050 sqoop的使用
一:导入 mysql--》hdfs
1.准备
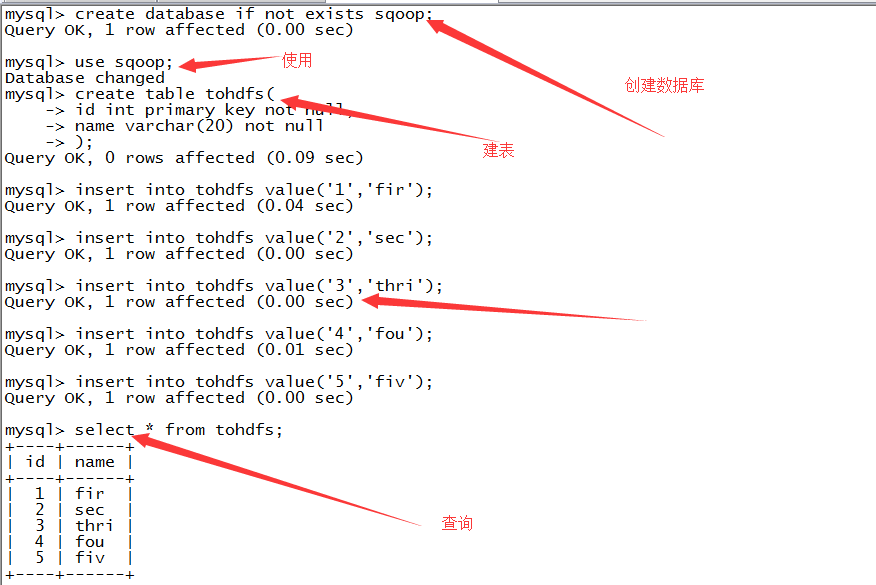
2.导入数据
可以看到在跑yarn。

3.在HDFS上看结果
默认的地址:hdfs的家目录。
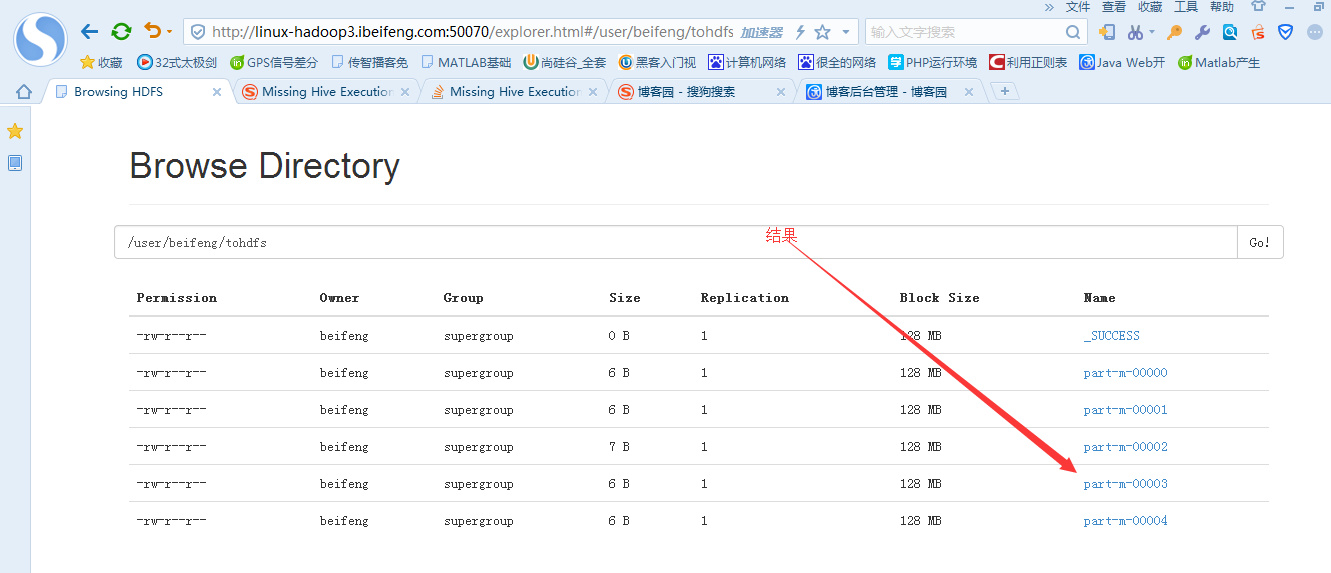
4.在HDFS上指定目录

