七、spark核心数据集RDD
简介
spark RDD操作具体参考官网:http://spark.apache.org/docs/latest/rdd-programming-guide.html#overview
RDD全称叫做Resilient Distributed Datasets,直译为弹性分布式数据集,是spark中非常重要的概念。
首先RDD是一个数据的集合,这个数据集合被划分成了许多的数据分区,而这些分区被分布式地存储在不同的物理机器当中,如图:
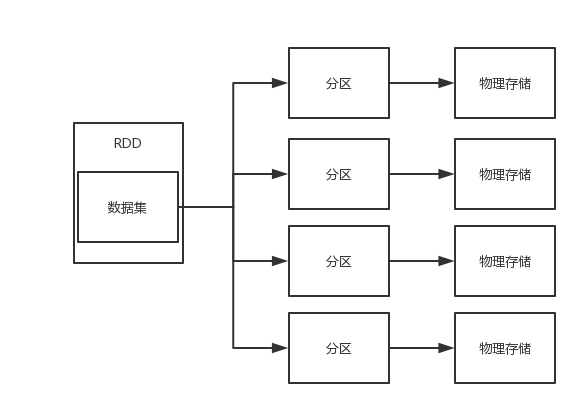
我们反过来想一下,RDD就是很多物理数据块的逻辑抽象。不仅如此,RDD还提供了一些列接口来操作这个逻辑抽象的数据集合。
我们把这些接口分成两大类:
1)transformation 转换
2)action 操作
transformation主要就是把一个RDD转换成另一个RDD,或者就是一开始把原始数据加载成为一个RDD;
注意:transformation并不会马上执行,只有等到action操作的时候才会执行。
action主要就是把一个RDD存储到硬盘,或者触发transformation的执行。
RDD转换和操作示例
我们先看一张图
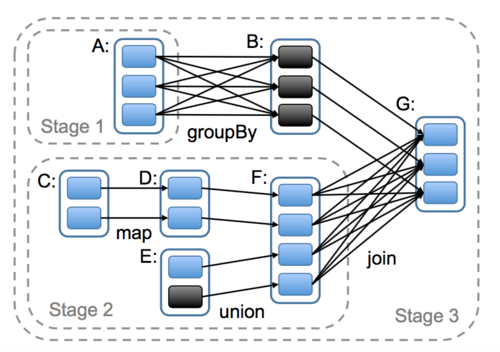
1)首先我们会从数据源中把数据加载成为RDD,也就是左边的RDDA和RDDC以及RDDE
2)RDDC经过map转换成为了RDDD
3)RDDE和RDDC经过union转换成为了RDDF
4)RDDA经过groupBy转换成为了RDDB
5)RDDB和RDDF经过join转换成为了RDDG
以上这些转换只是对整个过程进行一个描述,并没有立即执行,我们可以理解为对过程进行一个计划。直到我们调用一个saveAsSequenceFile持久化action操作的时候就会把上面的步骤催生出一个job,这个job根据是否shuffle(shuffle即宽依赖,下文提及)划分为了三个stage,并开始并行执行。
宽依赖和窄依赖
为了更加理解RDD,我们继续了解一下spark的核心原理
如图
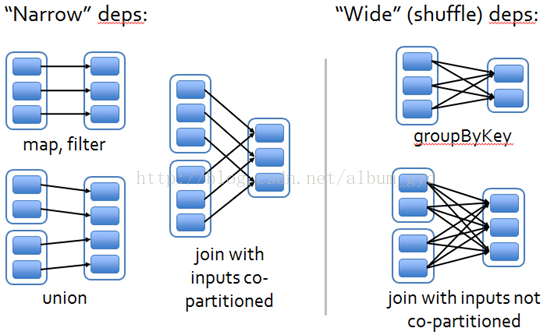
左边的部分是窄依赖,右边的部分是宽依赖即shuffle
上图的每一个蓝色块就是一个分区,而分区的集合就是一个RDD。同时RDD经过转换就会变成另一个RDD,那么也就会存在父子关系,由父RDD转换为子RDD。同时一个子RDD可能由多个父RDD转换而来。
那么,如果一个子RDD的每一个分区都只依赖于任意一个父RDD的其中一个分区,我们就认为它是窄依赖;
而,如果一个子RDD的任意一个分区都依赖于某一个父RDD的一个到多个的分区,我们就认为它是宽依赖。
我们的程序代码被解析成dag有向无环图以后,DagScheduler根据是否shuffle宽依赖来划分stage,每一个shuffle之前都是一个stage。
这么做的理由是这样划分的话,每一个stage的task都可以独立并行计算,而TaskScheduler也不用去了解stage的存在只需要知道task即可,然后TaskScheduler把task分发给WorkNode节点的executor去执行。
七、spark核心数据集RDD的更多相关文章
- Spark 核心概念 RDD 详解
RDD全称叫做弹性分布式数据集(Resilient Distributed Datasets),它是一种分布式的内存抽象,表示一个只读的记录分区的集合,它只能通过其他RDD转换而创建,为此,RDD支持 ...
