O-MVLL代码混淆方式
在介绍O-MVLL之前,首先介绍什么是代码混淆以及基于LLVM的代码混淆,O-MVLL项目正是基于此而开发来的。
有关O-MVLL的概括介绍以及安装和基本使用方式,可参见另一篇随笔
https://www.cnblogs.com/level5uiharu/p/16912019.html
基于LLVM的代码混淆
代码混淆是将代码转换成另一种功能上等价,但更难以阅读的形式,是一种对抗逆向工程的手段,也是一种保护源代码和程序的手段。
例如修改各种函数、变量名称以消除其语义,使用非正常逻辑实现功能、使指令复杂化等等。代码混淆不能从根源上对抗逆向工程,只能增加逆向工程的分析成本,因此还需要结合其他手段来获得更强的安全性。同时,常见的代码混淆方式往往会引入大量无关指令,或者用于复杂化程序的指令,尽管引入指令越多安全性越强,但通常还会增加程序体积并降低运行效率。因此在使用代码混淆时,要平衡好效率和安全性。

目前代码混淆仍是一个小众方向,相关研究和进展不多。此外,代码混淆还可以应用于恶意代码检测领域,对恶意程序进行混淆从而生成更多的恶意代码样本,一方面扩充了模型训练的数据集,另一方面代码混淆对恶意代码进行的修改可能会隐藏其某些特征。
那么什么是基于LLVM的代码混淆呢?
代码混淆有多种实现途径,根据目标编程语言、架构等不同有不同方式。最初的代码混淆是直接在源代码上进行修改然后编译,这样虽然保护了源代码,但也增加了调试和开发者自己理解源码的成本。Java则由于其字节码的存在,通常是对存储在class文件中的字节码进行混淆,这样就不必修改源码,但仍能得到一份混淆后的可执行文件,将可执行文件发行即可。
基于LLVM的代码混淆正是采用了和Java混淆类似的思路,LLVM编译框架大致分为前端、中端、后端三段:
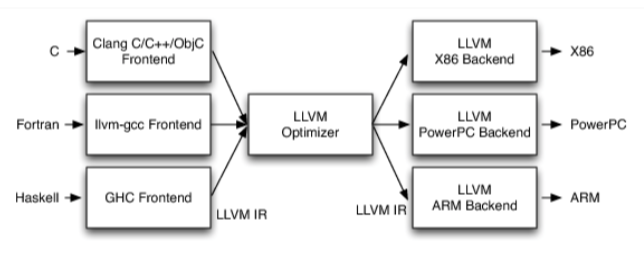
前端:进行词法分析、语法分析、语义分析等,生成中间代码IR
中端:优化器,会在此处对中间代码IR进行修改优化,中端会有名为Pass的文件,每一个Pass都会依照自身的逻辑对IR进行修改完成优化
后端:完成连接、汇编、生成目标文件的工作
如上图所示,对于不同的编程语言,都会在前端转换成格式相同的IR文件后交由中端优化器处理。同时,LLVM提供了Pass开发的API,可以根据自身需求开发特定功能的Pass。
因此基于LLVM的代码混淆实际上是通过开发Pass的方式,在中端优化器中混淆IR文件,再讲混淆后的IR文件连接汇编,从而得到混淆的可执行文件的。
O-MVLL代码混淆器
O-MVLL项目灵感源自OLLVM,后者则是最著名的基于LLVM的代码混淆器之一,实现了指令替代、控制流平坦化、虚假控制流这三种代码混淆方式。O-MVLL在OLLVM的基础上增强了这三种代码混淆方式,同时新增了一些代码混淆方式(当然,以Python API的形式调用代码混淆也是其创新和特点,在上一篇文章中有所介绍)
下面介绍O-MVLL中使用的代码混淆方式
对抗挂钩Anti_Hooking
使用方式:重写anti_hooking方法
def anti_hooking(self, mod: omvll.Module, func: omvll.Function) -> omvll.AntiHookOpt:
if func.name in ["encrypt", "has_secure_enclave"]:
return True
return False
以上的代码能够将这种代码混淆方式作用于函数名为encrypt、has_secure_enclave的函数。
对抗hook技术是另一门值得深入研究的学问,因此O-MVLL对此进行的保护适用范围有限,安全性也有限。
该方式只适用于对抗frida,这跟它的设计有关。通常来说,hook框架需要使用几个临时的寄存器来重新定位或访问当前函数的原数据,对于frida来说,它需要使用x16,x17两个寄存器之一。这一点可以在frida项目的文件gumarm64relocator.c中分析出来:
if (available_scratch_reg != NULL)
{
gboolean x16_used, x17_used;
guint insn_index; x16_used = FALSE;
x17_used = FALSE;
...
