Linux性能优化实战学习笔记:第二十三讲
一、索引节点和目录
1、索引节点

2、目录项

3、关系

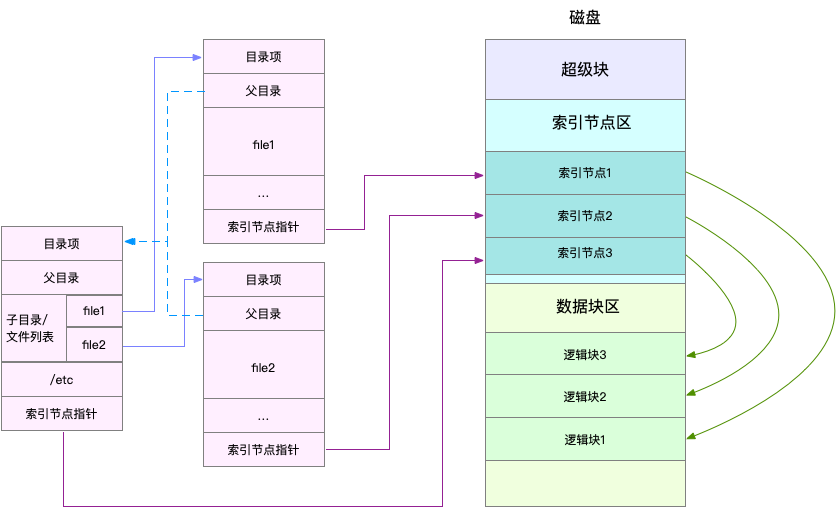
为了帮助你理解目录项、索引节点以及文件数据的关系,我画了一张示意图,你可以对照这张图,来回忆刚刚讲过的内容,把只知识和细节串联起来
4、Slabs

5、系统格式化

二、虚拟文件系统
1、Linux文件系统的架构图
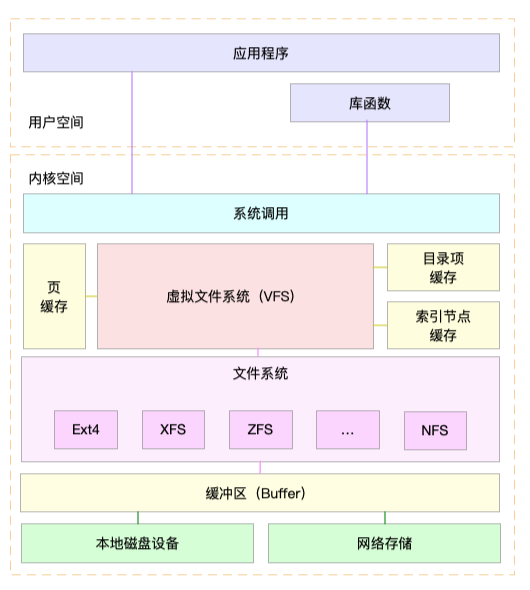
这里、我画了一张Linux文件系统的架构图,帮你更好地理解系统调用、VFS、缓存、文件系统以及块存储之间的关系图
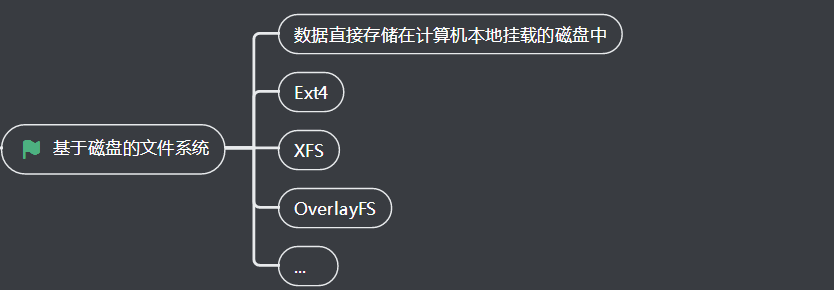
2、基于磁盘的文件系统
2、基于内存的文件系统

