Spark RDD概念学习系列之RDD的容错机制(十七)
RDD的容错机制
RDD实现了基于Lineage的容错机制。RDD的转换关系,构成了compute chain,可以把这个compute chain认为是RDD之间演化的Lineage。在部分计算结果丢失时,只需要根据这个Lineage重算即可。
图1中,假如RDD2所在的计算作业先计算的话,那么计算完成后RDD1的结果就会被缓存起来。缓存起来的结果会被后续的计算使用。图中的示意是说RDD1的Partition2缓存丢失。如果现在计算RDD3所在的作业,那么它所依赖的Partition0、1、3和4的缓存都是可以使用的,无须再次计算。但是Partition2由于缓存丢失,需要从头开始计算,Spark会从RDD0的Partition2开始,重新开始计算。
内部实现上,DAG被Spark划分为不同的Stage,Stage之间的依赖关系可以认为就是Lineage。关于DAG的划分可以参阅第4章。
提到Lineage的容错机制,不得不提Tachyon。Tachyon包含两个维度的容错,一个是Tachyon集群的元数据的容错,它采用了类似于HDFS的Name Node的元数据容错机制,即将元数据保存到一个Image文件,并且保存了元数据变化的编辑日志(EditLog)。另外一个是Tachyon保存的数据的容错机制,这个机制类似于RDD的Lineage,Tachyon会保留生成文件数据的Lineage,在数据丢失时会通过这个Lineage来恢复数据。如果是Spark的数据,那么在数据丢失时Tachyon会启动Spark的Job来重算这部分内容。如果是Hadoop产生的数据,那么重新启动相应的Map Reduce Job就可以。现在Tachyon的容错机制的实现还处于开发阶段,并不推荐将这个机制应用于生产环境。不过,这并不影响Spark使用Tachyon。如果Spark保存到Tachyon的部分数据丢失,那么Spark会根据自有的容错机制来重算这部分数据。
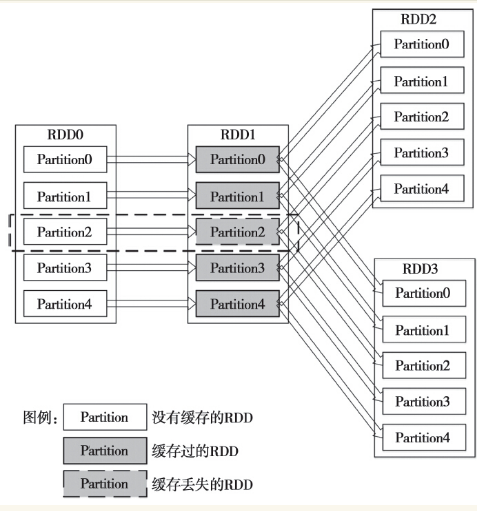
图1 RDD的部分缓存丢失的逻辑图
Spark RDD概念学习系列之RDD的容错机制(十七)的更多相关文章
- Spark RDD概念学习系列之RDD的缓存(八)
RDD的缓存 RDD的缓存和RDD的checkpoint的区别 缓存是在计算结束后,直接将计算结果通过用户定义的存储级别(存储级别定义了缓存存储的介质,现在支持内存.本地文件系统和Tachyon) ...
- Spark RDD概念学习系列之RDD的缺点(二)
RDD的缺点? RDD是Spark最基本也是最根本的数据抽象,它具备像MapReduce等数据流模型的容错性,并且允许开发人员在大型集群上执行基于内存的计算. 为了有效地实现容错,(详细见ht ...
- Spark RDD概念学习系列之RDD的转换(十)
RDD的转换 Spark会根据用户提交的计算逻辑中的RDD的转换和动作来生成RDD之间的依赖关系,同时这个计算链也就生成了逻辑上的DAG.接下来以“Word Count”为例,详细描述这个DAG生成的 ...
