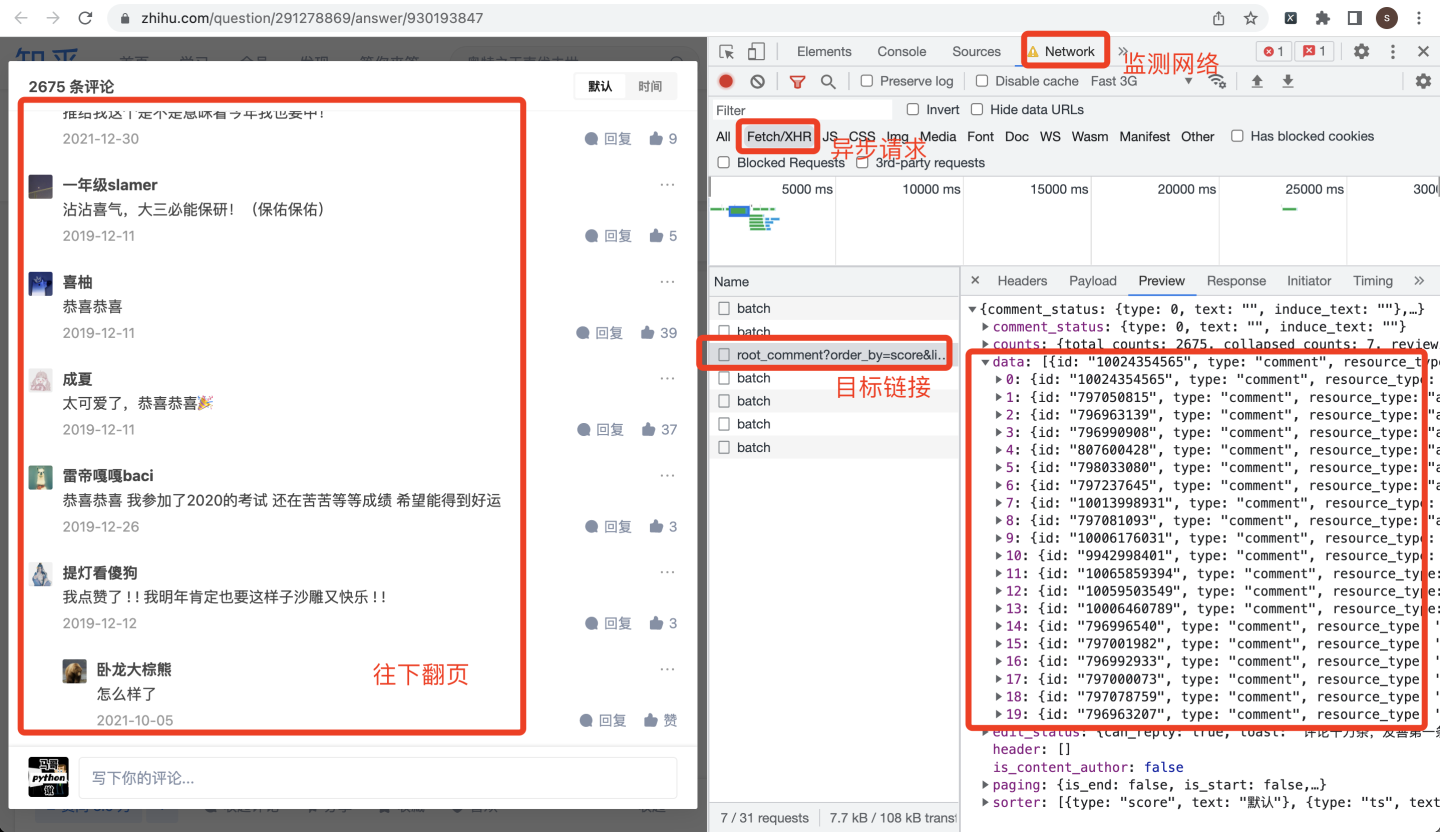
作为爬虫开发者,看到这种0-19的json数据,一定要敏感,这大概率就是评论数据了。猜测一下,每页有20条评论,逐级打开json数据:

基于此数据结构,开发爬虫代码。
3.2 爬虫代码
首先,导入用到的库:
import requests
import time
import pandas as pd
import os
从上面的截图可以看到,评论时间created_time是个10位时间戳,因此,定义一个转换时间的函数:
def trans_date(v_timestamp):
"""10位时间戳转换为时间字符串"""
timeArray = time.localtime(v_timestamp)
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
return otherStyleTime
作者的性别gender是0、1,所以也定义一个转换函数:
def tran_gender(gender_tag):
"""转换性别"""
if gender_tag == 1:
return '男'
elif gender_tag == 0:
return '女'
else: # -1
return '未知'
准备工作做好了,下面开始写爬虫。
请求地址url,从哪里得到呢?