5.指定map的个数,相同目录时,先删除原来的目录
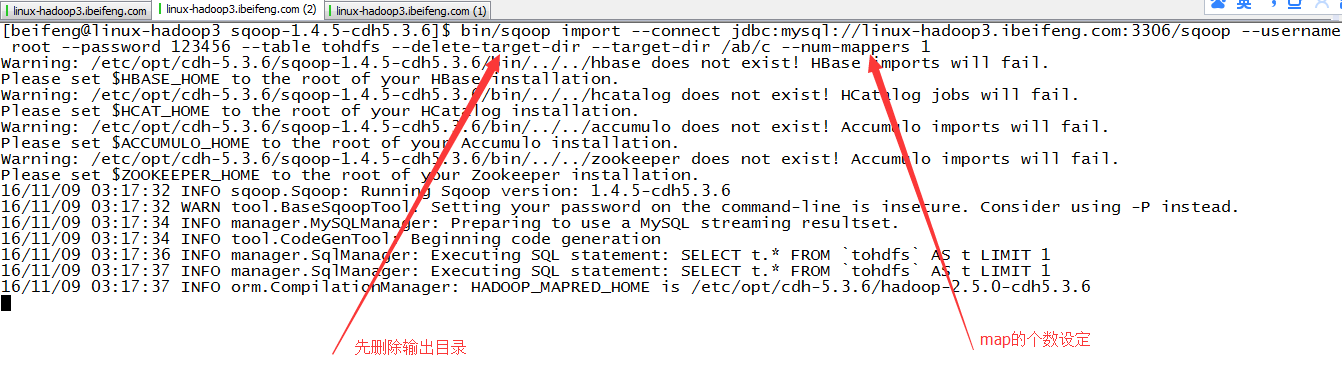
6.查看结果

7.指定分隔符
默认是‘,’,在HDFS上修改‘\t’

