《Vision Permutator: A Permutable MLP-Like ArchItecture For Visual Recognition》论文笔记
论文题目:《Vision Permutator: A Permutable MLP-Like ArchItecture For Visual Recognition》
论文作者:Qibin Hou, Zihang Jiang, Li Yuan et al.
论文发表年份:2022.2
模型简称:ViP
发表期刊: IEEE Transactions on Pattern Analysis and Machine Intelligence
Abstract
在本文中,我们提出了一种概念简单、数据高效的类似MLP的视觉识别体系结构——视觉置换器(Vision Permutator)。不同于最近的类似MLP的模型大都沿着平坦的空间维度编码空间信息。由于认识到二维特征表示所携带的位置信息的重要性,Vision Permutator通过线性投影分别对沿高度和宽度维度的特征表示进行编码。这使得Vision Permutator可以沿着一个空间方向捕获远程依赖关系,同时保持沿着另一个方向的精确位置信息。由此产生的位置敏感输出,然后以相互补充的方式聚合,形成感兴趣的对象的表达。Vision Permutator由纯1 × 1卷积组成,但可以对全局信息进行编码。Vision Permutator也消除了对自注意力的依赖,因此效率更高。开源代码: https://github.com/Andrew-Qibin/VisionPermutator
Method
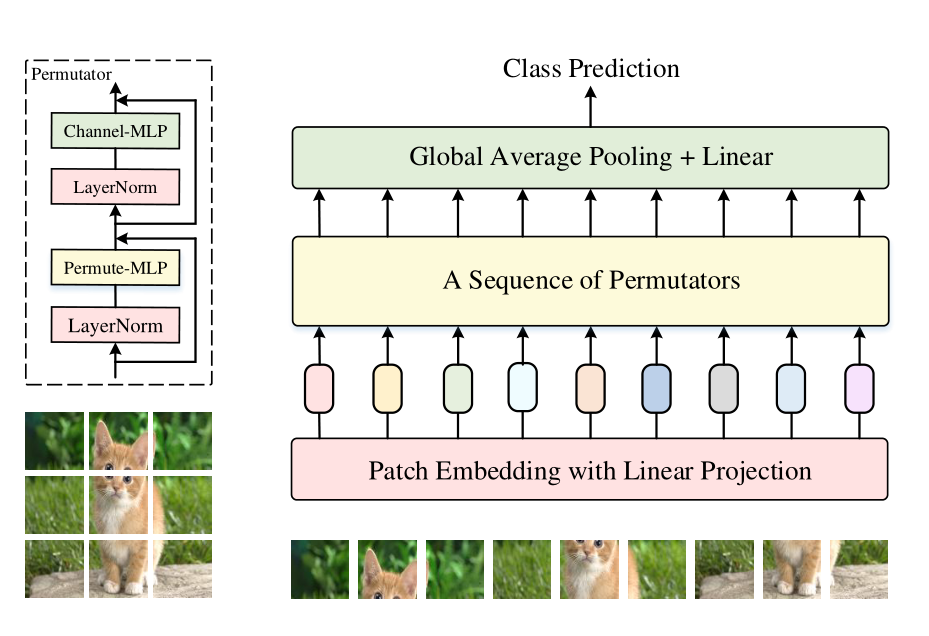
