TensorFlow 核心——数据流图
1 计算模型 —— 计算图(Graph)
更多参考:数据流图
TensorFlow 中的所有计算都会被转化为计算图上的节点。TensorFlow 是一个通过计算图的形式来表述计算的编程系统。TensorFlow中的每个计算都是计算图的一个节点,而节点之间的边描述了计算之间的依赖关系。
import sys
sys.path.append('E:/zlab/')
from plotnet import draw_feed_forward, DynamicShow
TensorFlow 的计算模型是有向图,采用数据流图 (Data Flow Graphs),其中每个节点代表一些函数或计算,而边代表了数值、矩阵或张量。
数据流图
数据流图是用于定义计算结构的。在 TensorFlow 中,数据流图本质上是一组链接在一起的函数,每个函数都会将其输出传递给 \(0\) 个、\(1\) 个或多个位于这个级联链上的其他函数。
with DynamicShow((6, 3), '计算图.png') as d: # 隐藏坐标轴
seq_list = draw_feed_forward(d.ax, num_node_list=[2, 1, 1])
seq_list[0][0].text('$1$')
seq_list[0][1].text('$2$')
seq_list[1][0].text('$+$')
seq_list[2][0].text('$3$')
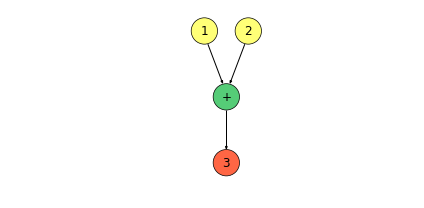
如上图,我们使用数据流图表示了 \(1 + 2 = 3\) 这一个运算。
我们也可以将其抽象化:
with DynamicShow((6, 3), '计算图1.png') as d: # 隐藏坐标轴
seq_list = draw_feed_forward(d.ax, num_node_list=[2, 1, 1])
seq_list[0][0].text('$a$')
seq_list[0][1].text('$b$')
seq_list[1][0].text('$c$')
seq_list[2][0].text('$d$')

我们也可以将上述过程简化为:
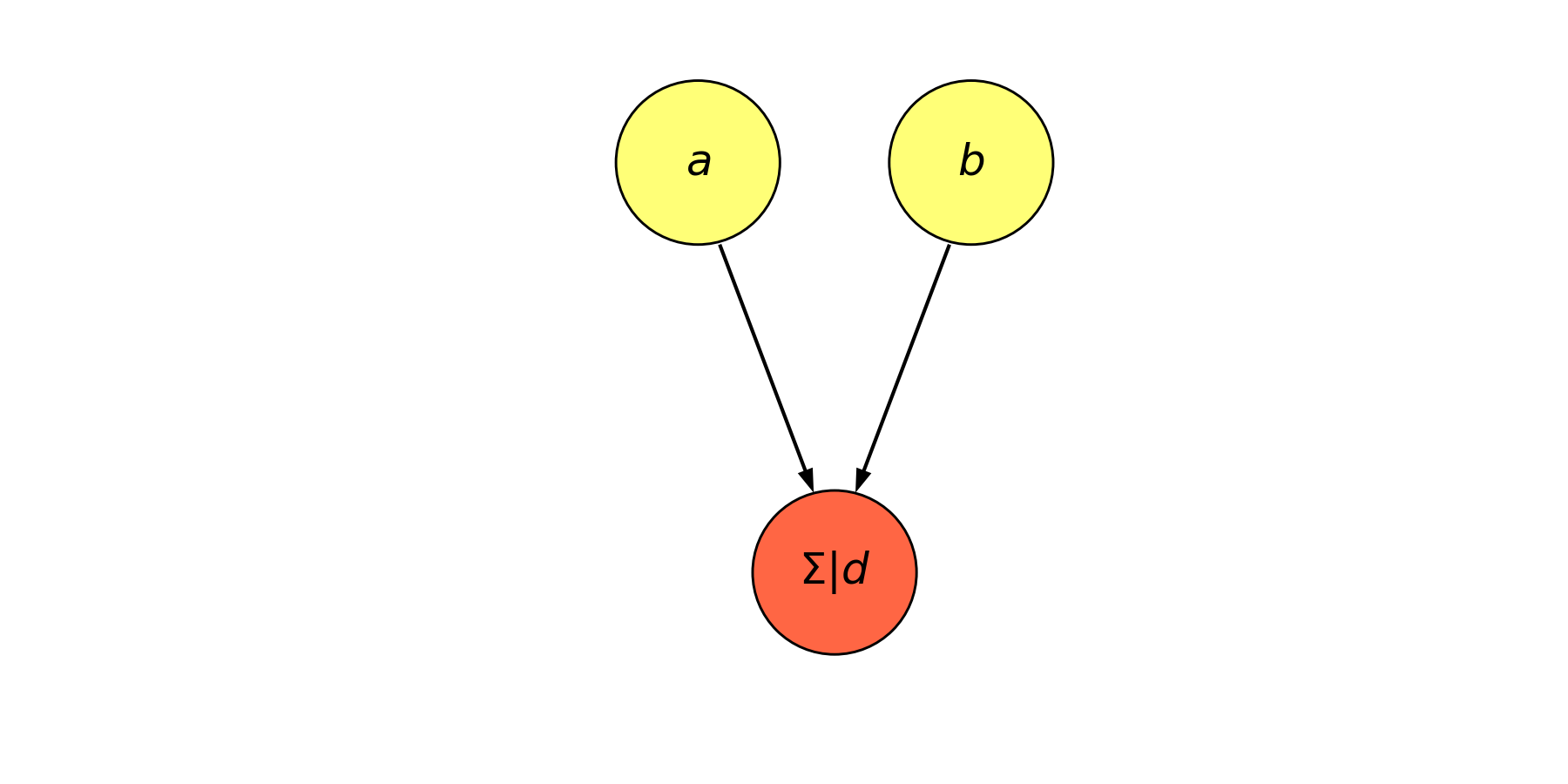
将节点 \(c\) 与 \(d\) 合并,若 \(c\) 表示求和运算,\(d\) 表示非线性变换,则上图可以看作是一个神经元。
除了节点和边的概念,数据流图还有一个十分关键的概念:依赖关系。

