Apache Kylin在美团点评的应用
本文原载自大数据杂谈微信公众号。
感谢美团点评工程师高大月撰文并授权转载。
高大月,美团点评工程师,Apache Kylin PMC成员,目前主要在美团点评数据平台负责OLAP查询引擎的建设。 背景美团点评的OLAP需求大体分为两类:
即席查询:指用户通过手写SQL来完成一些临时的数据分析需求。这类需求的SQL形式多变、逻辑复杂,对响应时间没有严格的要求。
固化查询:指对一些固化下来的取数、看数的需求,通过数据产品的形式提供给用户,从而提高数据分析和运营的效率。这类需求的SQL有固定的模式,对响应时间有比较高的要求 。
我们针对即席查询提供了Hive和Presto两个引擎。而固化查询由于需要秒级响应,很长一段时间都是通过先在数仓对数据做预聚合,再将聚合表导入MySQL提供查询实现的。但是随着公司业务数据量和复杂度的不断提升,从2015年开始,这个方案出现了三个比较突出的问题:
随着维度的不断增加,在数仓中维护各种维度组合的聚合表的成本越来越高,数据开发效率明显下降;
数据量超过千万行后,MySQL的导入和查询变得非常慢,经常把MySQL搞崩,DBA的抱怨很大;
由于大数据平台缺乏更高效率的查询引擎,查询需求都跑在Hive/Presto上,导致集群的计算压力大,跟不上业务需求的增长。
为了解决这些痛点,我们在2015年末开始调研更高效率的OLAP引擎,寻找固化查询场景的解决方案。
为什么选择Kylin在调研了市面上主流的开源OLAP引擎后,我们发现,目前还没有一个系统能够满足各种场景的查询需求。其本质原因是,没有一个系统能同时在数据量、性能、和灵活性三个方面做到完美,每个系统在设计时都需要在这三者间做出取舍。
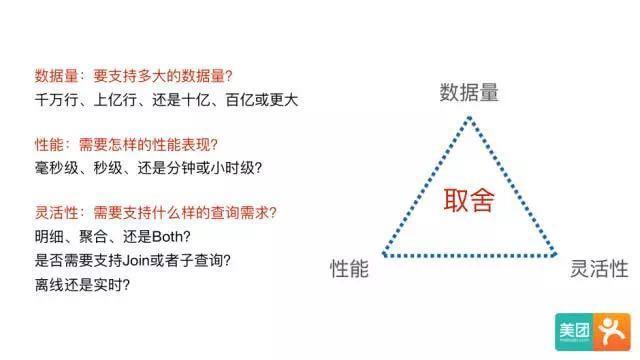
例如:
MPP架构的系统(Presto/Impala/SparkSQL/Drill等)有很好的数据量和灵活性支持,但是对响应时间是没有保证的。当数据量和计算复杂度增加后,响应时间会变慢,从秒级到分钟级,甚至小时级都有可能。
搜索引擎架构的系统(Elasticsearch等)相对比MPP系统,在入库时将数据转换为倒排索引,采用Scatter-Gather计算模型,牺牲了灵活性换取很好的性能,在搜索类查询上能做到亚秒级响应。但是对于扫描聚合为主的查询,随着处理数据量的增加,响应时间也会退化到分钟级。
预计算系统(Druid/Kylin等)则在入库时对数据进行预聚合,进一步牺牲灵活性换取性能,以实现对超大数据集的秒级响应。
有了这套框架,我们不难结合美团点评的自身需求特点,选择合适的OLAP引擎。
 可以看出,我们对数据量和性能的要求是比较高的。MPP和搜索引擎系统无法满足超大数据集下的性能要求,因此很自然地会考虑预计算系统。而Druid主要面向的是实时Timeseries数据,我们虽然也有类似的场景,但主流的分析还是面向数仓中按天生产的结构化表,因此Kylin的MOLAP Cube方案是最适合我们场景的引擎。
可以看出,我们对数据量和性能的要求是比较高的。MPP和搜索引擎系统无法满足超大数据集下的性能要求,因此很自然地会考虑预计算系统。而Druid主要面向的是实时Timeseries数据,我们虽然也有类似的场景,但主流的分析还是面向数仓中按天生产的结构化表,因此Kylin的MOLAP Cube方案是最适合我们场景的引擎。
Kylin的使用现状2016年初,我们开始向各个业务线推广基于Kylin的解决方案。经过一年的努力,Kylin已经应用到了美团点评的几乎所有主要业务线上,并且在外卖、酒旅等数个业务线得到了大规模的使用,Kylin已经成为了这些业务的首选OLAP引擎。
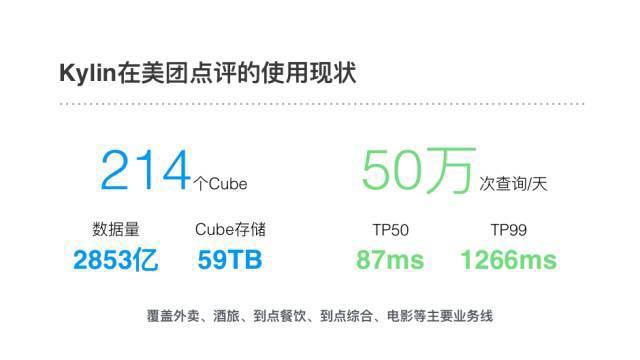
截至16年底,生产环境共有214个Cube,包含的数据总行数为2853亿行,Cube在HBase中的存储有59TB。日查询次数超过了50万次,TP50查询时延87ms,TP99时延1266ms,很好地满足了我们对性能的要求。
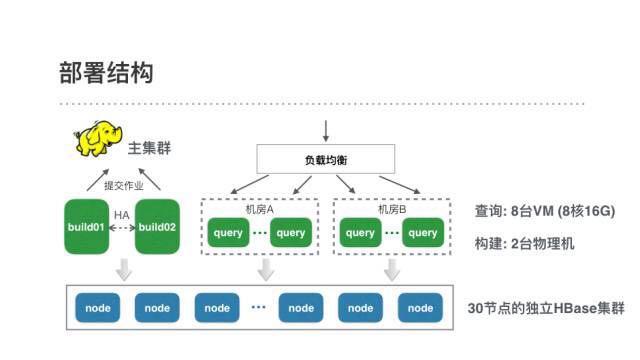
为了支持这些需求,我们的线上环境包含一个30节点的Kylin专属HBase集群,2台用于Cube构建的物理机,和8台8核16G的VM用作Kylin的查询机。Cube的构建是运行在主计算集群的MR作业,各业务线的构建任务拆分到了他们各自的资源队列上。
由于Kylin对外是REST接口,我们接入了公司统一的http服务治理框架来实现负载均衡和平滑重启。
“维度爆炸”问题在实践中是可解的提到MOLAP Cube方案,很多没接触过Kylin的人会担心“维度爆炸”的问题,即每增加一个维度,由于维度组合数翻倍,Cube的计算和存储量也会成倍增长。我们起初其实也有同样的担心,但调研和使用Kylin一阵子后发现,这个问题在实践中并没有想象的严重。这主要是因为
Kylin支持Partial Cube,不需要对所有维度组合都进行预计算;
实际业务中,维度之间往往存在衍生关系,而Kylin可以把衍生维度的计算从预计算推迟到查询处理阶段。

