Redis之key的淘汰策略
淘汰策略概述
redis作为缓存使用时,在添加新数据的同时自动清理旧的数据。这种行为在开发者社区众所周知,也是流行的memcached系统的默认行为。
redis中使用的LRU淘汰算法是一种近似LRU的算法。
淘汰策略
针对淘汰策略,redis有一下几种配置方案:
1、noeviction:当触发内存阈值时,redis只读不写;
2、allkeys-lru:针对所有的key,执行LRU(最近最少使用)策略;
3、allkeys-lfu:针对所有的key,执行LFU(最低频使用)策略;
4、volatile-lru:针对设置了过期时间的key,执行LRU(最近最少使用)策略;
5、volatile-lfu:针对设置了过期时间的key,执行LFU(最低频使用)策略;
6、allkeys-random:针对所有key,进行随机淘汰;
7、volatile-random:针对设置了过期时间的key,进行随机淘汰;
8、volatile-ttl:针对设置了过期时间的key,淘汰剩余过期时间最短的;
根据应用场景选择合适的淘汰策略是非常重要的,我们可以在程序运行时实时重置淘汰策略,并使用Redis INFO输出来监控缓存未命中和命中的数量,以优化设置。
根据以往使用惯例:
- 当你希望某些元素的子集被访问的频率高于其他元素,或者当你不知道怎么选择淘汰策略时,allkeys-lru策略是一个很好的选择;
- 当你在循环访问redis,且所有的key是被连续扫描时,或者你希望key过期时间均匀分布时,allkeys-random策略是一个很好的选择;
- 如果你希望基于key不同的TTL时间筛选出哪些key可被淘汰,volatile-ttl策略是一个很好的选择;
还有一点是为key设置过期时间会占用内存,因此使用allkeys-lru这样的策略会更节省内存,因为在内存压力下不需要对key进行过期设置。
淘汰策略如何工作
淘汰过程如下:
- 客户端执行一条指令,需要添加一批数据;
- redis检测缓存阈值限制,如果超过阈值则执行淘汰策略;
- 执行指令等等;
因此在redis的使用过程中,我们可能不断的超过内存阈值限制,然后执行淘汰策略再将内存恢复到阈值之下。
近似LRU算法
maxmemory-samples 5
redis不使用真正的LRU实现的原因是它需要更多的内存。然而,对于使用Redis的应用程序,近似lru算法实际上是与精确lru算法差不多的。此图将redis使用的LRU近似值与真实LRU进行了比较。

用给定数量的key填充了Redis服务器(达到内存阈值)进行测试并生成了上面的图。从第一个到最后一个访问key。第一个key是使用LRU算法淘汰的最佳候选key。之后再添加50%以上的key,以强制淘汰一半的旧key。
你可以在图中看到三种点,形成了三个不同的区域:
- 浅灰色区域是被淘汰的对象
- 灰色区域是未被淘汰的对象
- 绿色区域是新加的对象
在理论LRU实现中(theoretical LRU),我们预计旧key集合中的前一半将会被淘汰,与之相反,redis lru算法实现中,旧key集合中也只是会离散性的淘汰其中某些key。
正如您所看到的那样,与Redis 2.8相比,Redis 3.0在同样抽样数为5个时做得更好,但是大多数最新增加的key仍然被Redis 2.8保留。在Redis 3.0中使用10的样本大小,近似值非常接近Redis 3.0的理论性能。