我们一般地,像 \(z_0^{(0)}\) 与 \(z_0^{(1)}\) 直接连接,称为直接依赖,而像 \(z_0^{(0)}\) 与 \(z_0^{(2)}\),称为间接依赖。即 \(z_0^{(1)}\) 直接依赖于 \(z_0^{(0)}\) 和 \(z_1^{(0)}\),而 \(z_0^{(2)}\) 间接依赖依赖于 \(z_0^{(0)}\) 和 \(z_1^{(0)}\)。

1.1 计算图的使用
- 定义计算图的所有节点;
- 执行计算。
1.1.1 使用默认图
在TensorFlow程序中,系统会自动维护一个默认的计算图,通过tf.get_default_graph()函数可以获取当前默认的计算图。
通过a.graph可以查看张量所属的计算图。
import tensorflow as tf
a = tf.constant([1., 2.], name = 'a')
b = tf.constant([2., 3.], name = 'b')
result = a + b
a.graph is tf.get_default_graph()
True
1.1.2 tf.Graph函数可以生成新的计算图
不同计算图上的张量和运算均不会共享。
g1 = tf.Graph()
with g1.as_default():
# 在计算图 g1 中定义变量 “v” ,并设置初始值为 0。
v = tf.get_variable("v", [1], initializer = tf.zeros_initializer()) # 设置初始值为0,shape 为 1
g2 = tf.Graph()
with g2.as_default():
# 在计算图 g2 中定义变量 “v” ,并设置初始值为 1。
v = tf.get_variable("v", [1], initializer = tf.ones_initializer()) # 设置初始值为1
# 在计算图 g1 中读取变量“v” 的取值
with tf.Session(graph = g1) as sess:
tf.global_variables_initializer().run()
with tf.variable_scope("", reuse=True):
print(sess.run(tf.get_variable("v")))
# 在计算图 g2 中读取变量“v” 的取值
with tf.Session(graph = g2) as sess:
tf.global_variables_initializer().run()
with tf.variable_scope("", reuse=True):
print(sess.run(tf.get_variable("v")))
[ 0.]
[ 1.]