3、网络文件系统

三、文件系统I/O
1、cat过程解析

2、标准库缓存

3、操作系统页缓存

4、是否阻塞自身运行

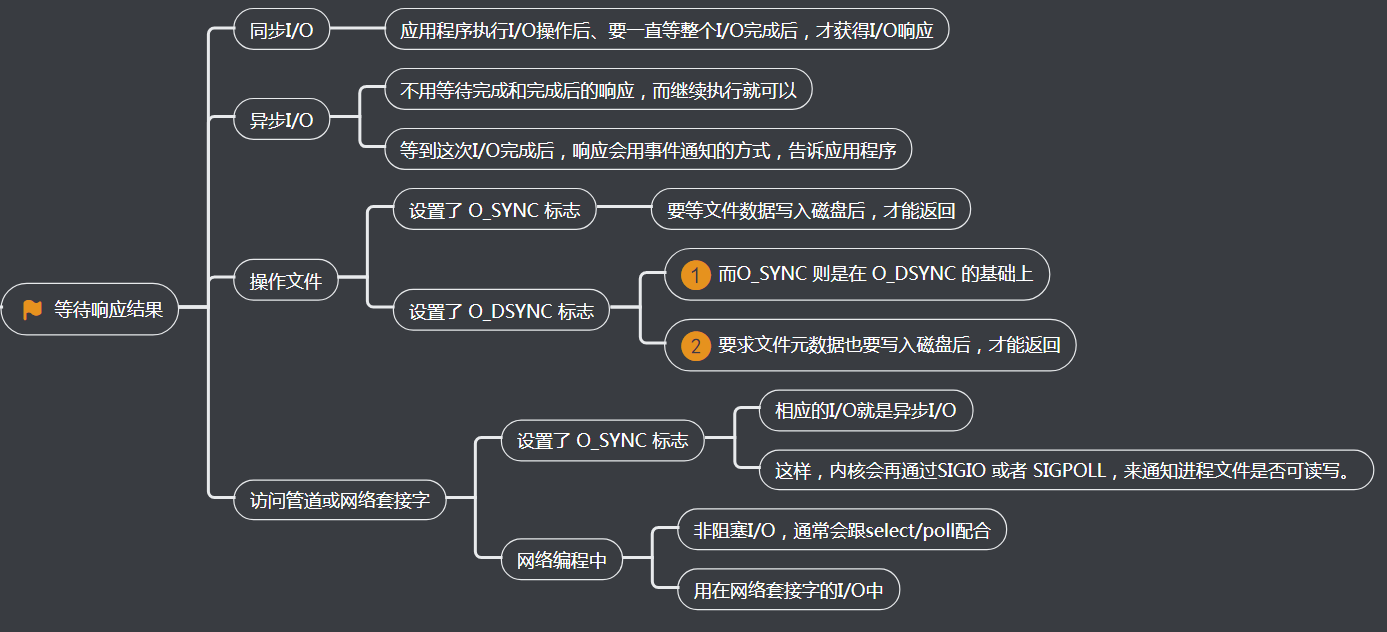
5、等待响应结果
四、性能观测
1、容量
1、查看文件系统的磁盘空间使用情况
[root@luoahong ~]# df /dev/sda1
Filesystem 1K-blocks Used Available Use% Mounted on
devtmpfs 4010852 0 4010852 0% /dev
2、df -h获得更好的可读性
[root@luoahong ~]# df -h /dev/sda1
Filesystem Size Used Avail Use% Mounted on
devtmpfs 3.9G 0 3.9G 0% /dev
3、查看索引节点使用情况
[root@luoahong ~]# df -i /dev/sda1
Filesystem Inodes IUsed IFree IUse% Mounted on
devtmpfs 1002713 401 1002312 1% /dev
4、小结