if (!x16_used)
*available_scratch_reg = ARM64_REG_X16;
else if (!x17_used)
*available_scratch_reg = ARM64_REG_X17;
else
*available_scratch_reg = ARM64_REG_INVALID;
}
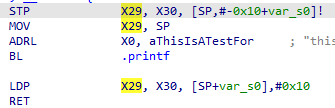
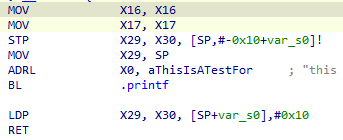
因此如果在函数的序言开始的地方插入指令,占用x16,x17这两个寄存器,就能够让frida抛出错误。O-MVLL也正是这样做的,具体做法为在函数的开头插入
mov x17,x17;mov x16,x16或者mov x16,x16;mov x17,x17两条语句,插入哪组指令则是由随机数随机选择
可以参见O-MVLL/src/passes/anti-hook/AntiHook.cpp中的定义
static const std::vector<PrologueInfoTy> ANTI_FRIDA_PROLOGUES = {
{R"delim(
mov x17, x17;
mov x16, x16;
)delim", 2},
{R"delim(
mov x16, x16;
mov x17, x17;
)delim", 2}
};
运算混淆Arithmetic Obfuscation
使用方法:重写obfuscate_arithmetic方法
def obfuscate_arithmetic(self, mod: omvll.Module,
fun: omvll.Function) -> omvll.ArithmeticOpt:
if func.name == "encode": return omvll.ArithmeticOpt(8)
上述配置会将该代码混淆方式应用于encode函数,并且迭代混淆8次
这种方式是将运算指令复杂化,能够被复杂化的运算指令包括加、减、与、或、异或,乘法和除法由于其运算的复杂性和溢出、借位等操作难以实现。
具体来说,它会将这些运算使用混合布尔算术(MBA)构造的等价式替代,这些等价式和原本的运算指令之间的映射关系如下
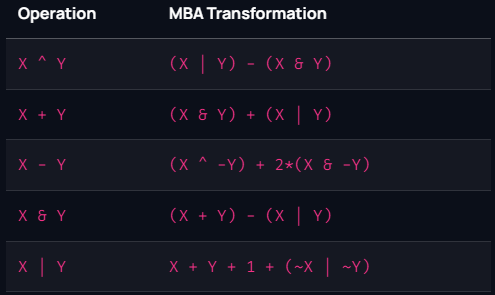
迭代混淆会在上一轮混淆的基础上再次调用该混淆方式,多次的迭代将产生大量的混淆代码,因此一定要考虑安全性和运行效率的平衡。
以下是混淆前后的对比,迭代次数为1
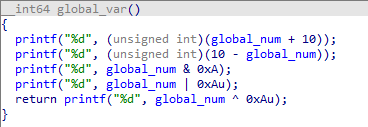

使用这种方式混淆出来的特征明显,且由于每种运算指令和替代式一一对应,因此每一种特定的混淆形式都能唯一确定相应的运算指令,也能由混淆形式还原。这种混淆方式往往需要和其他代码混淆方式结合使用才能发挥更大的威力。
不透明常量Opaque Constants
使用方式:重写obfuscate_constants方法
def obfuscate_constants(self, mod: omvll.Module, func: omvll.Function):
# Logic goes here
在函数的返回值方面,作者进行了设计,目前提供以下几个返回值的处理:
1.BOOL:返回true时启动混淆,false时不启动
2.返回一个整型常量的list:混淆list中出现的常量
3.返回omvll.OpaqueConstantsLowerLimit(n),混淆不小于n的常量
与运算混淆类似,这里则是使用构造的复杂等价式替换掉程序中出现的常量,这对于一些加密算法的特征常量(例如AES的S盒)的保护效果很好。
对于用来替代常量的复杂等价式的构造,作者采用以下三个方式:
1.0的构造
0 = MBA(X ^ Y) - (X ^ Y)