打开Headers,找到Request URL,直接复制下来,然后替换:

先提取出一共多少评论,用于计算后面的翻页次数:
url0 = 'https://www.zhihu.com/api/v4/answers/{}/root_comments?order=normal&limit=20&offset=0&status=open'.format(answer_id)
r0 = requests.get(url0, headers=headers) # 发送请求
total = r0.json()['common_counts'] # 一共多少条评论
print('一共{}条评论'.format(total))
计算翻页次数,直接用评论总数除以20就好了:
# 判断一共多少页(每页20条评论)
max_page = int(total / 20)
print('max_page:', max_page)
下面,再次发送请求,获取评论数据:
url = 'https://www.zhihu.com/api/v4/answers/{}/root_comments?order=normal&limit=20&offset={}&status=open'.format(answer_id,str(offset))
r = requests.get(url, headers=headers)
print('正在爬取第{}页'.format(i + 1))
j_data = r.json()
comments = j_data['data']
现在,所有数据都在comments里面了,开始for循环遍历处理:
字段过多,这里以评论作者、评论性别为例,其他字段同理:
for c in comments: # 一级评论
# 评论作者
author = c['author']['member']['name']
authors.append(author)
print('作者:', author)
# 作者性别
gender_tag = c['author']['member']['gender']
genders.append(tran_gender(gender_tag))
其他字段不再赘述。
需要注意的是,知乎评论分为一级评论和二级评论(二级评论就是一级评论的回复评论),所以,为了同时爬取到二级评论,开发以下逻辑:(同样以评论作者、评论性别为例,其他字段同理)
if c['child_comments']: # 如果二级评论存在
for child in c['child_comments']: # 二级评论
# 评论作者
print('子评论作者:', child['author']['member']['name'])
authors.append(child['author']['member']['name'])
# 作者性别
genders.append(tran_gender(child['author']['member']['gender']))
待所有字段处理好之后,把所有字段的列表数据拼装到DataFrame,to_csv保存到csv文件里,完毕!
df = pd.DataFrame(
{
'回答url': answer_urls,
'页码': [i + 1] * len(answer_urls),
'评论作者': authors,
'作者性别': genders,
'作者主页': author_homepages,
'作者头像': author_pics,
'评论时间': create_times,
'评论内容': contents,
'评论级别': child_tag,
}
)
# 保存到csv文件
df.to_csv(v_result_file, mode='a+', index=False, header=header, encoding='utf_8_sig')
完整代码中还涉及到避免数据重复、字段值拼接、判断翻页终止等细节逻辑,详细了解请见文末。
四、同步视频
演示视频:
https://www.zhihu.com/zvideo/1545723927430979584
我是 @马哥python说, 感谢您的阅读。
【2022知乎爬虫】我用Python爬虫爬了2300多条知乎评论!的更多相关文章
- python爬虫-基础入门-python爬虫突破封锁
python爬虫-基础入门-python爬虫突破封锁 >> 相关概念 >> request概念:是从客户端向服务器发出请求,包括用户提交的信息及客户端的一些信息.客户端可通过H ...
- 【爬虫集合】Python爬虫
一.爬虫学习教程 1. https://www.jianshu.com/u/c32d557edfa3 2. WebMagic是一个简单灵活的Java爬虫框架.基于WebMagic,你可以快速开发出一个 ...
- 抖音爬虫教程,python爬虫采集反爬策略
一.爬虫与反爬简介 爬虫就是我们利用某种程序代替人工批量读取.获取网站上的资料信息.而反爬则是跟爬虫的对立面,是竭尽全力阻止非人为的采集网站信息,二者相生相克,水火不容,到目前为止大部分的网站都还是可 ...