TensorFlow的计算图不仅仅可以用来隔离张量和计算,它还提供了管理张量和计算的机制。
计算图可以通过 tf.Graph.device函数来指定运行计算的设备。
g = tf.Graph()
# 指定计算运行的设备
with g.device('/gpu:0'):
result = a + b
有效整理TensorFlow 程序的资源也是计算图的一个重要功能。
在一个计算图中,可以通过集合(collection)来管理不同类别的资源。比如通过tf.add_to_collection函数可以将资源加入一个
或多个集合中,然后通过tf.get_collection获取一个集合里面的所有资源(如张量,变量,或者运行TensorFlow程序所需的队列资源等等)
TensorFlow中维护的集合列表
| 集合名称 | 集合内容 | 使用场景 |
|---|---|---|
tf.GraphKeys.VARIABLES |
所有变量 | 持久化TensorFlow模型 |
tf.GraphKeys.TRAINABLE_VARIABLES |
可学习的变量(一般指神经网络中的参数) | 模型训练、生成模型可视化内容 |
tf.GraphKeys.SUMMARIES |
日志生成相关的张量 | TensorFlow计算可视化 |
tf.GraphKeys.QUEUE_RUNNERS |
处理输入的QueueRunner | 输入处理 |
tf.GraphKeys.MOVING_AVERAGE_VARIABLES |
所有计算了滑动平均值的变量 | 计算变量的滑动平均值 |
2 数据模型——张量(Tensor)
在TensorFlow程序中,所有的数据都是通过张量的形式来表示的。
从功能角度来看张量可理解为多维数组。但是张量在TensorFlow的实现并不是直接采用数组的形式,它只是对TensorFlow中运算结果的引用。在张量中并没有真正保存数字,它保存的是如何得到这些数字的计算过程。
import tensorflow as tf
# tf.constant 是一个计算,这个计算的结果为一个张量,保存在变量 a 中
a = tf.constant([1., 2.], name = 'a')
b = tf.constant([3., 4.], name = 'b')
result = tf.add(a, b, name = 'add')
print(result)
Tensor("add_3:0", shape=(2,), dtype=float32)
张量的属性值主要有三个:名字(name)、维度(shape)和类型(type)
name
- 张量的唯一标识符;
- 给出了张量是如何计算出来的。
张量和计算图上的每一个节点所有代表的结果是对应的。张量的命名:node:src_output。
其中node为节点的名称,src_output表示当前张量来自节点的第几个输出。
type
每一个张量会有一个唯一的类型。
import tensorflow as tf
a = tf.constant([1, 2], name = 'a', dtype = tf.float32)
b = tf.constant([3., 4.], name = 'b')
result = tf.add(a, b, name = 'add')
print(result)
Tensor("add_4:0", shape=(2,), dtype=float32)
TensorFlow支持14种类型:
实数(tf.float32, tf.float64)、整数(tf.int8, tf.int16, tf.int32, tf.int64, tf.uint8)、布尔型(tf.bool)、复数(tf.complex64, tf.complex128)。
张量的用途
对中间结果的引用,提高代码可读性。
# 使用张量记录中间结果
a = tf.constant([1, 2], name = 'a', dtype = tf.float32)
b = tf.constant([3., 4.], name = 'b')
result = a + b
# 直接计算向量的和,这样可读性很差
result = tf.constant([1., 2.], name = 'a') + tf.constant([3., 4.], name = 'b')
<tf.Tensor 'add_5:0' shape=(2,) dtype=float32>
result.get_shape() # 获取张量的维度信息
TensorShape([Dimension(2)])
当计算图构造完成后,张量可用来获取计算结果。
通过run计算结果;
或者在会话(Session())中运行。
3 运行模型——会话(Session)
执行已经定义好的运算。
会话拥有并管理TensorFlow程序运行时的所有资源。当所有计算完成后需要关闭会话来帮助系统回收资源,否则会出现资源泄露现象。
模式一
# 创建一个会话
sess = tf.Session()
# 使用这个创建好的会话得到关心的运算结果
sess.run(result)
# 关闭会话
sess.close()
模式二:通过Python上下文管理机制
with tf.Session() as sess:
sess.run(result)
# 当上下文退出时会话关闭和资源可以被释放。
指定默认会话(默认会话不会自动生成),通过 tf.Tensor.eval 函数计算张量取值。
sess = tf.Session()
with sess.as_default():
print(result.eval())
[ 4. 6.]
以下代码实现相同的功能:
sess = tf.Session()
# 下面的两个命令有相同的功能
print(sess.run(result))
print(result.eval(session = sess))
[ 4. 6.]
[ 4. 6.]
使用tf.InteractiveSession构建会话
在交互的环境下(如Jupyter Notebook)可以直接构建默认会话,即使用tf.InteractiveSession函数(此函数会自动将生成的会话注册为默认会话)。
sess = tf.InteractiveSession()
print(result.eval())
sess.close()
[ 4. 6.]
通过ConfigProto配置会话
config=tf.ConfigProto(allow_soft_placement=True, log_device_placement=True)
sess1 = tf.InteractiveSession(config=config)
sess2 = tf.Session(config=config)
allow_soft_placement=True 在下面的任意一个条件成立,GPU的运算可以放到CPU上进行:
- 运算无法在GPU上执行;
- 没有GPU资源(比如运算被指定在第二个GPU上运行,但是机器只有一个GPU);
- 运算输入包含对CPU计算结果的引用。
log_device_placement=True日志中将会记录每个节点被安排在了哪个设备上以方便调试。
TensorFlow 核心——数据流图的更多相关文章
- tensorflow核心概念和原理介绍
关于 TensorFlow TensorFlow 是一个采用数据流图(data flow graphs),用于数值计算的开源软件库. 节点(Nodes)在图中表示数学操作,图中的线(edges)则表示 ...