0 = (X | Y) - (X & Y) - (X ^ Y)
2.1的构造
LSB = 当前栈顶地址
Odd = 随机生成的奇数
1 = (LSB + Odd) % 2
由于栈地址一定要满足对齐的条件因此低位一定是0,即栈地址是一个偶数,这样就能保证LSB + Odd一定等于一个奇数
3.其他值的构造
Split = random(1,min(255,var))
LHS = var - Split + 0
RHS = Split + 0
var = LHS + RHS
通过上述构造的替换,逆向工程时能看到的原常量var被替换成LHS + RHS。此外LHS和RHS都分别加上了0,这个0会被之前提到的0的构造替换。并且整个Opaque Constants会默认启用运算混淆,迭代次数为1,其中相应的运算指令也会被复杂化。
下图为混淆前后的对比图,展示的是0的构造替代。
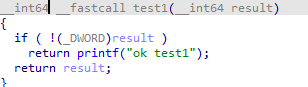

可以看到尽管没有在配置中启用运算混淆,但是常量混淆的混淆代码中有明显运算混淆的特点。
控制流破坏Control-Flow Breaking
使用方式:重写break_control_flow方法
def break_control_flow(self, mod: omvll.Module, func: omvll.Function):
if func.name == "break_control_flow":
return True
return False
上述配置会将该混淆方式应用于break_control_flow函数
该混淆方式破坏控制流,准确地说是破坏函数调用的控制流。但本质上并没有改变函数调用的流程图,而是将被保护的函数中的指令复制到另一个函数当中,再删除原函数的指令并添加混淆指令,最后使用隐含的方式跳转到复制函数中以保证功能不变。
具体而言,它做了三件事:
1.clone克隆
克隆原函数的所有指令,并记录克隆函数的地址。
2.插入混淆指令
删除原函数的指令,并插入混淆指令,这些混淆指令包含类似于ldr x0,#offset的指令,pc+#offset处则是要保护的函数的地址,添加这种指令会让反汇编器认为这个偏移处的内容可能不是指令而是数据,然而实际上它就是指令。
此外还会添加一些运算,运算结果为克隆函数地址,将地址保存到局部变量中,并使用运算混淆和不透明常量进行联合保护。
3.添加跳转
在原函数的结尾处插入跳转指令,跳转到保存了原函数正常功能的克隆函数处,以完成正常功能。
首先会从局部变量中取出克隆函数的地址到寄存器中,再使用BLR指令跳转到寄存器中保存的地址。

以这样的方式跳转,克隆函数不会出现在函数调用的流程图当中,相比于硬编码使用函数地址完成跳转来说是一种隐含的函数调用
下图是该混淆方式工作的模式图
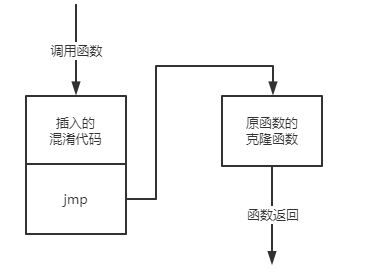
以下是混淆前后函数的对比


混淆后函数原先的代码被存放在了克隆函数sub_18D8当中,并通过最后一条指令跳转到克隆函数,克隆函数当中的内容,与未混淆前原函数的内容相同

控制流平坦化Control-Flow Flattening
使用方式:重写flatten_cfg函数
def flatten_cfg(self, mod: omvll.Module, func: omvll.Function):
if func.name == "check_password":
return True
return False
如上所示,将会对函数check_password使用该混淆方式。
控制流平坦化是对程序中出现的分支和跳转进行修改,全部转换为switch的形式,从控制流程图的角度看,就像是把控制流程图给压平了,如下图所示
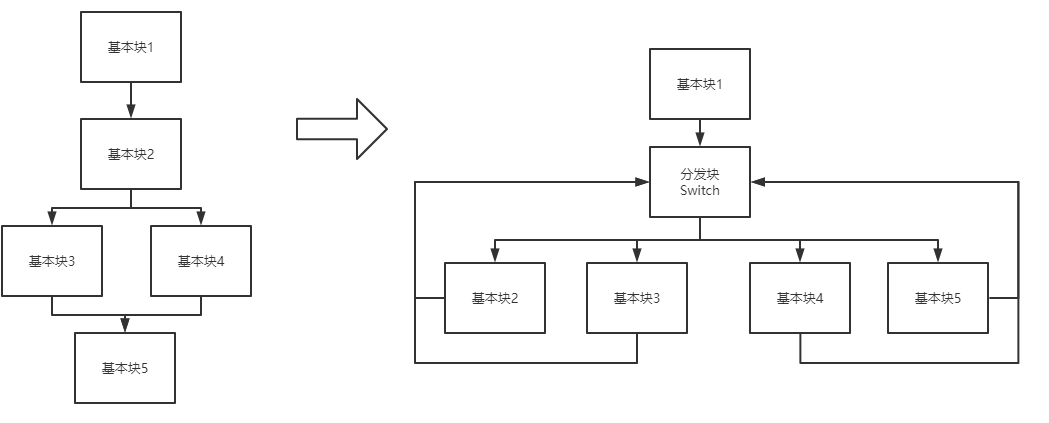
那么如何保证执行的顺序和分支条件不发生变化呢?