以事实表上的衍生维度为例,我们业务中的很多维度都是(ID, NAME)成对出现的。查询时需要对ID列进行过滤,但显示时只需要取对应的NAME列。如果把这两列都作为维度,维度个数会翻倍。而在Kylin中,可以把NAME作为ID列的extendedcolumn指标,这样Cube中的维度个数就减半了。

下面分享一些我们线上Cube的统计数据。
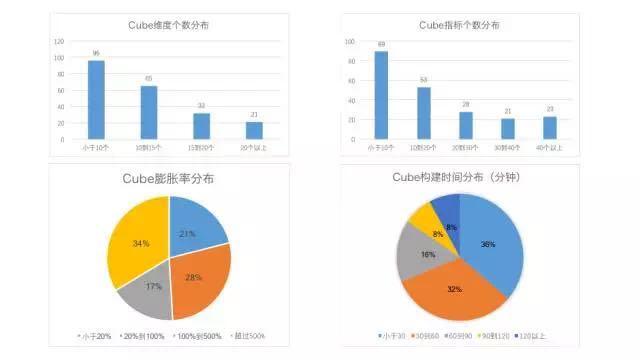
可以看到,采用衍生维度后,90%的场景可以把Cube中的维度个数(Rowkey列数)控制在20个以内。指标个数呈现长尾分布,小于10个指标的Cube是最多的,不过也有近一半的Cube指标数超过20。总共有382个去重指标,占到了总指标数的10%,绝大多数都是精确去重指标。49%的Cube膨胀率小于100%,即Cube存储量不超过上游Hive表。68%的Cube能够在1小时内完成构建,92%在2小时内完成构建。
美团外卖的使用案例下面分享一下Kylin在美团外卖的使用案例,感谢外卖的同事 靳国卫和惠明 提供材料。
外卖数据业务对交互式的OLAP分析有着很强的需求。在使用Kylin以前,采用的是在Hive中开发聚合表再导入MySQL的方案。随着业务数据量高速增长和需求的不断升级,这套方案遇到了开头提到的查询效率和开发效率的双重问题。

在使用Kylin后,除了查询性能的显著提升,外卖的数据开发方式发生了很大的改变。原来需要做繁琐的聚合层和主题层数据,现在只需要把重点放到基础数据的建设上,预计算的工作交给Kylin就行了。在对同一个需求同时采用老方案和Kylin方案实施后发现,使用Kylin后的数据开发效率提升了3倍。


下面是一个对流量数据应用Kylin的具体案例。我们在Kylin 1.5.3版本添加了全局字典,实现了上亿基数、任意类型字段(例如设备ID)的精确去重计数,把Kylin的使用场景扩宽到了流量数据。