2、缓存
1、free输出的Cache是页缓存和可回收Slab缓存的和
[root@luoahong ~]# cat /proc/meminfo | grep -E "SReclaimable|Cached"
Cached: 314664 kB
SwapCached: 0 kB
SReclaimable: 37348 kB
2、所有目录项和各文件系统索引节点的缓存情况:
[root@luoahong ~]# cat /proc/slabinfo | grep -E '^#|dentry|inode'
# name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata <active_slabs> <num_slabs> <sharedavail>
ovl_inode 98 98 664 49 8 : tunables 0 0 0 : slabdata 2 2 0
xfs_inode 7740 8424 896 36 8 : tunables 0 0 0 : slabdata 234 234 0
mqueue_inode_cache 36 36 896 36 8 : tunables 0 0 0 : slabdata 1 1 0
hugetlbfs_inode_cache 53 53 608 53 8 : tunables 0 0 0 : slabdata 1 1 0
sock_inode_cache 2550 2550 640 51 8 : tunables 0 0 0 : slabdata 50 50 0
shmem_inode_cache 1764 1833 696 47 8 : tunables 0 0 0 : slabdata 39 39 0
proc_inode_cache 2945 3038 656 49 8 : tunables 0 0 0 : slabdata 62 62 0
inode_cache 25746 25872 584 56 8 : tunables 0 0 0 : slabdata 462 462 0
dentry 39767 42966 192 42 2 : tunables 0 0 0 : slabdata 1023 1023 0
3、找到内存占用最多的缓存类型
[root@luoahong ~]# slabtop Active / Total Objects (% used) : 384466 / 393627 (97.7%)
Active / Total Slabs (% used) : 7262 / 7262 (100.0%)
Active / Total Caches (% used) : 95 / 140 (67.9%)
Active / Total Size (% used) : 107507.27K / 111249.76K (96.6%)
Minimum / Average / Maximum Object : 0.01K / 0.28K / 16.62K OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME
48420 48420 100% 0.13K 807 60 6456K kernfs_node_cache
43008 39809 92% 0.19K 1024 42 8192K dentry
33799 33799 100% 0.05K 463 73 1852K Acpi-Parse
25872 25746 99% 0.57K 462 56 14784K inode_cache
25536 23690 92% 0.50K 399 64 12768K kmalloc-512
21760 21760 100% 0.03K 170 128 680K kmalloc-32
18688 18688 100% 0.02K 73 256 292K kmalloc-16
12800 12764 99% 0.20K 320 40 2560K vm_area_struct
12352 11907 96% 0.06K 193 64 772K anon_vma_chain
10248 10248 100% 0.07K 183 56 732K Acpi-Operand
9920 9211 92% 0.06K 155 64 620K kmalloc-64
9786 9786 100% 0.09K 233 42 932K kmalloc-96
9728 9728 100% 0.01K 19 512 76K kmalloc-8
9024 8704 96% 0.25K 141 64 2256K filp
8992 8844 98% 2.00K 562 16 17984K kmalloc-2k
8424 7740 91% 0.88K 234 36 7488K xfs_inode
8262 8262 100% 0.04K 81 102 324K Acpi-Namespace
7590 7590 100% 0.09K 165 46 660K anon_vma
5208 5208 100% 0.57K 93 56 2976K radix_tree_node
4128 3841 93% 1.00K 129 32 4128K kmalloc-1k
3904 3904 100% 0.12K 61 64 488K pid
3776 3520 93% 0.25K 59 64 944K skbuff_head_cache
3740 3740 100% 0.05K 44 85 176K ftrace_event_field
3276 3276 100% 0.19K 78 42 624K cred_jar
3038 2945 96% 0.64K 62 49 1984K proc_inode_cache
2880 2288 79% 0.12K 45 64 360K kmalloc-128
4、小结