在模拟中,我们发现使用幂律访问模式(类似20%的key承担了80%的访问),真实LRU和Redis近似LRU之间的差异极小或根本不存在。
使用CONFIG SET maxmemory samples<count>命令在生产中使用不同的样本大小值进行实验非常简单。
新的LFU模式
从redis4.0开始,可以在某些特定场景下使用低频淘汰策略。在选用LFU策略后,redis会跟踪key的访问频率,所以低频的key将被淘汰。这意味着经常访问的key有很大的机会一直留在内存中。
要配置LFU模式,可以使用以下策略:
- volatile-lfu:针对设置了过期时间的key,使用近似lfu淘汰;
- allkeys-lfu:针对所有key,使用近似lfu淘汰;
LFU近似于LRU:它使用一个称为Morris的概率计数器来估计key访问频率,计数器中每个key只占用几个bit,并且计数器功能附加衰减周期,这样计数器统计的key访问频率就会随着时间的推移而降低(如果一段时间内一个key访问频率低于计数器衰减速度,最终这个key会被淘汰)。直至某一刻,我们不再将一些key视为频繁访问的key,即使它们在过去是被频繁访问的,以便算法能够适应访问模式的变化。
该信息的采样方式与LRU(如本文档前一节所述)选择淘汰key的情况类似。
然而,与LRU不同的是,LFU具有某些可调参数:例如,如果一个频繁key不再被访问,那么它的访问频率级别应该降低多少?还可以调整Morris计数器范围,以更好地使算法适应特定的场景。
默认情况下,Redis配置为:
- 在大约100万次请求时让计数器饱和;
- 每一分钟使计数器衰减一次;
这些配置应该是合理的,并且经过了实验测试,但用户可能希望使用这些配置设置来选择最佳值。
有关如何调整这些参数的说明,可以在源发行版的示例redis.conf文件中找到。简而言之,它们是:
lfu-log-factor 10
lfu-decay-time 1
衰减时间是最明显的一个,它是计数器在采样时应该衰减的分钟数。特殊值0表示:永远不会衰减计数器。
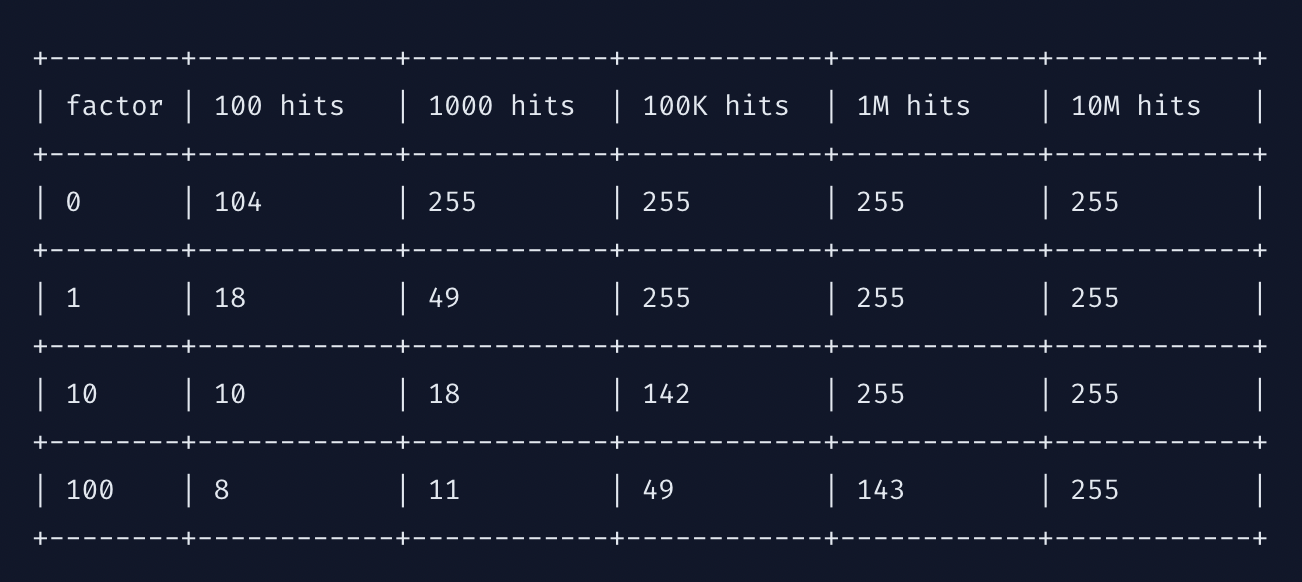
计数器对数因子决定了使频率计数器达到饱和需要的key命中次数,频率计数器刚好在0-255范围内。系数越高,需要更多的访问才能达到最大值;系数越低,低频访问计数器的分辨率越好,如下表所示:
Redis之key的淘汰策略的更多相关文章
- 动手实现 LRU 算法,以及 Caffeine 和 Redis 中的缓存淘汰策略
我是风筝,公众号「古时的风筝」. 文章会收录在 JavaNewBee 中,更有 Java 后端知识图谱,从小白到大牛要走的路都在里面. 那天我在 LeetCode 上刷到一道 LRU 缓存机制的问题, ...
- Redis数据过期和淘汰策略详解(转)
原文地址:https://yq.aliyun.com/articles/257459# 背景 Redis作为一个高性能的内存NoSQL数据库,其容量受到最大内存限制的限制. 用户在使用Redis时,除 ...
- Redis(二十):Redis数据过期和淘汰策略详解(转)
原文地址:https://yq.aliyun.com/articles/257459# 背景 Redis作为一个高性能的内存NoSQL数据库,其容量受到最大内存限制的限制. 用户在使用Redis时,除 ...