- (转)自动微分(Automatic Differentiation)简介——tensorflow核心原理
现代深度学习系统中(比如MXNet, TensorFlow等)都用到了一种技术——自动微分.在此之前,机器学习社区中很少发挥这个利器,一般都是用Backpropagation进行梯度求解,然后进行SG ...
- 学习笔记TF048:TensorFlow 系统架构、设计理念、编程模型、API、作用域、批标准化、神经元函数优化
系统架构.自底向上,设备层.网络层.数据操作层.图计算层.API层.应用层.核心层,设备层.网络层.数据操作层.图计算层.最下层是网络通信层和设备管理层.网络通信层包括gRPC(google Remo ...
- TensorFlow 基础知识
参考资料: 深度学习笔记目录 向机器智能的TensorFlow实践 TensorFlow机器学习实战指南 Nick的博客 TensorFlow 采用数据流图进行数值计算.节点代表计算图中的数学操作,计 ...
- AI繁荣下的隐忧——Google Tensorflow安全风险剖析
本文由云+社区发表 作者:[ Tencent Blade Team ] Cradmin 我们身处一个巨变的时代,各种新技术层出不穷,人工智能作为一个诞生于上世纪50年代的概念,近两年出现井喷式发展,得 ...
- 《TensorFlow实战》读书笔记(完结)
1 TensorFlow基础 ---1.1TensorFlow概要 TensorFlow使用数据流图进行计算,一次编写,各处运行. ---1.2 TensorFlow编程模型简介 TensorFlow ...
- TensorFlow架构与设计:概述
TensorFlow是什么? TensorFlow基于数据流图,用于大规模分布式数值计算的开源框架.节点表示某种抽象的计算,边表示节点之间相互联系的张量. TensorFlow支持各种异构的平台,支持 ...
- Tensorflow 初级教程(一)
初步介绍 Google 于2011年推出人工深度学习系统——DistBelief.通过DistBelief,Google能够扫描数据中心数以千计的核心,并建立更大的神经网络.Google 的这个系统将 ...
- 机器学习资源汇总----来自于tensorflow中文社区
新手入门完整教程进阶指南 API中文手册精华文章TF社区 INTRODUCTION 1. 新手入门 1.1. 介绍 1.2. 下载及安装 1.3. 基本用法 2. 完整教程 2.1. 总览 2.2. ...
随机推荐
- js 执行上下文理解
前端基础进阶(三):变量对象详解http://www.jianshu.com/p/330b1505e41d 1.创建阶段 a.生成变量对象 1.创建arguments对象 2.functio ...
- Java注解之Retention、Documented、Target、Inherited介绍
先看代码,后面一个个来解析: @Retention(RetentionPolicy.RUNTIME) @Target(value = {ElementType.METHOD, ElementType. ...
- UML入门[转]
访问权限控制 class Dummy { - private field1 # protected field2 ~ package method1() + public method2() } Al ...
- Dubbo服务降级
当服务器压力剧增的情况下,根据实际业务情况及流量,对一些服务和页面有策略的不处理或简单处理,从而释放服务器资源以保证核心业务正常运作或高效运作. 可以通过服务降级功能临时屏蔽某个出错的非关键服务并定义 ...
- ProcessHacker可编译版本
说明 做一个批量进程内搜索字符串的工具. 试了processhacker-2.39-src.zip. https://sourceforge.net/projects/processhacker/fi ...
- string替换字符串,路径的斜杠替换为下划线
场景 替换某个路径的所有"\"为"_". 很多时候取证需要把恶意代码文件取回来,然后清除. 如果在D:\WEB\模板制作插件\需要覆盖\CodeColoring ...
- PP图和QQ图
一. QQ图 分位数图示法(Quantile Quantile Plot,简称 Q-Q 图) 统计学里Q-Q图(Q代表分位数)是一个概率图,用图形的方式比较两个概率分布,把他们 ...
- caffe中 softmax 函数的前向传播和反向传播
1.前向传播: template <typename Dtype> void SoftmaxLayer<Dtype>::Forward_cpu(const vector< ...
- dump_stack的简单使用 【转】
转自:http://blog.chinaunix.net/uid-26403844-id-3361770.html http://blog.csdn.net/ryfjx6/article/detail ...
- java工程添加类库
在属性中添加自定义类库 在工程中引入自定义类库