假设switch语句根据变量var来进行跳转,那么首先为每个基本块打上标签,从基本块2到基本块5分别为a,b,c,d,e,这五个标签为生成的随机数。
之后在每一个基本块结束的时候对var进行赋值,将var赋值为下一个基本块对应的标签,然后再跳转到分发块,例如基本块2的分支可能跳转到基本块3和基本块4,那么根据判断条件,将var赋值为b或者c,然后跳转到分支块switch,switch语句就会根据基本块2对var的修改来进行相应的跳转。
以上是OLLVM实现的控制流平坦化,O-MVLL对其进行了增强
1.对var进行编码处理
在OLLVM中,可以根据基本块最后的赋值来判断下一个基本块是哪个,你可能能够看到如下的伪代码:
switch(var){
case a: var = b;
case b: ;
...
}
可以很明显地根据对var的赋值判断出基本块a的下一个基本块是基本块b。
但在O-MVLL中,赋值给var的值实际上是经过编码后的值,也就是如下的伪代码:
switch(encode(var)){
case a: var = c;
case b: ;
...
}
而encode(c)= b,这保证了流程的正常执行,但仅仅通过分析switch处的代码,无法得知基本块a的下一个基本块是基本块b,还需要对编码的算法进行分析和破解。
2.在default中填充垃圾代码
由控制流平坦化而来的switch语句中,default所指示的代码块是永远不会被执行的(否则原程序的控制流程被混淆后就发生改变了),因此O-MVLL在default指示的代码块中插入了一些垃圾代码,这些代码不会被执行,但仍会出现在控制流程图中混淆视线。
这里添加的垃圾代码,就像Control-Flow Breaking中添加的混淆指令一样。
以下是混淆前后函数的控制流程图:
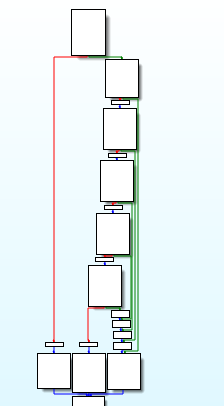
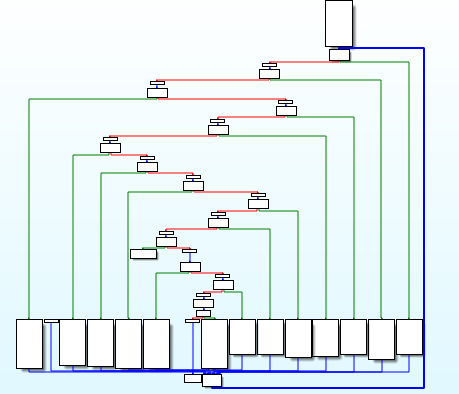
不透明字段访问Opaque Fields Access
使用方法:重写obfuscate_struct_access函数
def obfuscate_struct_access(self, _: omvll.Module, __: omvll.Function,
struct: omvll.Struct):if struct.name == "class.SecretString":
return True
return False
如上所示,将会对名字为SecretString的类进行混淆(该混淆方式也可以应用于结构体)
这种方式能够增加分析结构体和类的难度,在逆向工程时更难分析出类和结构体内部的成员和类型。
通常,对于结构体和类的访问采用
ldr x0, [x1, #offset]
这样的形式,而offset的组成是由局部变量和栈顶的偏移组成的,因此无法直接对#offset进行混淆。
O-MVLL的做法是将上述指令转换如下:
$var := #offset + 0
ldr x0, [x1, $var]
这样就将偏移保存在变量当中,再通过变量进行寻址。此时就可以对var进行混淆了,混淆的方式采用了之前提到的运算混淆和不透明常量两种方式结合。
以下是混淆前后的对比图
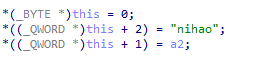
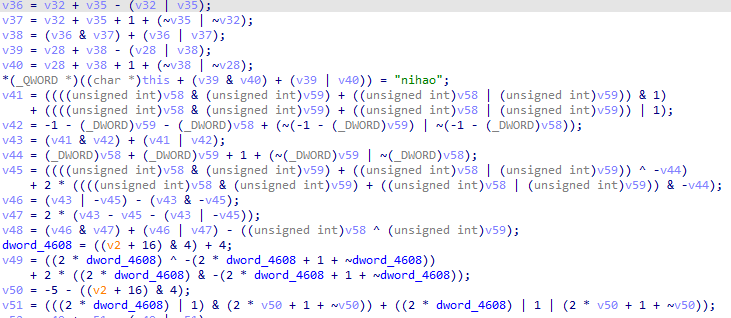
字符串加密Strings Encoding
使用方式:重写obfuscate_string方法
def obfuscate_string(self, _, __, string: bytes):