Vision Permutator从与Vision Transformers类似的tokenization操作开始,它将输入图像统一地分割为小块,然后将它们映射到带有线性投影的token embedding。然后将形状为“height×width×channels”的结果token embeddings到Permutator block序列中,每个Permutator block由一个用于空间信息编码的Permute-MLP和一个用于通道信息混合的Channel - MLP组成。Permute-MLP层如下图所示,
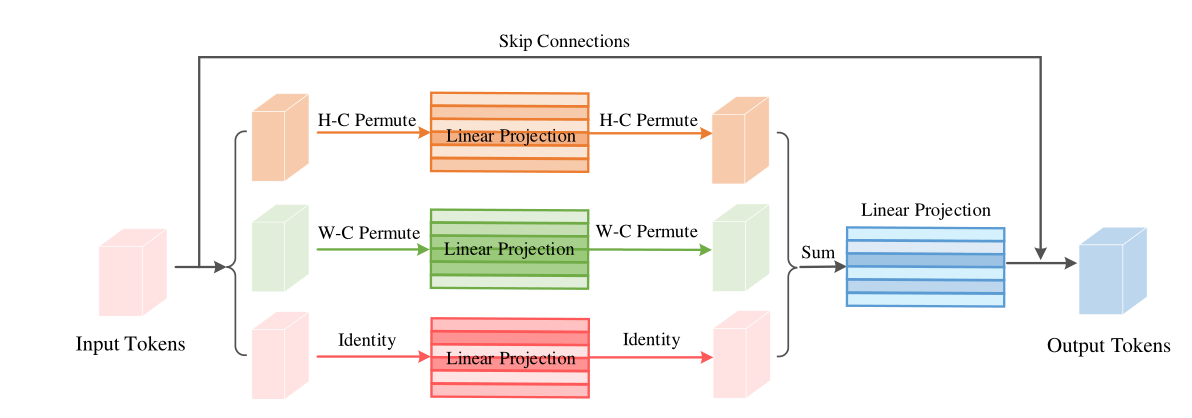
Permute-MLP层由三个独立的分支组成,每个分支沿特定的维度编码特征,即高度、宽度或通道维度。Channel-MLP模块的结构与Transformer中的前馈层相似,包括两个完全连接的层,中间有一个GELU激活。公式如下:

对于Channel信息编码,只需要一个权重WC∈RC×C的全连接层,就可以对输入X进行线性投影,得到XC。对于高度信息编码,首先对传入的分割好的每个tokens作维度变换(ex:Transpose the first (Height) dimension and the third (Channel) dimension: (H, W, C) → (C, W, H).)然后沿着通道维度连接它们作为Premute的输出,传入Linear Projection:连接权重为WH∈RC×C的全连接层,混合高度信息。再通过维度变换复原输入维度。对宽度信息编码作类似处理,最后讲三个分支的输出加和作为最后全连接层的输入。Linear Projection的输出公式表示如下:(最后输出再与input tokens作跳跃连接得到最终Permute-MLP的输出。)
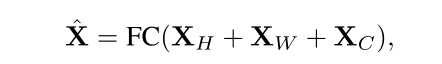
Weighted Permute-MLP:上述方法只是简单地将所有三个分支的输出通过元素相加来融合。在这里,我们通过重新校准不同分支的重要性,进一步改进了上述Permute-MLP,并提出加权Permute-MLP。这可以通过利用分散注意力(split attention)实现。不同的是,分散注意力应用于XH、XW和XC,而不是由分组卷积生成的一组张量。在下文中,我们默认使用Permutator中的加权Permute-MLP。
