spark处理大规模语料库统计词汇
最近迷上了spark,写一个专门处理语料库生成词库的项目拿来练练手, github地址:https://github.com/LiuRoy/spark_splitter。代码实现参考wordmaker项目,有兴趣的可以看一下,此项目用到了不少很tricky的技巧提升性能,单纯只想看懂源代码可以参考wordmaker作者的一份简单版代码。
这个项目统计语料库的结果和执行速度都还不错,但缺点也很明显,只能处理GBK编码的文档,而且不能分布式运行,刚好最近在接触spark,所以用python实现了里面的算法,使之能处理更大规模的语料库,并且同时支持GBK和UTF8两种编码格式。
分词原理
wordmaker提供了一个统计大规模语料库词汇的算法,和结巴分词的原理不同,它不依赖已经统计好的词库或者隐马尔可夫模型,但是同样能得到不错的统计结果。原作者的文档提到是用多个线程独立计算各个文本块的词的信息,再按词的顺序分段合并,再计算各个段的字可能组成词的概率、左右熵,得到词语输出。下面就详细的讲解各个步骤:
- 读取文本,去掉文本中的换行、空格、标点,将语料库分解成一条一条只包含汉字的句子。
- 将上一步中的所有句子切分成各种长度的词,并统计所有词出现的次数。此处的切分只是把所有出现的可能都列出来,举个例子,天气真好 就可以切分为:天 天气 天气真 天气真好 气 气真 气真好 真 真好 好。不过为了省略一些没有必要的计算工作,此处设置了一个词汇长度限制。
- 针对上面切分出来的词汇,为了筛掉出那些多个词汇连接在一起的情况,会进一步计算这个词分词的结果,例如 月亮星星中的月亮和星星这两个词汇在步骤二得到的词汇中频率非常高,则认为月亮星星不是一个单独的词汇,需要被剔除掉。
- 为了进一步剔除错误切分的词汇,此处用到了信息熵的概念。举例:邯郸,邯字右边只有郸字一种组合,所以邯的右熵为0,这样切分就是错误的。因为汉字词语中汉字的关系比较紧密,如果把一个词切分开来,则他们的熵势必会小,只需要取一个合适的阈值过滤掉这种错误切分即可。
代码解释
原始的C++代码挺长,但是用python改写之后很少,上文中的1 2 3步用spark实现非常简单,代码在split函数中。第3部过滤后的结果已经相对较小,可以直接取出放入内存中,再计算熵过滤,在split中执行target_phrase_rdd.filter(lambda x: _filter(x))过滤的时候可以phrasedictmap做成spark中的广播变量,提升分布式计算的效率,因为只有一台机器,所以就没有这样做。split代码如下,原来很长的代码用python很容易就实现了。
def split(self):
"""spark处理"""
raw_rdd = self.sc.textFile(self.corpus_path) utf_rdd = raw_rdd.map(lambda line: str_decode(line))
hanzi_rdd = utf_rdd.flatMap(lambda line: extract_hanzi(line)) raw_phrase_rdd = hanzi_rdd.flatMap(lambda sentence: cut_sentence(sentence)) phrase_rdd = raw_phrase_rdd.reduceByKey(lambda x, y: x + y)
phrase_dict_map = dict(phrase_rdd.collect())
total_count = 0
for _, freq in phrase_dict_map.iteritems():
total_count += freq def _filter(pair):
phrase, frequency = pair
max_ff = 0
for i in xrange(1, len(phrase)):
left = phrase[:i]
right = phrase[i:]
left_f = phrase_dict_map.get(left, 0)
right_f = phrase_dict_map.get(right, 0)
max_ff = max(left_f * right_f, max_ff)
return total_count * frequency / max_ff > 100.0 target_phrase_rdd = phrase_rdd.filter(lambda x: len(x[0]) >= 2 and x[1] >= 3)
result_phrase_rdd = target_phrase_rdd.filter(lambda x: _filter(x))
self.result_phrase_set = set(result_phrase_rdd.keys().collect())
self.phrase_dict_map = {key: PhraseInfo(val) for key, val in phrase_dict_map.iteritems()}
分词结果
进入spark_splitter/splitter目录,执行命令PYTHONPATH=. spark-submit spark.py处理test/moyan.txt文本,是莫言全集,统计完成的结果在out.txt中,统计部分的结果如下,由于算法的原因,带有 的 地 这种连词词语不能正确的切分。
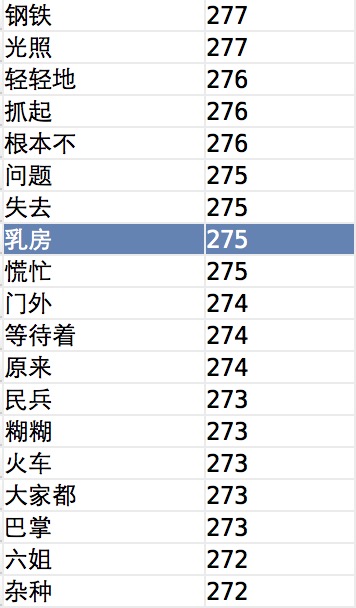
(我也不知道为什么这个词这么多)
问题统计
- 上述的算法不能去掉连词,结果中会出现很多类似于轻轻地 等待着这种词
- 单机上用spark处理小规模数据没有任何优势,比wordmaker中的C++代码慢很多
- 可以和结巴基于隐马尔科夫模型的分词结果做一下准确率的比较
spark处理大规模语料库统计词汇的更多相关文章
- Spark入门(三)--Spark经典的单词统计
spark经典之单词统计 准备数据 既然要统计单词我们就需要一个包含一定数量的文本,我们这里选择了英文原著<GoneWithTheWind>(<飘>)的文本来做一个数据统计,看 ...