- Spark 核心概念RDD
文章正文 RDD全称叫做弹性分布式数据集(Resilient Distributed Datasets),它是一种分布式的内存抽象,表示一个只读的记录分区的集合,它只能通过其他RDD转换而创建,为此, ...
- 深入理解Spark(一):Spark核心概念RDD
RDD全称叫做弹性分布式数据集(Resilient Distributed Datasets),它是一种分布式的内存抽象,表示一个只读的记录分区的集合,它只能通过其他RDD转换而创建,为此,RDD支持 ...
- Spark核心类:弹性分布式数据集RDD及其转换和操作pyspark.RDD
http://blog.csdn.net/pipisorry/article/details/53257188 弹性分布式数据集RDD(Resilient Distributed Dataset) 术 ...
- spark系列-2、Spark 核心数据结构:弹性分布式数据集 RDD
一.RDD(弹性分布式数据集) RDD 是 Spark 最核心的数据结构,RDD(Resilient Distributed Dataset)全称为弹性分布式数据集,是 Spark 对数据的核心抽象, ...
- Spark核心—RDD初探
本文目的 最近在使用Spark进行数据清理的相关工作,初次使用Spark时,遇到了一些挑(da)战(ken).感觉需要记录点什么,才对得起自己.下面的内容主要是关于Spark核心-RDD的相关 ...
- Spark弹性分布式数据集RDD
RDD(Resilient Distributed Dataset)是Spark的最基本抽象,是对分布式内存的抽象使用,实现了以操作本地集合的方式来操作分布式数据集的抽象实现.RDD是Spark最核心 ...
- 1.spark核心RDD特点
RDD(Resilient Distributed Dataset) Spark源码:https://github.com/apache/spark abstract class RDD[T: C ...
- Spark计算模型-RDD介绍
在Spark集群背后,有一个非常重要的分布式数据架构,即弹性分布式数据集(Resilient Distributed DataSet,RDD),它是逻辑集中的实体,在集群中的多台集群上进行数据分区.通 ...
随机推荐
- You can't specify target table 'e' for update in FROM clause
UPDATE emp e SET e.salary=e.salary+7 WHERE e.id IN(SELECT e1.id FROM emp e1,dept d WHERE e1.dep_id=d ...
- 《快学Scala》第五章 类
关于case class和普通class的区别,可以参考: https://www.iteblog.com/archives/1508.html
- 《快学Scala》第一章 基础
- jdk1.6 支持 tls1.2协议 并忽略身份验证
jdk1.6不支持tls1.2协议,jdk1.8默认支持,比较好的解决方案是升级jdk,但是升级jdk风险极大.不能升级jdk的情况下,可以使用如下方式. 引入依赖 <dependency> ...
- php-fpm epoll封装
参考 http://www.jianshu.com/p/dac223d7d9ad 事件对象结构 //fpm_event.h struct fpm_event_s { int fd; /* IO 文件句 ...
- Java多线程——volatile关键字、发布和逸出
1.volatile关键字 Java语言提供了一种稍弱的同步机制,即volatile变量.被volatile关键字修饰的变量不会被缓存在寄存器或者对其他处理器不可见的地方,因此在每次读取volatit ...
- maven web不能创建src/main/java等文件等问题
我们在创建maven web项目的时候,默认只有src/main/resources这个source folder,我们按照maven结构添加src/main/java和src/test/java等s ...
- Polycarp Restores Permutation
http://codeforces.com/contest/1141/problem/C一开始没想法暴力的,next_permutation(),TLE 后来看了这篇https://blog.csdn ...
- c# timer使用
C#里现在有3个Timer类: System.Windows.Forms.Timer System.Threading.Timer System.Timers.Timer 这三个Timer我想大家对S ...
- 数学还勉强管用,用代码还能画个canvas 仪表盘(含完整代码)
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...