Experiment
与ImageNet上最近的类MLP模型比较Top-1精度,所有模型都是在没有外部数据的情况下进行训练的。在相同的计算量和参数约束下,我们的模型始终优于其他方法。
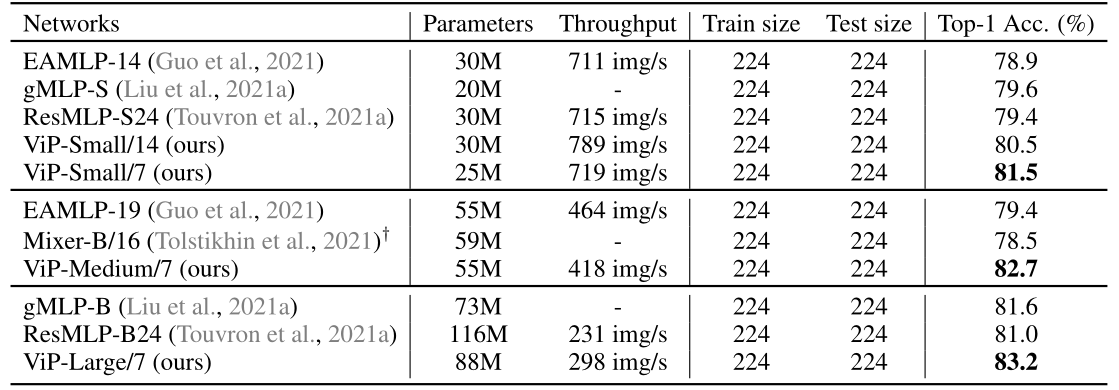
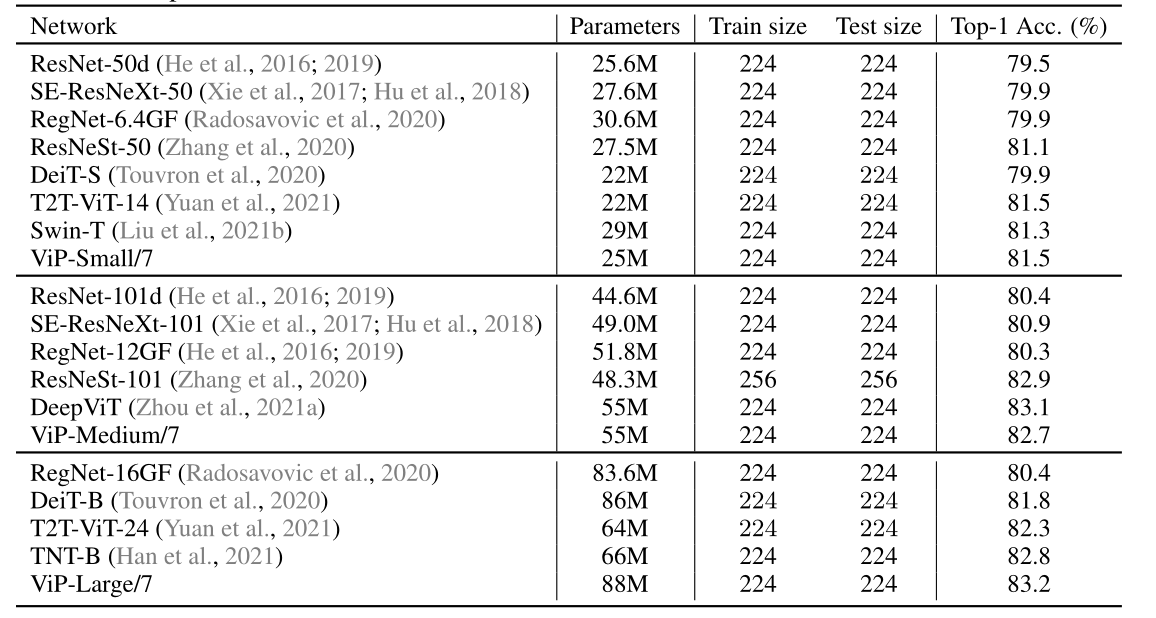
与ImageNet上的经典CNN和Vision Transformer的精度比较。所有模型都是在没有外部数据的情况下进行训练的。在相同的计算和参数约束下,我们的模型可以与一些强大的基于CNN和基于Transformer的模型竞争。
.
《Vision Permutator: A Permutable MLP-Like ArchItecture For Visual Recognition》论文笔记的更多相关文章
- [place recognition]NetVLAD: CNN architecture for weakly supervised place recognition 论文翻译及解析(转)
https://blog.csdn.net/qq_32417287/article/details/80102466 abstract introduction method overview Dee ...
- 论文笔记系列-Auto-DeepLab:Hierarchical Neural Architecture Search for Semantic Image Segmentation
Pytorch实现代码:https://github.com/MenghaoGuo/AutoDeeplab 创新点 cell-level and network-level search 以往的NAS ...