8.重新查看结果

9.更快的方式

10.增量导入之前的准备

11.增量导入
在增量导入的时候,不能加上--delete---target-dir,因为这是增量导入

12.查看增量结果

二:job实现增量导入(属于Mysql导入Hdfs)
1.创建一个job任务之前的任务

2.创建一个job任务
注意:命令为 --create
--与import之间有一个空格。

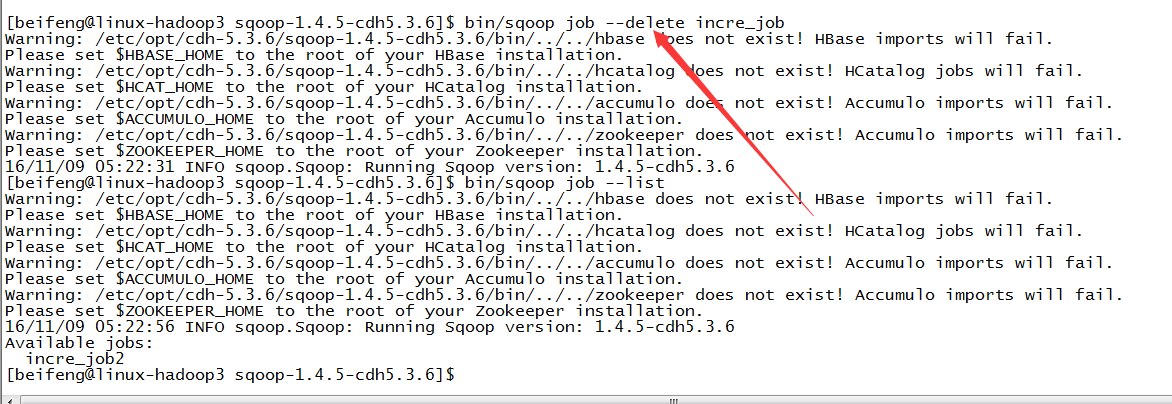
3.查看一个job

4.查看job的详细信息

5.执行job任务

6.删除job任务
二:导入 mysql-->hive
1.在HIVE中新建一个数据库和一个表
方便mysql里面的数据导入。

2.展示源表tohdfs的数据

3.导入一

4.结果

5.导入二
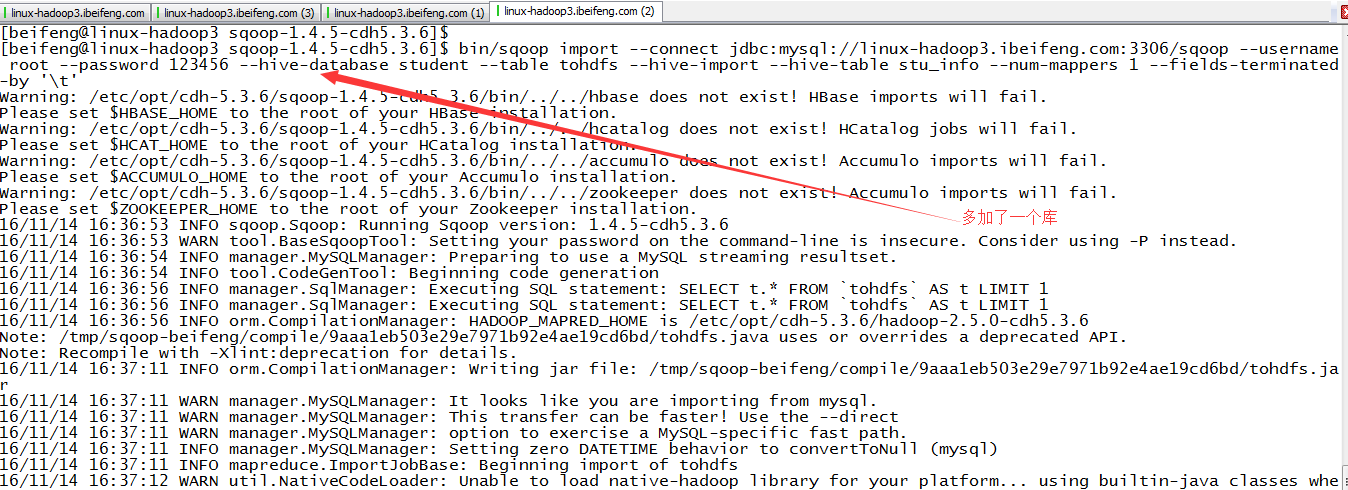
6.结果

三:导出:hdfs-》mysql
1.新建mysql数据表
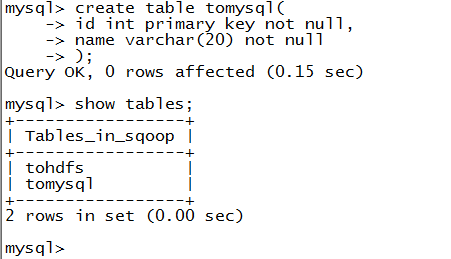
2.命令
bin/sqoop export --connect jdbc:mysql://linux-hadoop3.ibeifeng.com:3306/sqoop --username root --password 123456 --table tomysql --export-dir /user/hive/warehouse/student.db/stu_info --num-mappers 1 --input-fields-terminated-by '\t'

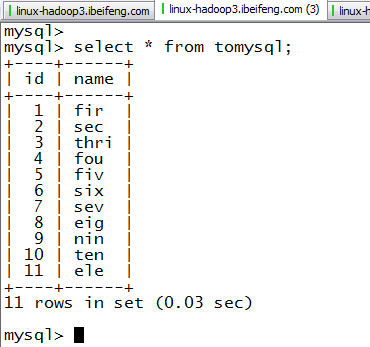
3.结果
四:导出hive-》mysql
1.基本语法同上。
只需要把--export-dir改成HIVE的路径就可以了。
但是会发现,上面的HDFS上的路径就是HIVE的路径,所以HIVE的导出例子依旧可以使用上面的例子。
在HDFS的导出中,可以使用HDFS上的任何一个路径,而不是HIVE中需要时warehouse的路径。
五:执行sqoolwenjian
1.新建数据库

