Spark RDD概念学习系列之RDD的操作(七)
RDD的操作
RDD支持两种操作:转换和动作。
1)转换,即从现有的数据集创建一个新的数据集。
2)动作,即在数据集上进行计算后,返回一个值给Driver程序。
例如,map就是一种转换,它将数据集每一个元素都传递给函数,并返回一个新的分布式数据集表示结果。另一个方面,reduce是一种动作,通过一些函数将所有元素叠加起来,并将最终结果返回Driver(还有一个并行的reduceByKey,能返回一个分布式数据集)。
下图描述了从外部数据源创建RDD,经过多次转换,通过一个动作操作将结果写回外部存储系统的逻辑运行图。整个过程的计算都是在Worker中的Executor中运行。

图 1 RDD的创建、转换和动作的逻辑计算图
RDD的转换
RDD中的所有转换都是惰性的,也就是说,它们并不会直接计算结果。相反的,它们只是记住这些应用到基础数据集(例如一个文件)上的转换动作。只有当发生一个要求返回结果给Driver的动作时,这些转换才会真正运行。这个设计让Spark更加有效率地运行。例如我们可以实现:通过map创建的一个新数据集,并在reduce中使用,最终只返回reduce的结果给Driver,而不是整个大的新数据集。图2描述了RDD在进行groupByRey时的内部RDD转换的实现逻辑图。图3描述了reduceByKey的实现逻辑图。

图2 RDD groupByKey的逻辑转换图
在groupByKey的操作中,会在MapPartitionsRDD做一次Shuffle,图2中设置的分片数量是3,因此ShuffledRDD会有3个分片,ShuffledRDD实际上仅仅是从上游的任务中读取Shuffle的结果,因此图的箭头是指向上游的MapPartitionsRDD的。关于Shuffle的实现实际上要比图中展示得复杂得多。reduceByKey和groupByKey的实现差不多,它在Shuffle完成之后,需要做一次reduce。
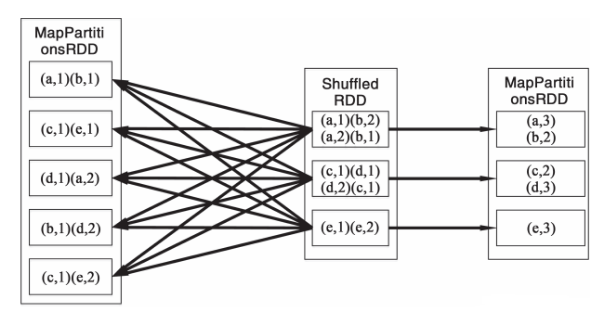
图3 RDD reduceByKey 的逻辑转换图
默认情况下,每一个转换过的RDD都会在它执行一个动作时被重新计算。不过也可以使用persist(或者cache)方法,在内存中持久化一个RDD。在这种情况下,Spark将会在集群中保存相关元素,下次查询这个RDD时能更快访问它。也支持在磁盘上持久化数据集,或在集群间复制数据集。
Spark RDD概念学习系列之RDD的操作(七)的更多相关文章
- Spark RDD概念学习系列之RDD的checkpoint(九)
RDD的检查点 首先,要清楚.为什么spark要引入检查点机制?引入RDD的检查点? 答:如果缓存丢失了,则需要重新计算.如果计算特别复杂或者计算耗时特别多,那么缓存丢失对于整个Job的影响是不容 ...
- Spark RDD概念学习系列之RDD的缓存(八)
RDD的缓存 RDD的缓存和RDD的checkpoint的区别 缓存是在计算结束后,直接将计算结果通过用户定义的存储级别(存储级别定义了缓存存储的介质,现在支持内存.本地文件系统和Tachyon) ...
- Spark RDD概念学习系列之RDD是什么?(四)
RDD是什么? 通俗地理解,RDD可以被抽象地理解为一个大的数组(Array),但是这个数组是分布在集群上的.详细见 Spark的数据存储 Spark的核心数据模型是RDD,但RDD是个抽象类 ...
- Spark RDD概念学习系列之RDD的依赖关系(宽依赖和窄依赖)(三)
RDD的依赖关系? RDD和它依赖的parent RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency). 1)窄依赖指的是每 ...
