Spark实现分组TopN
一.概述
在许多数据中,都存在类别的数据,在一些功能中需要根据类别分别获取前几或后几的数据,用于数据可视化或异常数据预警。在这种情况下,实现分组TopN就显得非常重要了,因此,使用了Spark聚合函数和排序算法实现了分布式TopN计算功能。
二.代码实现
package scala
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.types.{StringType, StructField, StructType}
import org.apache.spark.sql.{Row, SparkSession}
/**
* 计算分组topN
* Created by Administrator on 2019/11/20.
*/
object GroupTopN {
Logger.getLogger("org").setLevel(Level.WARN) // 设置日志级别
def main(args: Array[String]) {
//创建测试数据
val test_data = Array("CJ20191120,201911", "CJ20191120,201910", "CJ20191105,201910", "CJ20191105,201909", "CJ20191111,201910")
val spark = SparkSession.builder().appName("GroupTopN").master("local[2]").getOrCreate()
val sc = spark.sparkContext
val test_data_rdd = sc.parallelize(test_data).map(row => {
val Array(scene, cycle) = row.split(",")
Row(scene, cycle)
})
// 设置数据模式
val structType = StructType(Array(
StructField("scene", StringType, true),
StructField("cycle", StringType, true)
))
// 转换为df
val test_data_df = spark.createDataFrame(test_data_rdd, structType)
test_data_df.createOrReplaceTempView("test_data_df")
// 拼接周期
val scene_ws = spark.sql("select scene,concat_ws(',',collect_set(cycle)) as cycles from test_data_df group by scene")
scene_ws.count()
scene_ws.show()
scene_ws.createOrReplaceTempView("scene_ws")
/**
* 定义参数确定N的大小,暂定为1
*/
val sum = 1
// 创建广播变量,把N的大小广播出去
val broadcast = sc.broadcast(sum)
/**
* 定义Udf实现获取组内的前N个数据
*/
spark.udf.register("getTopN", (cycles : String) => {
val sum = broadcast.value
var mid = ""
if(cycles.contains(",")){ // 多值
val cycle = cycles.split(",").sorted.reverse // 降序排序
val min = Math.min(cycle.length, sum)
for(i <- 0 until min){
if(mid.equals("")){
mid = cycle(i)
}else{
mid += "," + cycle(i)
}
}
}else{ // 单值
mid = cycles
}
mid
})
val result = spark.sql("select scene,getTopN(cycles) cycles from scene_ws")
result.show()
spark.stop()
}
}
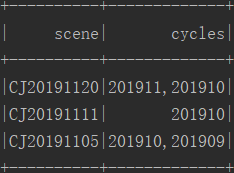
三.结果

四.备注
当N大于1时,多个数据会拼接在一起,若想每个一行,可是使用使用列转行功能,参考我的博客:https://www.cnblogs.com/yszd/p/11266552.html
Spark实现分组TopN的更多相关文章
- 020 Spark中分组后的TopN,以及Spark的优化(重点)
一:准备 1.源数据 2.上传数据 二:TopN程序编码 1.程序 package com.ibeifeng.bigdata.spark.core import java.util.concurren ...
- 大数据学习day29-----spark09-------1. 练习: 统计店铺按月份的销售额和累计到该月的总销售额(SQL, DSL,RDD) 2. 分组topN的实现(row_number(), rank(), dense_rank()方法的区别)3. spark自定义函数-UDF
1. 练习 数据: (1)需求1:统计有过连续3天以上销售的店铺有哪些,并且计算出连续三天以上的销售额 第一步:将每天的金额求和(同一天可能会有多个订单) SELECT sid,dt,SUM(mone ...
- QL查询案例:取得分组 TOP-N
[转]SQL查询案例:取得分组 TOP-N CREATE TABLE TopnTest ( name VARCHAR(10), --姓名 procDate DATETIME, ...
