Python数据挖掘之随机森林
主要是使用随机森林将four列缺失的数据补齐。
# fit到RandomForestRegressor之中,n_estimators代表随机森林中的决策树数量
#n_jobs这个参数告诉引擎有多少处理器是它可以使用。 “-1”意味着没有限制,而“1”值意味着它只能使用一个处理器。import pandas as pd #数据分析,引入pandas包,用以数据分析
import pandas as pd #数据分析,引入pandas包,用以数据分析
from sklearn.ensemble import RandomForestRegressor #随机森林 data=[[2,3,4],[6,7,8],[9,10,11,12],[52,84,62],[53,95,41,1],[12,92,12,21],[63,12,41,15],[85,76,43,1],[15,123,45,91],[952,42,1,3]]
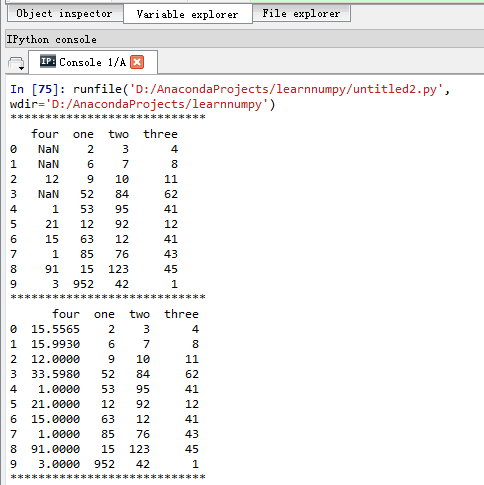
df=pd.DataFrame(data,columns=['one','two','three','four']) df2=df[['four','one','two','three']] print('****************************')
print(df2) known_data=df2[df2.four.notnull()].as_matrix()
unknown_data=df2[df2.four.isnull()].as_matrix() y=known_data[:,0]
X=known_data[:,1:] rfr = RandomForestRegressor(n_estimators=2000, n_jobs=-1) rfr.fit(X, y) predictedDatas = rfr.predict(unknown_data[:,1:])
print('****************************')
df2.loc[(df2.four.isnull()),'four']=predictedDatas
print(df2)
print('****************************')
结果:
Python数据挖掘之随机森林的更多相关文章
- Python 实现的随机森林
随机森林是一个高度灵活的机器学习方法,拥有广泛的应用前景,从市场营销到医疗保健保险. 既可以用来做市场营销模拟的建模,统计客户来源,保留和流失.也可用来预测疾病的风险和病患者的易感性. 随机森林是一个 ...
- Python机器学习笔记——随机森林算法
随机森林算法的理论知识 随机森林是一种有监督学习算法,是以决策树为基学习器的集成学习算法.随机森林非常简单,易于实现,计算开销也很小,但是它在分类和回归上表现出非常惊人的性能,因此,随机森林被誉为“代 ...
- 机器学习之路:python 集成分类器 随机森林分类RandomForestClassifier 梯度提升决策树分类GradientBoostingClassifier 预测泰坦尼克号幸存者
python3 学习使用随机森林分类器 梯度提升决策树分类 的api,并将他们和单一决策树预测结果做出对比 附上我的git,欢迎大家来参考我其他分类器的代码: https://github.com/l ...
- 随机森林入门攻略(内含R、Python代码)
随机森林入门攻略(内含R.Python代码) 简介 近年来,随机森林模型在界内的关注度与受欢迎程度有着显著的提升,这多半归功于它可以快速地被应用到几乎任何的数据科学问题中去,从而使人们能够高效快捷地获 ...
- 【Python数据挖掘】决策树、随机森林、Bootsing、
决策树的定义 决策树(decision tree)是一个树结构(可以是二叉树或非二叉树).其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别. ...
- 如何在Python中从零开始实现随机森林
欢迎大家前往云+社区,获取更多腾讯海量技术实践干货哦~ 决策树可能会受到高度变异的影响,使得结果对所使用的特定测试数据而言变得脆弱. 根据您的测试数据样本构建多个模型(称为套袋)可以减少这种差异,但是 ...
- Python中随机森林的实现与解释
使用像Scikit-Learn这样的库,现在很容易在Python中实现数百种机器学习算法.这很容易,我们通常不需要任何关于模型如何工作的潜在知识来使用它.虽然不需要了解所有细节,但了解机器学习模型是如 ...
- python实现随机森林、逻辑回归和朴素贝叶斯的新闻文本分类
实现本文的文本数据可以在THUCTC下载也可以自己手动爬虫生成, 本文主要参考:https://blog.csdn.net/hao5335156/article/details/82716923 nb ...
- H2O中的随机森林算法介绍及其项目实战(python实现)
H2O中的随机森林算法介绍及其项目实战(python实现) 包的引入:from h2o.estimators.random_forest import H2ORandomForestEstimator ...
随机推荐
- GoCN每日新闻(2019-09-29)
1. 干货满满的Go Modules和goproxy.cn https://juejin.im/post/5d8ee2db6fb9a04e0b0d9c8b 2. gnet: 一个轻量级且高性能的 Go ...
- CF1213F Unstable String Sort(差分)
其实全部可以为同一种字符串,但题目要求\(k\)种,我们考虑开始尽可能不同,最后再取\(min\) 考虑\(A\),全部不同:再做\(B\),\(S[b_{i-1}]\le S[b_{i}]\)如果开 ...
- namenode 优化 mv慢的问题
问题现象 问题描述 公司业务程序需求每30分钟mv 一万多个文件,如果三十分钟之内当前的文件内容没有全部移动,程序报错并且停止. 分析 通过分析,发现在启动balancer和不启动balancer的情 ...
- 浅谈python闭包及装饰器
1. 什么是闭包: 闭包 是指有权访问另一个函数作用域中变量的函数,创建闭包的最常见的方式就是在一个函数内创建另一个函数,通过另一个函数访问这个函数的局部变量,利用闭包可以突破作用链域,将函数内部的变 ...
- GAN 原理及公式推导
Generative Adversarial Network,就是大家耳熟能详的 GAN,由 Ian Goodfellow 首先提出,在这两年更是深度学习中最热门的东西,仿佛什么东西都能由 GAN 做 ...
- 怎么样在vue-cli的项目里面引入element ui
第一步:先进入到项目里面 npm i element-ui -S 第二步: import Vue from 'vue'; import ElementUI from 'element-ui'; //这 ...
- 团队作业-Alpha(1/4)
队名:软工9组 组长博客: https://www.cnblogs.com/cmlei/ 作业博客: 组员进度 ● 组员一(组长) 陈明磊 ○过去两天完成了哪些任务 ●文字/口头描述 初步学习flas ...
- 小福bbs-冲刺日志(第七天)
[小福bbs-冲刺日志(第七天)] 这个作业属于哪个课程 班级链接 这个作业要求在哪里 作业要求的链接 团队名称 小福bbs 这个作业的目标 目前完成静态 作业的正文 小福bbs-冲刺日志(第七天) ...
- 阿里druid连接池监控数据自定义存储
如何将druid连接池监控到的sql执行效率,连接池资源情况等进行持久化存储,方便系统运维分析优化,以下案例初步测试成功. 第一部: 新建MyDruidStatLogger类实现接口 extends ...
- 005 Spring和SpringBoot中的@Component 和@ComponentScan注解
今天在看@ComponentScan,感觉不是太理解,下面做一个说明. 1.说明 ComponentScan做的事情就是告诉Spring从哪里找到bean 2.细节说明 如果你的其他包都在使用了@Sp ...