- Redis中的LRU淘汰策略分析
Redis作为缓存使用时,一些场景下要考虑内存的空间消耗问题.Redis会删除过期键以释放空间,过期键的删除策略有两种: 惰性删除:每次从键空间中获取键时,都检查取得的键是否过期,如果过期的话,就删除 ...
- Redis系列之-—内存淘汰策略(笔记)
一.Redis ---获取设置的Redis能使用的最大内存大小 []> config get maxmemory ) "maxmemory" ) " --获取当前内 ...
- Redis++:Redis 内存爆满 之 淘汰策略
前言: 我们的redis使用的是内存空间来存储数据的,但是内存空间毕竟有限,随着我们存储数据的不断增长,当超过了我们的内存大小时,即在redis中设置的缓存大小(maxmeory 4GB),redis ...
- redis过期key的清理策略
一,有三种不同的删除策略(1),立即清理.在设置键的过期时间时,创建一个回调事件,当过期时间达到时,由时间处理器自动执行键的删除操作. (2),惰性清理.键过期了就过期了,不管.当读/写一个已经过期的 ...
- Redis的key过期处理策略
Redis中有三种处理策略:定时删除.惰性删除和定期删除. 定时删除:在设置键的过期时间的时候创建一个定时器,当过期时间到的时候立马执行删除操作.不过这种处理方式是即时的,不管这个时间内有多少过期键, ...
- redis键的过期和内存淘汰策略
键的过期时间 设置过期时间 Redis可以为存储在数据库中的值设置过期时间,作为一个缓存数据库,这个特性是很有帮助的.我们项目中的token或其他登录信息,尤其是短信验证码都是有时间限制的. 按照传统 ...
- redis六种内存淘汰策略学习
当客户端会发起需要更多内存的申请,Redis检查内存使用情况,如果实际使用内存已经超出maxmemory,Redis就会根据用户配置的淘汰策略选出无用的key; 当前Redis3.0版本支持的淘汰策略 ...
随机推荐
- 十五、资源控制之Deployment
资源控制器之Deployment Deployment 为 Pod 和 ReplicaSet 提供了一个声明式定义(declarative)方法,用来替代以前的ReplicationControlle ...
- 【题解】CF1659E AND-MEX Walk
题目传送门 位运算 设题目中序列 \(w_1,w_1 \& w_2,w_1 \& w_2 \& w_3,\dots,w_1 \& w_2 \& \dots \& ...
- [CS61A] Lecture 1&2&3. Introduction&Functions&Control
[CS61A] Lecture 1&2&3. Introduction&Functions&Control 前言 CS61A是加州大学伯克利分校一门计算机专业课程,用于 ...
- 5.django-模型ORM
Django中内嵌了ORM框架,不需要直接编写SQL语句进行数据库的操作,通过定义模型类来完成对数据库中表的操作 O:Object,也就是类对象的意思 R:Relation,关系数据库中表的意思 M: ...
- [排序算法] 堆排序 (C++)
堆排序解释 什么是堆 堆 heap 是一种近似完全二叉树的数据结构,其满足一下两个性质 1. 堆中某个结点的值总是不大于(或不小于)其父结点的值: 2. 堆总是一棵完全二叉树 将根结点最大的堆叫做大根 ...
- C温故补缺(十五):栈帧
栈帧 概念 栈帧:也叫过程活动记录,是编译器用来实现过程/函数调用的一种数据结构,每次函数的调用,都会在调用栈(call stack)上维护一个独立的栈帧(stack frame) 栈帧的内容 函数的 ...
- 关于虚拟机使用桥接网络访问不到物理机IP的问题解决
问题描述 物理机可以ping 到虚拟机IP,虚拟机 ping 不到物理机IP 解决方法 关闭物理机防火墙,重启虚拟机
- MySQL进阶实战1,数据类型与三范式
一.选择优化的数据类型 MySQL支持的数据类型非常多,选择正确的数据类型对于获得高性能至关重要. 1.更小的 一般情况下,应该尽量使用较小的数据类型,更小的数据类型通常更快,因为占用更少的磁盘.内存 ...
- MySQL基础知识(二)-超详细 Linux安装MySQL5.7完整版教程及遇到的坑
1.简介 我们经常会在Linux上安装MySQL数据库,但是安装的时候总是会这里错,那里错,不顺利,今天整理了一下安装流程,连续安装来了两遍,没有遇到什么大错误,基本上十分钟左右可以搞定,教程如下.写 ...
- 彻底理解Python中的闭包和装饰器(上)
什么是闭包 闭包(Closure)其实并不是Python独有的特性,很多语言都有对闭包的支持.(当然,因为Python是笔者除C/C++之外学习的第二门语言,所以也是第一次遇到闭包.)简而言之,闭包实 ...