- 用Spark完成复杂TopN计算的两种逻辑
如果有商品品类的数据pairRDD(categoryId,clickCount_orderCount_payCount),用Spark完成Top5,你会怎么做? 这里假设使用Java语言进行编写,那么 ...
- 取分组TOPN好理解案例
- 分别使用Hadoop和Spark实现TopN(1)——唯一键
0.简介 TopN算法是一个经典的算法,由于每个map都只是实现了本地的TopN算法,而假设map有M个,在归约的阶段只有M x N个,这个结果是可以接受的并不会造成性能瓶颈. 这个TopN算法在ma ...
- TopN问题(分别使用Hadoop和Spark实现)
简介 TopN算法是一个经典的算法,由于每个map都只是实现了本地的TopN算法,而假设map有M个,在归约的阶段只有M x N个,这个结果是可以接受的并不会造成性能瓶颈. 这个TopN算法在map阶 ...
- spark面试总结3
Spark core面试篇03 1.Spark使用parquet文件存储格式能带来哪些好处? 1) 如果说HDFS 是大数据时代分布式文件系统首选标准,那么parquet则是整个大数据时代文件存储格式 ...
- Spark面试相关
Spark Core面试篇01 随着Spark技术在企业中应用越来越广泛,Spark成为大数据开发必须掌握的技能.前期分享了很多关于Spark的学习视频和文章,为了进一步巩固和掌握Spark,在原有s ...
随机推荐
- 解决Android中AsyncTask的多线程阻塞问题
Android开发中执行耗时操作并更新UI时,通常有三种方式:1.直接调用runOnUiThread(new Runnable(){}),使用简单,但不能在Activity之外的环境使用,如View. ...
- 点云深度学习的3D场景理解
转载请注明本文链接: https://www.cnblogs.com/Libo-Master/p/9759130.html PointNet: Deep Learning on Point Sets ...
- oracle左连接与右连接
left join(左联接) ---返回左表中的所有记录和右表中条件字段相等的记录. right join(右联接) ---返回右表中的所有记录和左表中联结字段相等的记录 inne ...
- apktool android studio 调试 smali code, 重新打包
虽然有些菜单的位置跟新版的Android Stuido 3.4 有些不同,但是能用. https://crosp.net/blog/software-development/mobile/androi ...
- 单交换机VLAN划分(基于Cisco模拟器)
实验目的: (1)掌握交换机配置的几种模式及基本配置命令. (2)掌握VLAN的原理及基于交换机端口的VLAN划分方法. 实验设备: 交换机一台,主机四台,直通线四根 实验步骤: 1.给交换机划分VL ...
- 11/11 <Topological Sort> 207
207. Course Schedule 我们定义二维数组 graph 来表示这个有向图,一维数组 in 来表示每个顶点的入度.我们开始先根据输入来建立这个有向图,并将入度数组也初始化好.然后我们定义 ...
- bootstrap-table 列拖动
1.页面js/css <!-- bootstrap 插件样式 --> <link th:href="@{/common/bootstrap-3.3.6/css/bootst ...
- MySQL实战45讲学习笔记:第十九讲
一.引子 一般情况下,如果我跟你说查询性能优化,你首先会想到一些复杂的语句,想到查询需要返回大量的数据.但有些情况下,“查一行”,也会执行得特别慢.今天,我就跟你聊聊这个有趣的话题,看看什么情况下,会 ...
- cordova生成签名的APK
所有的Android应用程序在发布之前都要求用一个证书进行数字签名,anroid系统是不会安装没有进行签名的程序(安全考虑,可以查找相关文档) 签名过程详情见:https://www.cnblogs. ...
- ROS-RouterOS KVM 安装 OpenWrt 旁路使用
原文: http://bbs.routerclub.com/thread-104864-1-1.html 这里所讲是X86架构的RouteROS的KVM虚拟机,其实RouterOS的KVM很早就有,大 ...