平台化经验与思考一个开源项目从run起来到真正作为平台化的服务提供出去,中间会遇到很多的挑战和问题需要解决。下面是我们总结的一些经验,在这里分享给大家,也欢迎同行们和我们一起探讨。




Apache Kylin在美团点评的应用的更多相关文章
- Druid SQL和Security在美团点评的实践
分享嘉宾:高大月@美团点评,Apache Kylin PMC成员,Druid Commiter 编辑整理:Druid中国用户组 6th MeetUp 出品平台:DataFunTalk -- 导读: 长 ...
- 【转】使用Apache Kylin搭建企业级开源大数据分析平台
http://www.thebigdata.cn/JieJueFangAn/30143.html 本篇文章整理自史少锋4月23日在『1024大数据技术峰会』上的分享实录:使用Apache Kylin搭 ...
- 大数据分析神兽麒麟(Apache Kylin)
1.Apache Kylin是什么? 在现在的大数据时代,越来越多的企业开始使用Hadoop管理数据,但是现有的业务分析工具(如Tableau,Microstrategy等)往往存在很大的局限,如难以 ...
- 深入详解美团点评CAT跨语言服务监控(一) CAT简介与部署
前言: CAT是一个实时和接近全量的监控系统,它侧重于对Java应用的监控,除了与点评RPC组件融合的很好之外,他将会能与Spring.MyBatis.Dubbo 等框架以及Log4j 等结合,支持P ...
- 大数据分析界的“神兽”Apache Kylin有多牛?【转】
本文作者:李栋,来自Kyligence公司,也是Apache Kylin Committer & PMC member,在加入Kyligence之前曾就职于eBay.微软. 1.Apache ...
- 使用Apache Kylin搭建企业级开源大数据分析平台
转:http://www.thebigdata.cn/JieJueFangAn/30143.html 我先做一个简单介绍我叫史少锋,我曾经在IBM.eBay做过大数据.云架构的开发,现在是Kylige ...
- Apache Kylin 概述
1 Kylin是什么 今天,随着移动互联网.物联网.AI等技术的快速兴起,数据成为了所有这些技术背后最重要,也是最有价值的"资产".如何从数据中获得有价值的信息?这个问题驱动了相关 ...
- [转帖]Apache Kylin 概述
Apache Kylin 概述 https://www.cnblogs.com/xiaodf/p/11671095.html 1 Kylin是什么 今天,随着移动互联网.物联网.AI等技术的快速兴起, ...
- 浅淡 Apache Kylin 与 ClickHouse 的对比
作者简介 周耀,Kyligence 解决方案架构师,Apache Kylin.Apache Superset Contributor. Apache Kylin 和 ClickHouse 都是目前市场 ...
随机推荐
- 05- if-else语句、循环for
if-else 语句 if是条件语句.if语句的语法是 if 条件{ #注意大括号和条件之间不能换行 执行代码 } if语句还包括else if 和 else 部分 package main impo ...
- Go语言 ( 切片)
本文主要介绍Go语言中切片(slice)及它的基本使用. 引子 因为数组的长度是固定的并且数组长度属于类型的一部分,所以数组有很多的局限性. 例如: func arraySum(x []int) in ...
- Springboot 结合百度IORC实现自定义模板图片识别
前言: 首先呢,最近再公司的项目当中遇到这样的一个问题,就是需要识别图片,提取图片当中的关键语句,而且识别的语句当然是人家手写体识别,翻来覆去一想,最终还是决定使用百度的OCR帮助我解决这一项需求 话 ...
- shell 学习笔记9-while/until循环语句
一.while循环语句 1.循环语句 循环愈久就是重复执行一条指令或一组执行,知道条件不在满足时停止,shell循环语句包括,while.until.for.select语句 2.while循环 主要 ...
- openwrt luci web分析
openwrt luci web分析 来源 https://www.jianshu.com/p/596485f95cf2 www/cbi-bin/luci #!/usr/bin/lua --cgi的执 ...
- Web应用和Web框架
一.Web应用 二.Web框架 三.wsgiref模块 一.Web应用 1.什么是Web应用? Web应用程序是一种可以通过Web访问的应用程序,特点是用户很容易访问,只需要有浏览器即可,不需要安装其 ...
- Elasticsearch 及 Kibana 安装篇
简介 官网-安装介绍 这里记载了各个软件包的安装方法,Linux Mac Windows-- 本文记载的是在 CentOS 系统安装 Elasticsearch 7.0.0 版本的步骤. 安装 Jav ...
- 二叉树&满二叉树与完全二叉树
二叉树的定义 二叉树(Binary Tree)是n(n≥0)个元素的有限集合,该集合为空或者为由一个称为"根"的元素及两个不相交的.被分别称为左子树和右子树的二叉树组成 二叉树的基 ...
- @ConfigurationProperties注解和@Value注解的区别
都是读取配置文件属性 1. @ConfigurationProperties(prefix = "person")读取多个属性 @Component @Configuration ...
- MySQL Backup--Xtrabackup远程备份和限速备份
使用xbstream 备份到远程服务器 ##xbstream 备份到远程服务器 innobackupex \ --defaults-file="/export/servers/mysql/e ...