- Spark RDD概念学习系列之RDD的checkpoint(九)
RDD的检查点 首先,要清楚.为什么spark要引入检查点机制?引入RDD的检查点? 答:如果缓存丢失了,则需要重新计算.如果计算特别复杂或者计算耗时特别多,那么缓存丢失对于整个Job的影响是不容 ...
- Spark RDD概念学习系列之RDD的操作(七)
RDD的操作 RDD支持两种操作:转换和动作. 1)转换,即从现有的数据集创建一个新的数据集. 2)动作,即在数据集上进行计算后,返回一个值给Driver程序. 例如,map就是一种转换,它将数据集每 ...
- Spark RDD概念学习系列之RDD是什么?(四)
RDD是什么? 通俗地理解,RDD可以被抽象地理解为一个大的数组(Array),但是这个数组是分布在集群上的.详细见 Spark的数据存储 Spark的核心数据模型是RDD,但RDD是个抽象类 ...
- Spark RDD概念学习系列之RDD的依赖关系(宽依赖和窄依赖)(三)
RDD的依赖关系? RDD和它依赖的parent RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency). 1)窄依赖指的是每 ...
- Spark RDD概念学习系列之rdd的依赖关系彻底解密(十九)
本期内容: 1.RDD依赖关系的本质内幕 2.依赖关系下的数据流视图 3.经典的RDD依赖关系解析 4.RDD依赖关系源码内幕 1.RDD依赖关系的本质内幕 由于RDD是粗粒度的操作数据集,每个Tra ...
- Spark RDD概念学习系列之RDD与DSM的异同分析(十三)
RDD是一种分布式的内存抽象,下表列出了RDD与分布式共享内存(Distributed Shared Memory,DSM)的对比. 在DSM系统[1]中,应用可以向全局地址空间的任意位置进行读写操作 ...
随机推荐
- 8位灰度图在LCD上显示
一.概述 1.灰度 灰度使用黑色调表示物体,即用黑色为基准色,不同的饱和度的黑色来显示图像.每个灰度对象都具有从 0%(白色)到灰度条100%(黑色)的亮度值. 使用黑白或灰度扫描仪生成的图像通常以灰 ...
- jquery , find the event handler,找到jquery中的event handler
找到 dispatch: function (e) { e = b.event.fix(e); var n, r, i, s, o, u = [], a = d.call(arguments), f ...
- SWFUpload 中文乱码问题
解决办法:两种: 第一种:把handlers.js的编码方式改为UTF-8(用记事本打开,选择编码格式为utr-8即可) 第二种:在有swfupload控件页面的page_load种加: Respon ...
- Struts2WebUtil
一个简单的实用工具类 package cn.jorcen.commons.util; import javax.servlet.http.HttpServletRequest; import org. ...
- java连接数据库时出现如下错误:
java.lang.ClassNotFoundException: com.mysql.jdbc.driver at org.apache.catalina.loader.WebappClassLoa ...
- Sql狗血的Bit类型赋值与取值
Bit 数据类型在 SQL Server 数据库中以存储 1.0 进行存储. 往数据库中添加,修改 bit 类型的字段时,只能用 0 或者 1. 关于修改 Bit 类型的字段 1.若使用 SQL 语句 ...
- *[codility]GenomicRangeQuery
http://codility.com/demo/take-sample-test/genomicrangequery 这题有点意思.一开始以为是RMQ或者线段树,但这样要O(n*logn).考虑到只 ...
- Delphi编写自定义控件以及接口的使用(做了一个TpgDbEdit)
写给觉得自己编写Delphi很复杂的人,包括自己. Delphi自己写控件其实并不难,难的在于开发复杂的控件.(其实,编程,很多东西都是会了就不难,因此,我怕自己日后觉得自己写控件很难,特意在这记录自 ...
- ruby oop学习
class Man def initialize(name,age) @name=name @age=age end def sayName puts @name end def sayAge put ...
- 函数page_cur_search_with_match
/****************************************************************//** Searches the right position fo ...