2.新建sqoop.file,里面是将执行的文件
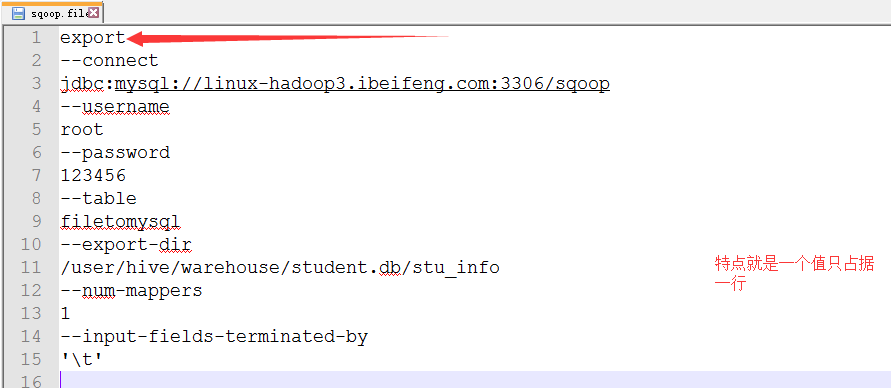
3.执行
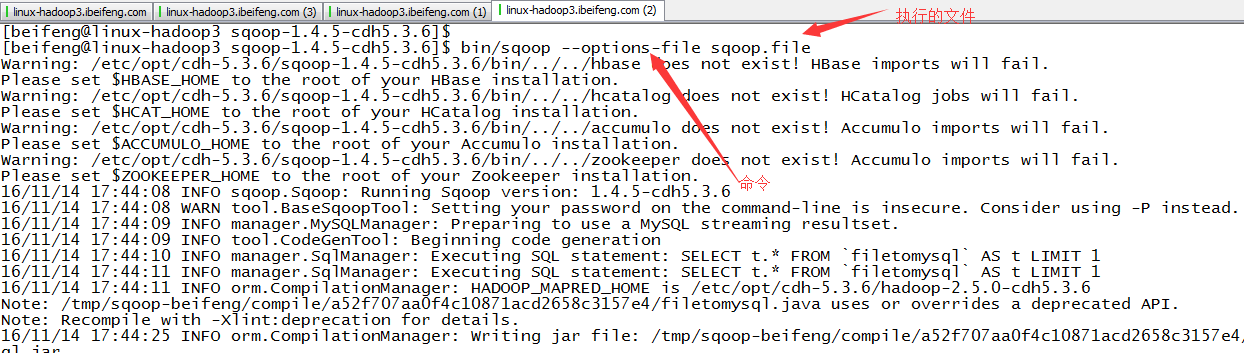
4.结果