Linux性能优化实战学习笔记:第二十三讲的更多相关文章
- Linux性能优化实战学习笔记:第三讲
一.关于上下文切换的几个为什么 1. 上下文切换是什么? 上下文切换是对任务当前运行状态的暂存和恢复 2. CPU为什么要进行上下文切换? 当多个进程竞争CPU的时候,CPU为了保证每个进程能公平被调 ...
- Linux性能优化实战学习笔记:第四十五讲
一.上节回顾 专栏更新至今,四大基础模块的最后一个模块——网络篇,我们就已经学完了.很开心你还没有掉队,仍然在积极学习思考和实践操作,热情地留言和互动.还有不少同学分享了在实际生产环境中,碰到各种性能 ...
- Linux性能优化实战学习笔记:第三十六讲
一.上节总结回顾 上一节,我们回顾了经典的 C10K 和 C1000K 问题.简单回顾一下,C10K 是指如何单机同时处理 1 万个请求(并发连接 1 万)的问题,而 C1000K 则是单机支持处理 ...
- Linux性能优化实战学习笔记:第四十三讲
一.上节回顾 上一节,我们了解了 NAT(网络地址转换)的原理,学会了如何排查 NAT 带来的性能问题,最后还总结了 NAT 性能优化的基本思路.我先带你简单回顾一下. NAT 基于 Linux 内核 ...
- Linux性能优化实战学习笔记:第四十四讲
一.上节回顾 上一节,我们学了网络性能优化的几个思路,我先带你简单复习一下. 在优化网络的性能时,你可以结合 Linux 系统的网络协议栈和网络收发流程,然后从应用程序.套接字.传输层.网络层再到链路 ...
- Linux性能优化实战学习笔记:第五十二讲
一.上节回顾 上一节,我们一起学习了怎么使用动态追踪来观察应用程序和内核的行为.先简单来回顾一下.所谓动态追踪,就是在系统或者应用程序还在正常运行的时候,通过内核中提供的探针,来动态追踪它们的行为,从 ...
- Linux性能优化实战学习笔记:第五十五讲
一.上节回顾 上一节,我们一起学习了,应用程序监控的基本思路,先简单回顾一下.应用程序的监控,可以分为指标监控和日志监控两大块. 指标监控,主要是对一定时间段内的性能指标进行测量,然后再通过时间序列的 ...
- Linux性能优化实战学习笔记:第五十八讲
一.上节回顾 专栏更新至今,咱们专栏最后一部分——综合案例模块也要告一段落了.很高兴看到你没有掉队,仍然在积极学习思考.实践操作,并热情地分享你在实际环境中,遇到过的各种性能问题的分析思路以及优化方法 ...
- Linux性能优化实战学习笔记:第三十二讲
一.上节总结 专栏更新至今,四大基础模块的第三个模块——文件系统和磁盘 I/O 篇,我们就已经学完了.很开心你还没有掉队,仍然在积极学习思考和实践操作,并且热情地留言与讨论. 今天是性能优化的第四期. ...
- Linux性能优化实战学习笔记:第五十六讲
一.上节回顾 上一节,我带你一起梳理了,性能问题分析的一般步骤.先带你简单回顾一下. 我们可以从系统资源瓶颈和应用程序瓶颈,这两个角度来分析性能问题的根源. 从系统资源瓶颈的角度来说,USE 法是最为 ...
随机推荐
- NXP官方的i.mx6ul板级uboot源码适配
1.前言 CoM-P6UL是盈鹏飞科技有限公司基于NXP原厂I.MX6UL芯片生产研发的核心板,本文将对CoM-P6UL适配NXP的基于Linux4.1.15版本的uboot板级源码. 2.开发环境 ...
- redis命令之 ----SortedSed(有序集合)
ZADD ZADD key score member [[score member] [score member] ...] 将一个或多个 member 元素及其 score 值加入到有序集 key ...
- 微博Feed流
一.微博核心业务图 二.微博的架构设计图 三.简述 先来看看Feed流中的一些概念: Feed:Feed流中的每一条状态或者消息都是Feed,比如微博中的一条微博就是一个Feed. Feed流:持续更 ...
- 你真的了解nginx重定向URI?-rewrite和alias指令
未经允许不得转载!最近发现有博主转载我的文章,并没有跟我打招呼,也没有注明出处!!!! 熟悉Nginx的同学都知道Nginx可以用来做负载均衡和反向代理,非常好用.做前后端分离也是非常的方便. 今天我 ...
- 压缩20M文件从30秒到1秒的优化过程
文章来源公众号:IT牧场 有一个需求需要将前端传过来的10张照片,然后后端进行处理以后压缩成一个压缩包通过网络流传输出去.之前没有接触过用Java压缩文件的,所以就直接上网找了一个例子改了一下用了,改 ...
- java构建树形列表(带children属性)
一些前端框架提供的树形表格需要手动构建树形列表(带children属性的对象数组),这种结构一般是需要在Java后台构建好. 构建的方式是通过id字段与父id字段做关联,通过递归构建children字 ...
- Topshelf + QuartzNet 实现挂载在 WIndows Services 中的定时任务
直接贴代码了: 首先我们可以把所有的 Job 放到一个单独的 DLL 中,好处是可以共享这些业务 Job.比如我们新建一个 QuartzNetDemo.WinService.Jobs 的类库. 然后, ...
- C 内置函数
*) strcat()用于连接两个字符串 *) 函数 memcpy() 用来复制内存到另一个位置.
- mssql like 优化
SqlServer中like 的查询一般我们都不推荐,但是当数据库某个字段的值是用分隔符区分的多个链接字符,比如,12,11,23等这样的类型.可能我们需要判断是否包含12. 这个时候我们想到的当然是 ...
- Mysql EF Core 快速构建 Web Api
(1)首先创建一个.net core web api web项目; (2)因为我们使用的是ef连接mysql数据库,通过NuGet安装MySql.Data.EntityFrameworkCore,以来 ...