if b'debug.cpp' in string:
return 'REMOVED'
该方法支持多种返回值,具体如下:
1.返回一个字符串:将字符串替换为返回的字符串,如果用于替换的字符串长度比原字符串长,则超出部分会被截断。返回空字符串时表示删除
2.返回omvll.StringEncOptGlobal(),加密字符串并存储为全局变量,在.data段可见,一旦程序被加载,该字符串就可以被搜索到
3.返回omvll.StringEncOptStack(),加密字符串并存储在当前栈上
4.返回omvll.StringEncOptStack(loopThreshold=0),加密字符串并存储在当前栈上,解密流程相比3更简单,代码量减少
上述四种方式的实现细节如下:
omvll.StringEncOptGlobal()
这种方式加密后,字符串被保存在.data段上

对应的解密函数为sub_1818,该解密函数被存放在.init_array当中,也就是说它是在程序加载后的初始化当中被调用,因此一旦程序完成加载初始化,字符串就会被还原

omvll.StringEncOptStack()
这种方式会将加密后的字符串作为局部变量保存在函数的栈上,使用该字符串之前的解密步骤也是在使用该字符串的函数中完成

在解密算法调用的时候,也都默认调用了运算混淆和不透明常量两种混淆方式。
没有启用loopThreshould=0时,解密的算法大致如下所示
char OMVLL_DECODED[6];
OMVLL_DECODED[1] = ENC_OMVLL[1] ^ 0xd7;
OMVLL_DECODED[5] = ENC_OMVLL[5] ^ 0x02;
OMVLL_DECODED[2] = ENC_OMVLL[2] ^ 0x77;
OMVLL_DECODED[0] = ENC_OMVLL[0] ^ 0x55;
OMVLL_DECODED[4] = ENC_OMVLL[4] ^ 0x7b;
OMVLL_DECODED[3] = ENC_OMVLL[3] ^ 0x35;
这种方式产生大量指令,但好在打乱了秘钥流,增强了安全性。当字符串很长时,这种方式会非常耗费空间。
因此启用了loopThreshould=0时,解密算法大致可以如下表示:
char OMVLL_DECODED[6];
for (size_t i = 0; i < 6; ++i) {
OMVLL_DECODED[i] = ENC_OMVLL[i] ^ KEY[i];
}
O-MVLL代码混淆方式的更多相关文章
- Android 编程下的代码混淆
什么是代码混淆 Java 是一种跨平台的.解释型语言,Java 源代码编译成中间”字节码”存储于 class 文件中.由于跨平台的需要,Java 字节码中包括了很多源代码信息,如变量名.方法名,并且通 ...
- Android 代码混淆
什么是代码混淆 Java 是一种跨平台的.解释型语言,Java 源代码编译成中间”字节码”存储于 class 文件中.由于跨平台的需要,Java 字节码中包括了很多源代码信息,如变量名.方法名,并且通 ...
- 【转】Android 编程下的代码混淆
什么是代码混淆 代码混淆(Obfuscated code)亦称花指令,是将计算机程序的代码,转换成一种功能上等价,但是难于阅读和理解的形式的行为.代码混淆可以用于程序源代码,也可以用于程序编译而成的中 ...
- ProGuard代码混淆技术详解
前言 受<APP研发录>启发,里面讲到一名Android程序员,在工作一段时间后,会感觉到迷茫,想进阶的话接下去是看Android系统源码呢,还是每天继续做应用,毕竟每天都是画UI ...