六:使用帮助
1.用法

050 sqoop的使用的更多相关文章
- sqoop:Failed to download file from http://hdp01:8080/resources//oracle-jdbc-driver.jar due to HTTP error: HTTP Error 404: Not Found
环境:ambari2.3,centos7,sqoop1.4.6 问题描述:通过ambari安装了sqoop,又添加了oracle驱动配置,如下: 保存配置后,重启sqoop报错:http://hdp0 ...
- 安装sqoop
安装sqoop 1.默认已经安装好java+hadoop 2.下载对应hadoop版本的sqoop版本 3.解压安装包 tar zxvf sqoop-1.4.6.bin__hadoop-2.0.4-a ...
- Hadoop学习笔记—18.Sqoop框架学习
一.Sqoop基础:连接关系型数据库与Hadoop的桥梁 1.1 Sqoop的基本概念 Hadoop正成为企业用于大数据分析的最热门选择,但想将你的数据移植过去并不容易.Apache Sqoop正在加 ...
- Oozie分布式任务的工作流——Sqoop篇
Sqoop的使用应该是Oozie里面最常用的了,因为很多BI数据分析都是基于业务数据库来做的,因此需要把mysql或者oracle的数据导入到hdfs中再利用mapreduce或者spark进行ETL ...
- [大数据之Sqoop] —— Sqoop初探
Sqoop是一款用于把关系型数据库中的数据导入到hdfs中或者hive中的工具,当然也支持把数据从hdfs或者hive导入到关系型数据库中. Sqoop也是基于Mapreduce来做的数据导入. 关于 ...
- [大数据之Sqoop] —— 什么是Sqoop?
介绍 sqoop是一款用于hadoop和关系型数据库之间数据导入导出的工具.你可以通过sqoop把数据从数据库(比如mysql,oracle)导入到hdfs中:也可以把数据从hdfs中导出到关系型数据 ...
- Sqoop切分数据的思想概况
Sqoop通过--split-by指定切分的字段,--m设置mapper的数量.通过这两个参数分解生成m个where子句,进行分段查询.因此sqoop的split可以理解为where子句的切分. 第一 ...
- sqoop数据导出导入命令
1. 将mysql中的数据导入到hive中 sqoop import --connect jdbc:mysql://localhost:3306/sqoop --direct --username r ...
- Apache Sqoop - Overview——Sqoop 概述
Apache Sqoop - Overview Apache Sqoop 概述 使用Hadoop来分析和处理数据需要将数据加载到集群中并且将它和企业生产数据库中的其他数据进行结合处理.从生产系统加载大 ...
随机推荐
- 目标提取深度神经网络分析权衡 trade offs
RCNN: 直接使用object proposal 方法得到image crops 送入神经网络中,但是crops 的大小不一样,因此使用 ROI Pooling,这个网络层可以把不同大小的输入映射到 ...
- js 布局转换问题
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- Postfix 邮件服务 - PostfixAdmin
PostfixAdmin 基于web的postfix邮件发送服务器的管理工具,可以直接管理postfix的虚拟域名和邮件用户,前提是这些数据是存储在mysql或者是PostgreSQL数据库中. Po ...
- Linux - 账户切换授权
sudo 切换账户 echo myPassword | sudo -S ls /tmp # 直接输入sudo的密码非交互,从标准输入读取密码而不是终端设备 visudo # sudo命令权限添加 /e ...
- 拆分窗口QSplitter
拆分窗口中可以添加许多子控件,各个子控件通过拆分线相互分隔开来,拖动该拆分线可以随意改变子控件大小 import sys from PyQt5.QtCore import Qt from PyQt5. ...
- luogu P3522 [POI2011]TEM-Temperature
这道题暴力做法就是枚举每个起点,然后向后拓展到不能拓展 就像这样(红框是每个位置的取值范围,绿线是你取的值构成的折线) 应该可以发现,左端点往右移的过程中,右端点也只能不动或往右移,所以我们可以每次移 ...
- 《像计算机科学家一样思考Python》-递归
斐波那契数列 使用递归定义的最常见数学函数是 fibonacci (斐波那契数列),见其 定义 fibonacci(0) = 0 fibonacci(1) = 1 fibonacci(n) = fib ...
- Python中的exec、eval使用实例
Python中的exec.eval使用实例 这篇文章主要介绍了Python中的exec.eval使用实例,本文以简洁的方式总结了Python中的exec.eval作用,并给出实例,需要的朋友可以参考下 ...
- 关于出现Not an editor command: Bundle '**/*.vim'的解决方案【转】
转自:https://blog.csdn.net/YHM07/article/details/49717933 操作系统: $ uname -r 2.6.32-573.7.1.el6.x86_64 $ ...
- ulimit -n 修改
Linux系统里打开文件描述符的最大值,一般缺省值是1024,对一台繁忙的服务器来说,这个值偏小,所以有必要重新设置linux系统里打开文件描述符的最大值.那么应该在哪里设置呢? [root@loca ...