- 【Python】【爬虫】如何学习Python爬虫?
如何学习Python爬虫[入门篇]? 路人甲 1 年前 想写这么一篇文章,但是知乎社区爬虫大神很多,光是整理他们的答案就够我这篇文章的内容了.对于我个人来说我更喜欢那种非常实用的教程,这种教程对于想直 ...
- Python爬虫之xpath语法及案例使用
Python爬虫之xpath语法及案例使用 ---- 钢铁侠的知识库 2022.08.15 我们在写Python爬虫时,经常需要对网页提取信息,如果用传统正则表达去写会增加很多工作量,此时需要一种对数 ...
- Python爬虫入门一之综述
大家好哈,最近博主在学习Python,学习期间也遇到一些问题,获得了一些经验,在此将自己的学习系统地整理下来,如果大家有兴趣学习爬虫的话,可以将这些文章作为参考,也欢迎大家一共分享学习经验. Pyth ...
- [python]爬虫学习(一)
要学习Python爬虫,我们要学习的共有以下几点(python2): Python基础知识 Python中urllib和urllib2库的用法 Python正则表达式 Python爬虫框架Scrapy ...
- Python爬虫入门:综述
大家好哈,最近博主在学习Python,学习期间也遇到一些问题,获得了一些经验,在此将自己的学习系统地整理下来,如果大家有兴趣学习爬虫的话,可以将这些文章作为参考,也欢迎大家一共分享学习经验. Pyth ...
- python爬虫:使用Selenium模拟浏览器行为
前几天有位微信读者问我一个爬虫的问题,就是在爬去百度贴吧首页的热门动态下面的图片的时候,爬取的图片总是爬取不完整,比首页看到的少.原因他也大概分析了下,就是后面的图片是动态加载的.他的问题就是这部分动 ...
随机推荐
- python创建分类器小结
简介:分类是指利用数据的特性将其分成若干类型的过程. 监督学习分类器就是用带标记的训练数据建立一个模型,然后对未知数据进行分类. 一.简单分类器 首先,用numpy创建一些基本的数据,我们创建了8个点 ...
- layui 数据表格 数据更新完成后数据刷新
模拟点击分页确定刷新数据 $(".layui-laypage-btn")[0].click()
- C语言学习之我见-strncat()可调整的字符串拼接函数
strncat()函数,用于两个字符串的拼接. (1)函数原型 char * strncat(char * Dest,const char * Source,size_t _Count)` (2)头文 ...
- 6000字Locust入门详解
目录 一.Locust 性能测试 (一). 性能测试工具 主流性能测试工具对比 认识Locust (二) locust 基本用法 1.安装locust 2.编写用例 3. 启动测试 GUI 模式启动 ...
- 理论+案例,带你掌握Angular依赖注入模式的应用
摘要:介绍了Angular中依赖注入是如何查找依赖,如何配置提供商,如何用限定和过滤作用的装饰器拿到想要的实例,进一步通过N个案例分析如何结合依赖注入的知识点来解决开发编程中会遇到的问题. 本文分享自 ...
- 编程技巧│提高 Javascript 代码效率的技巧
目录 一.变量声明 二.三元运算符 三.解构赋值 四.解构交换 五.箭头函数 六.字符串模版 七.多值匹配 八.ES6对象简写 九.字符串转数字 十.次方相乘 十一.数组合并 十二.查找数组最大值最小 ...
- Leetcode----<Diving Board LCCI>
题解如下: public class DivingBoardLCCI { /** * 暴力解法,遍历每一种可能性 时间复杂度:O(2*N) * @param shorter * @param long ...
- Nacos开机自启
1.添加nacos.service文件 vi /lib/systemd/system/nacos.service 2.将以下内容写到nacos.service文件中 ps:我的nacos路径是/usr ...
- 013(oulipo)
题目:http://ybt.ssoier.cn:8088/problem_show.php?pid=1455 题目描述:在母串里找子串出现的次数 题目思路:与字符串的搜索有关那就立刻找到哈希 从s[1 ...
- 静态代码块和数组工具类Arrays
静态代码块 静态代码块:定义在成员位置,使用static修饰的代码块{ }. ~位置:类中方法外. ~执行:随着类的加载而执行且执行一次,优先于main方法和构造方法的执行 格式: public cl ...