- Spark RDD概念学习系列之RDD的缺点(二)
RDD的缺点? RDD是Spark最基本也是最根本的数据抽象,它具备像MapReduce等数据流模型的容错性,并且允许开发人员在大型集群上执行基于内存的计算. 为了有效地实现容错,(详细见ht ...
- Spark RDD概念学习系列之RDD与DSM的异同分析(十三)
RDD是一种分布式的内存抽象,下表列出了RDD与分布式共享内存(Distributed Shared Memory,DSM)的对比. 在DSM系统[1]中,应用可以向全局地址空间的任意位置进行读写操作 ...
- Spark RDD概念学习系列之rdd的依赖关系彻底解密(十九)
本期内容: 1.RDD依赖关系的本质内幕 2.依赖关系下的数据流视图 3.经典的RDD依赖关系解析 4.RDD依赖关系源码内幕 1.RDD依赖关系的本质内幕 由于RDD是粗粒度的操作数据集,每个Tra ...
- Spark RDD概念学习系列之RDD的转换(十)
RDD的转换 Spark会根据用户提交的计算逻辑中的RDD的转换和动作来生成RDD之间的依赖关系,同时这个计算链也就生成了逻辑上的DAG.接下来以“Word Count”为例,详细描述这个DAG生成的 ...
- Spark RDD概念学习系列之RDD的创建(六)
RDD的创建 两种方式来创建RDD: 1)由一个已经存在的Scala集合创建 2)由外部存储系统的数据集创建,包括本地文件系统,还有所有Hadoop支持的数据集,比如HDFS.Cassandra.H ...
随机推荐
- poj1860Currency Exchange(bell_fordmoban)
http://poj.org/problem?id=1860 模板提 #include <iostream> #include<cstdio> #include<cstr ...
- 【转+分析】JAVA: 为什么要使用"抽象类"? 使用"抽象类"有什么好处?
老是在想为什么要引用抽象类,一般类不就够用了吗.一般类里定义的方法,子类也可以覆盖,没必要定义成抽象的啊. 看了下面的文章,明白了一点. 其实不是说抽象类有什么用,一般类确实也能满足应用,但是现实中确 ...
- Qt之等待提示框(QTimer)
简述 上节讲述了关于QPropertyAnimation实现等待提示框的显示,本节我们使用另外一种方案来实现-使用定时器QTimer,通过设置超时时间定时更新图标达到旋转效果. 简述 效果 资源 源码 ...
- UVa 11481 (计数) Arrange the Numbers
居然没有往错排公式那去想,真是太弱了. 先在前m个数中挑出k个位置不变的数,有C(m, k)种方案,然后枚举后面n-m个位置不变的数的个数i,剩下的n-k-i个数就是错排了. 所以这里要递推一个组合数 ...
- HDU 3544 (不平等博弈) Alice's Game
切巧克力的游戏,想得还是不是太明白. 后者会尽量选前着切后其中小的一块来切,那么先手须尽量取中间来切. So?题解都是这么一句话,不知道是真懂了还是从别人那抄过来的. 后来找到一个官方题解,分析得比较 ...
- UVa 10859 Placing Lampposts
这种深层递归的题还是要多多体会,只看一遍是不够的 题意:有一个森林,在若干个节点处放一盏灯,灯能照亮与节点邻接的边.要求:符合要求的放置的灯最少为多少,在灯数最少的前提下,一条边同时被两盏灯照亮的边数 ...
- 20160123.CCPP详解体系(0002天)
程序片段(01):字符.c 内容概要: 转义字符 #define _CRT_SECURE_NO_WARNINGS #include <stdlib.h> #include <stdi ...
- 【英语】Bingo口语笔记(9) - 表示“不相信”
- JAVA虚拟机内存分配与回收机制
Java虚拟机(Java Virtual Machine) 简称JVM Java虚拟机是一个想象中的机器,在实际的计算机上通过软件模拟来实现.Java虚拟机有自己想象中的硬件,如处理器.堆栈.寄存器等 ...
- Linux/Unix shell 监控Oracle实例(monitor instance)
使用shell脚本实现对Oracle数据库的监控与管理将大大简化DBA的工作负担,如常见的对实例的监控,监听的监控,告警日志的监控,以及数据库的备份,AWR report的自动邮件等.本文给出Linu ...