- 论文笔记——Rethinking the Inception Architecture for Computer Vision
1. 论文思想 factorized convolutions and aggressive regularization. 本文给出了一些网络设计的技巧. 2. 结果 用5G的计算量和25M的参数. ...
- 论文笔记:Fast Neural Architecture Search of Compact Semantic Segmentation Models via Auxiliary Cells
Fast Neural Architecture Search of Compact Semantic Segmentation Models via Auxiliary Cells 2019-04- ...
- 论文笔记:ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware
ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware 2019-03-19 16:13:18 Pape ...
- 论文笔记:DARTS: Differentiable Architecture Search
DARTS: Differentiable Architecture Search 2019-03-19 10:04:26accepted by ICLR 2019 Paper:https://arx ...
- 论文笔记:Progressive Neural Architecture Search
Progressive Neural Architecture Search 2019-03-18 20:28:13 Paper:http://openaccess.thecvf.com/conten ...
- 论文笔记:Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation
Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation2019-03-18 14:4 ...
- 论文笔记系列-DARTS: Differentiable Architecture Search
Summary 我的理解就是原本节点和节点之间操作是离散的,因为就是从若干个操作中选择某一个,而作者试图使用softmax和relaxation(松弛化)将操作连续化,所以模型结构搜索的任务就转变成了 ...
随机推荐
- UVA195 Anagram 题解
To 题目 主要思路:全排列 + 亿点点小技巧. 不会全排列的可以先把这道题过了 \(P1706\). 这道题的难点就在于有重复的单词,只记一次. 第一个想法是将所有以生成的单词记录下来,然后每次判断 ...
- C++中关于cout相关的输出格式(操作流算子)
这边需要注意的是如果使用到setpercision,一定要引入iomanip头文件,否则编译会出错 注意以下的操作流算子都是在头文件iomanip中定义的,强烈建议使用的时候引入改头文件否则可能会出现 ...
- 第十二天python3 匿名函数
python借助lambda表达式构建匿名函数: 参数列表不需要小括号: 冒号是用来分割参数列表和表达式的: 不需要使用return,表达式的值,就是匿名函数返回值: lambda表达式(匿名函数)只 ...
- python 日志类
简介 在所有项目中必不可少的一定是日志记录系统,python为我们提供了一个比较方便的日志模块logging,通常,我们都会基于此模块编写一个日志记录类,方便将项目中的日志记录到文件中. loggin ...
- 修改 hosts
不会牛逼操作 -1. 位置.格式 所有系统都差不多,都是 啥啥/etc/hosts 这样的 . 具体去查即可 . 格式: ip + 域名 域名不能含有通配符 hosts 可以绕过 dns 解析,直接访 ...
- P4983忘情
今天挺开心的\(\sim\),省选加油\(!\) \(P4893\)忘情 我能说今晚我才真正学会\(wqs\)和斜率优化吗\(?\) 恰好选几个,必然需要\(wqs\)二分一下 那么考虑不考虑次数情况 ...
- Vector3类定义
大家一定要先看书,在看我的随笔啊.不然不知道原理的.而且我是不写教程的,只是写笔记怕自己忘记了. 我把所有的基础类放在了名叫geometry的文件中,包含Vector3, Normal3, Point ...
- LuoguP3690 【模板】Link Cut Tree (LCT)
勉强算是结了个大坑吧或者才开始 #include <cstdio> #include <iostream> #include <cstring> #include ...
- BZOJ1305/Luogu3153 [CQOI2009]dance跳舞 (network flow)
#define T 1001 #define S 0 struct Edge{ int nxt,pre,w; }e[500007]; int cntEdge,head[N]; inline void ...
- 红黑树以及JAVA实现(一)
目录 前言 一. B树 1.1 概念 1.2 2-3-4树 1.3 2-3-4树的插入 节点分类 1.4 2-3-4树的删除 1.4.1 当删除节点是叶子节点 1.4.1.1 当删除节点为非2节点 1 ...