- spark streaming - kafka updateStateByKey 统计用户消费金额
场景 餐厅老板想要统计每个用户来他的店里总共消费了多少金额,我们可以使用updateStateByKey来实现 从kafka接收用户消费json数据,统计每分钟用户的消费情况,并且统计所有时间所有用户 ...
- spark MLLib的基础统计部分学习
参考学习链接:http://www.itnose.net/detail/6269425.html 机器学习相关算法,建议初学者去看看斯坦福的机器学习课程视频:http://open.163.com/s ...
- Spark 大数据文本统计
此程序功能: 1.完成对10.4G.csv文件各个元素频率的统计 2.获得最大的统计个数 3.对获取到的统计个数进行降序排列 4.对各个元素出现次数频率的统计 import org.apache.sp ...
- python spark 通过key来统计不同values个数
>>> rdd = sc.parallelize([("), ("b", 1), ("a", 1), ("a", ...
- Spark Streaming:大规模流式数据处理的新贵(转)
原文链接:Spark Streaming:大规模流式数据处理的新贵 摘要:Spark Streaming是大规模流式数据处理的新贵,将流式计算分解成一系列短小的批处理作业.本文阐释了Spark Str ...
- Spark Streaming:大规模流式数据处理的新贵
转自:http://www.csdn.net/article/2014-01-28/2818282-Spark-Streaming-big-data 提到Spark Streaming,我们不得不说一 ...
- Spark MLlib LDA 基于GraphX实现原理及源代码分析
LDA背景 LDA(隐含狄利克雷分布)是一个主题聚类模型,是当前主题聚类领域最火.最有力的模型之中的一个,它能通过多轮迭代把特征向量集合按主题分类.眼下,广泛运用在文本主题聚类中. LDA的开源实现有 ...
- 学习笔记TF018:词向量、维基百科语料库训练词向量模型
词向量嵌入需要高效率处理大规模文本语料库.word2vec.简单方式,词送入独热编码(one-hot encoding)学习系统,长度为词汇表长度的向量,词语对应位置元素为1,其余元素为0.向量维数很 ...
随机推荐
- 分布式系列文章——Paxos算法原理与推导
Paxos算法在分布式领域具有非常重要的地位.但是Paxos算法有两个比较明显的缺点:1.难以理解 2.工程实现更难. 网上有很多讲解Paxos算法的文章,但是质量参差不齐.看了很多关于Paxos的资 ...
- Android指纹解锁
Android6.0及以上系统支持指纹识别解锁功能:项目中用到,特此抽离出来,备忘. 功能是这样的:在用户将app切换到后台运行(超过一定的时长,比方说30秒),再进入程序中的时候就会弹出指纹识别的界 ...
- C语言 · 矩阵乘法 · 算法训练
问题描述 输入两个矩阵,分别是m*s,s*n大小.输出两个矩阵相乘的结果. 输入格式 第一行,空格隔开的三个正整数m,s,n(均不超过200). 接下来m行,每行s个空格隔开的整数,表示矩阵A(i,j ...
- CI Weekly #10 | 2017 DevOps 趋势预测
2016 年的最后几个工作日,我们对 flow.ci Android & iOS 项目做了一些优化与修复: iOS 镜像 cocoapods 版本更新: fir iOS上传插件时间问题修复: ...
- svn 常用命令总结
svn 命令篇 svn pget svn:ignore // 查看忽略项 svn commit -m "提交说明" // 提交修改 svn up(update) // 获取最新版本 ...
- Android线程管理之ThreadLocal理解及应用场景
前言: 最近在学习总结Android的动画效果,当学到Android属性动画的时候大致看了下源代码,里面的AnimationHandler存取使用了ThreadLocal,激起了我很大的好奇心以及兴趣 ...
- 如何远程关闭一个ASP.NET Core应用?
在<历数依赖注入的N种玩法>演示系统自动注册服务的实例中,我们会发现输出的列表包含两个特殊的服务,它们的对应的服务接口分别是IApplicationLifetime和IHostingEnv ...
- Opserver开源的服务器监控系统(ASP.NET)
Opserver是Stack Exchange下的一个开源监控系统,系统本身由C#语言开发的ASP.NET(MVC)应用程序,无需任何复杂的应用配置,入门很快.下载地址:https://github. ...
- html5 与视频
1.视频支持格式. 有3种视频格式被浏览器广泛支持:.ogg,.mp4,.webm. Theora+Vorbis=.ogg (Theora:视频编码器,Vorbis:音频编码器) H.264+$$$ ...
- RSA非对称加密,使用OpenSSL生成证书,iOS加密,java解密
最近换了一份工作,工作了大概一个多月了吧.差不多得有两个月没有更新博客了吧.在新公司自己写了一个iOS的比较通用的可以架构一个中型应用的不算是框架的一个结构,并已经投入使用.哈哈 说说文章标题的相关的 ...