- 最新的JavaScript核心语言标准——ES6,彻底改变你编写JS代码的方式!【转载+整理】
原文地址 本文内容 ECMAScript 发生了什么变化? 新标准 版本号6 兑现承诺 迭代器和for-of循环 生成器 Generators 模板字符串 不定参数和默认参数 解构 Destructu ...
- ProGuard 代码混淆
简介 Java代码是非常容易反编译的.为了很好的保护Java源代码,我们往往会对编译好的class文件进行混淆处理. ProGuard是一个混淆代码的开源项目.它的主要作用就是混淆,当然它还能对字节码 ...
- android apk 导出(签名) is not translated in xx 代码混淆 反编译
apk导出遇到问题 解决方式如下 1.导出步骤第一步 2.提示错误 3.解决 其余步骤参见: 代码混淆和数字签名(现在版本混淆) http://blog.csdn.net/moruna/article ...
- android对app代码混淆
接到新任务.现有项目的代码混淆.在此之前混淆了一些理解,但还不够具体和全面,我知道有些东西混起来相当棘手. 但幸运的是,现在这个项目是不是太复杂(对于这有些混乱).提前完成--这是总结. 第一部分 介 ...
- Android项目外接高德地图代码混淆注意事项
如今好多项目中都加入了第三方jar包,可是最大的问题就是打包的时候代码混淆报错,下面是高德地图混淆报错解决方式: 在proguard-project.txt中加入例如以下代码: -libraryjar ...
- android代码混淆笔记
混淆处理的apk被反编译后代码中包名类名等都变成abcd之类.非常难看懂. 使用代码混淆.启用混淆器,对相关文件进行编辑,然后打包签名就能够了: ------------ 在2.3的版本号中,项目中有 ...
随机推荐
- prometheus和granfana企业级监控实战v5
文件地址:https://files.cnblogs.com/files/sanduzxcvbnm/prometheus和granfana企业级监控实战v5.pdf
- Elasticsearch:使用 Nginx 来保护 Elastic Stack
文章转载自:https://elasticstack.blog.csdn.net/article/details/112213364
- 内网横向渗透 之 ATT&CK系列一 之 横向渗透域主机
前言 上一篇文章中已获取了关于域的一些基本信息,在这里再整理一下,不知道信息收集的小伙伴可以看回上一篇文章哦 域:god.org 域控 windows server 2008:OWA,192.168. ...
- acwing346 走廊泼水节 (最小生成树)
完全图就是每两个点都有直接相连的边. 模拟Kruskal算法的过程,每选择一条边加入时,他两端端点在同一个集合中就跳过,否则考虑合并两个集合,合并时需要增加的每条边的权值至少是edge[i]+1,这才 ...
- this硬绑定
一.this显示绑定 this显示绑定,顾名思义,它有别于this的隐式绑定,而隐式绑定必须要求一个对象内部包含一个指向某个函数的属性(或者某个对象或者上下文包含一个函数调用位置),并通过这个属性间接 ...
- python提效小工具-统计xmind用例数量
问题:做测试的朋友们经常会用到xmind这个工具来梳理测试点或写测试用例,但是xmind8没有自带的统计测试用例,其他版本的xmind有些自带节点数量统计功能,但也也不会累计最终的数量,导致统计测试工 ...
- DevOps|高效能敏捷交付组织:特性团队(FeatureTeam)+Scrum
这是<研发效能组织能力建设>的第三篇.特性团队和Scrum,这两个定义我们在之前的文章中都详细介绍了.这两个组织模式或者说管理实践,我都用过所以有些时候特别有感触.书本上纯粹的模式很容易理 ...
- How to get the return value of the setTimeout inner function in js All In One
How to get the return value of the setTimeout inner function in js All In One 在 js 中如何获取 setTimeout ...
- Vue中、参数传递以及重定向
1.参数传递 关键部分代码 1.参数传递 <router-link :to="{name:'information',params:{id:1}}">用户信息</ ...
- 齐博x1第三季《模板风格的制作》系列009-自定义区块代码
本节来说明如何自定义区块代码,不再继承上层模板,实现个性模板 上一节因为我们继承了layout布局模版,所以我们自定义的代码就无效了 如果我们继承了上层模板,那么相当于我们复制了一份上层模板的结构,也 ...